Chapter 5 Datenanalyse
In diesem Kapitel stelle ich euch die grundlegenden Ideen der statistischen Analyse und des Hypothesentestens vor. Mir ist es wichtig, dass ihr ein Gespür dafür bekommt, was vor sich geht, anstatt euch mit komplizierter Mathematik zu überhäufen. Auch wenn ich zentrale Formeln nicht weglassen kann und werde, werdet ihr mit der Mathematik gut zurechtkommen. Sie ist ausführlich kommentiert und am Ende des Tages gar nicht so schwer zu verstehen. Ihr werdet feststellen, dass die Programmierung in diesem Kapitel im Vergleich zu den vorherigen recht einfach ist. Am Ende braucht ihr nur Formeln, die alles erledigen, was ihr zur Datenanalyse benötigt – das ist auch eine Stärke von R. Bitte konzentriert euch mehr auf die Konzepte und versucht zu verstehen, was vor sich geht. Das Ziel dieses Kapitels ist, dass ihr die lineare Regression kennenlernt und wisst, wie ihr überprüft, ob das Modell gut passt und die Ergebnisse robust und signifikant sind.
5.1 Lineare Regression
5.1.1 Terminologie
Die klassische (bivariate) lineare Regression lässt sich in folgender Gleichung (systematische Komponente) ausdrücken:
\[ Y_i = \beta_0 + \beta_1X_i + e_i \]
dabei gilt:
Der Index i läuft über die Beobachtungen (Befragte, Länder,…), i = 1,…,n
\(Y_i\) ist die abhängige Variable, die Variable, die wir erklären möchten
\(X_i\) ist die unabhängige Variable bzw. die erklärende Variable
\(\beta_0\) ist der Achsenabschnitt (Intercept) der Regressionsgeraden
\(\beta_1\) ist die Steigung (Slope) der Regressionsgeraden
\(\epsilon_i\) ist der Fehlerterm, also die Abweichung unserer beobachteten Daten von den tatsächlichen Populationsdaten (z. B. Messfehler)
5.1.2 Schätzung des Kleinste-Quadrate-Schätzers
Um ein Gefühl für die lineare Regression zu bekommen, schauen wir uns ein Beispiel an. Dazu simulieren wir einige Daten und stellen sie grafisch dar. Ihr solltet nun den Dataframe df in eurer Umgebung haben. Er enthält die Variable X, unsere unabhängige Variable, sowie Y, unsere abhängige Variable. Wir möchten Y mit X erklären. Stellen wir die Variablen zunächst in einem Streudiagramm dar:
ggplot(df, aes(x, y)) +
geom_point() +
theme_bw() +
scale_x_continuous(breaks = seq(0, 10, by = 1)) +
scale_y_continuous(breaks = seq(0, 20, by = 2))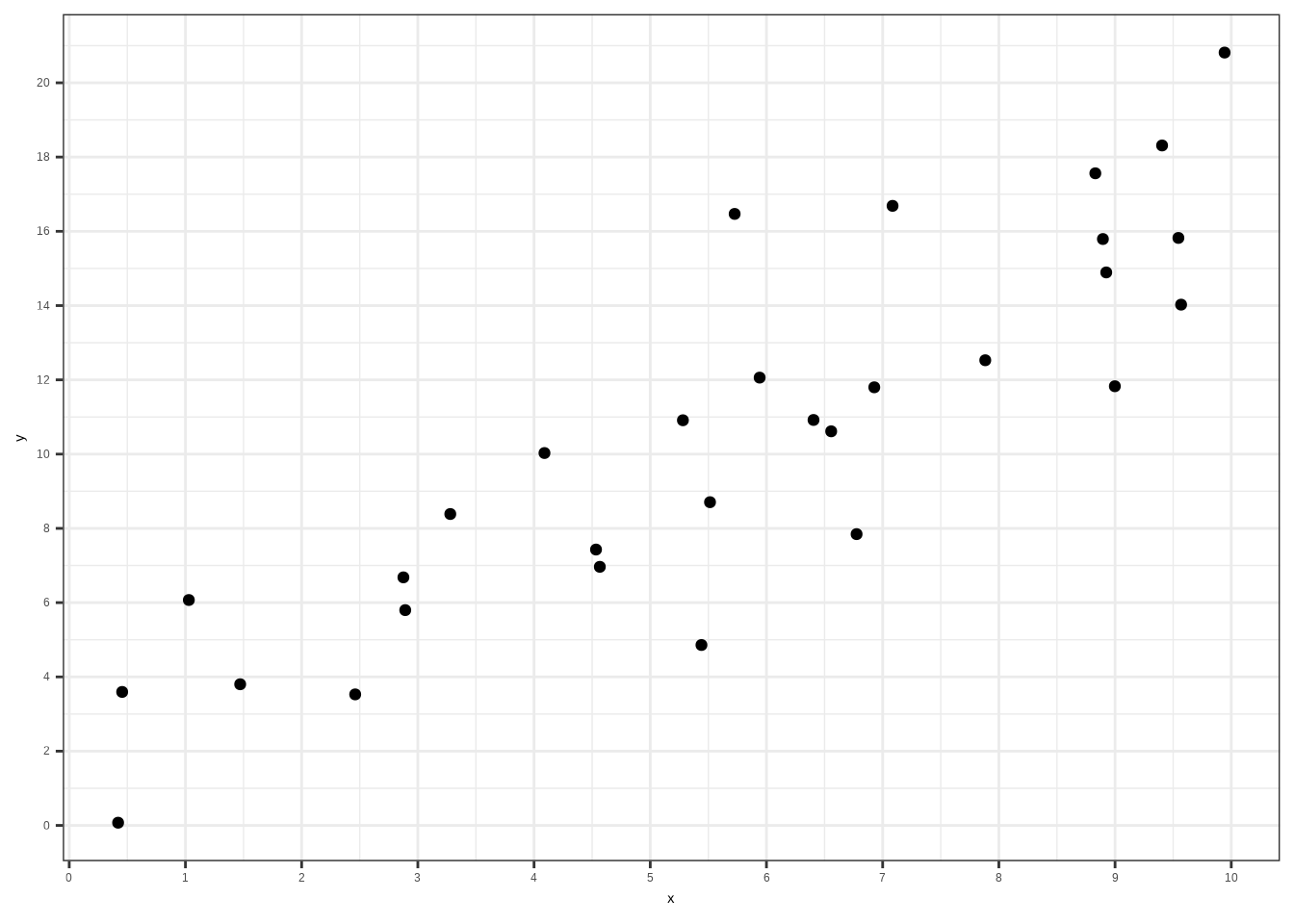
Wir können erkennen, dass es eine Beziehung zwischen diesen beiden Variablen geben muss: Je größer x wird, desto größer wird y. Die lineare Regression kann uns helfen, diese Beziehung zu untersuchen. Wir müssen lediglich die Formel verwenden und \(\beta_0\) sowie \(\beta_1\) schätzen. Dazu schätzen wir den Kleinste-Quadrate-Schätzer (OLS). Um zu verstehen, was der OLS-Schätzer macht, schauen wir uns das Streudiagramm noch einmal an: Der OLS-Schätzer legt eine Gerade durch alle Punkte, die den Abstand zu den Punkten so weit wie möglich minimiert. Anschließend extrahieren wir den Achsenabschnitt \(\beta_0\) (der Punkt, an dem die Gerade die y-Achse schneidet) und \(\beta_1\) (die Steigung der Geraden). Da es sich um geschätzte Werte für unser Modell handelt, nennen wir sie per Konvention \(\hat{\beta_0}\) und \(\hat{\beta_1}\), was wir im Folgenden auch so bezeichnen werden.
5.1.2.1 Visualisierung
Die visuelle Schätzung ist gut, um ein Gespür für die Daten zu bekommen, funktioniert jedoch – wie wir später sehen werden – nicht bei mehreren unabhängigen Variablen. Außerdem liefert sie nicht viele Informationen, zumindest nicht so viele, wie wir gerne hätten.
ggplot(df, aes(x, y)) +
geom_point() +
theme_bw() +
scale_x_continuous(breaks = seq(0, 10, by = 1)) +
scale_y_continuous(breaks = seq(0, 30, by = 5)) +
geom_smooth(method = "lm", se = FALSE) +
geom_segment(aes(x = x, y = y, xend = x, yend = predict(lm(y ~ x, data = df))), linewidth = 0.5) ## `geom_smooth()` using formula = 'y ~ x'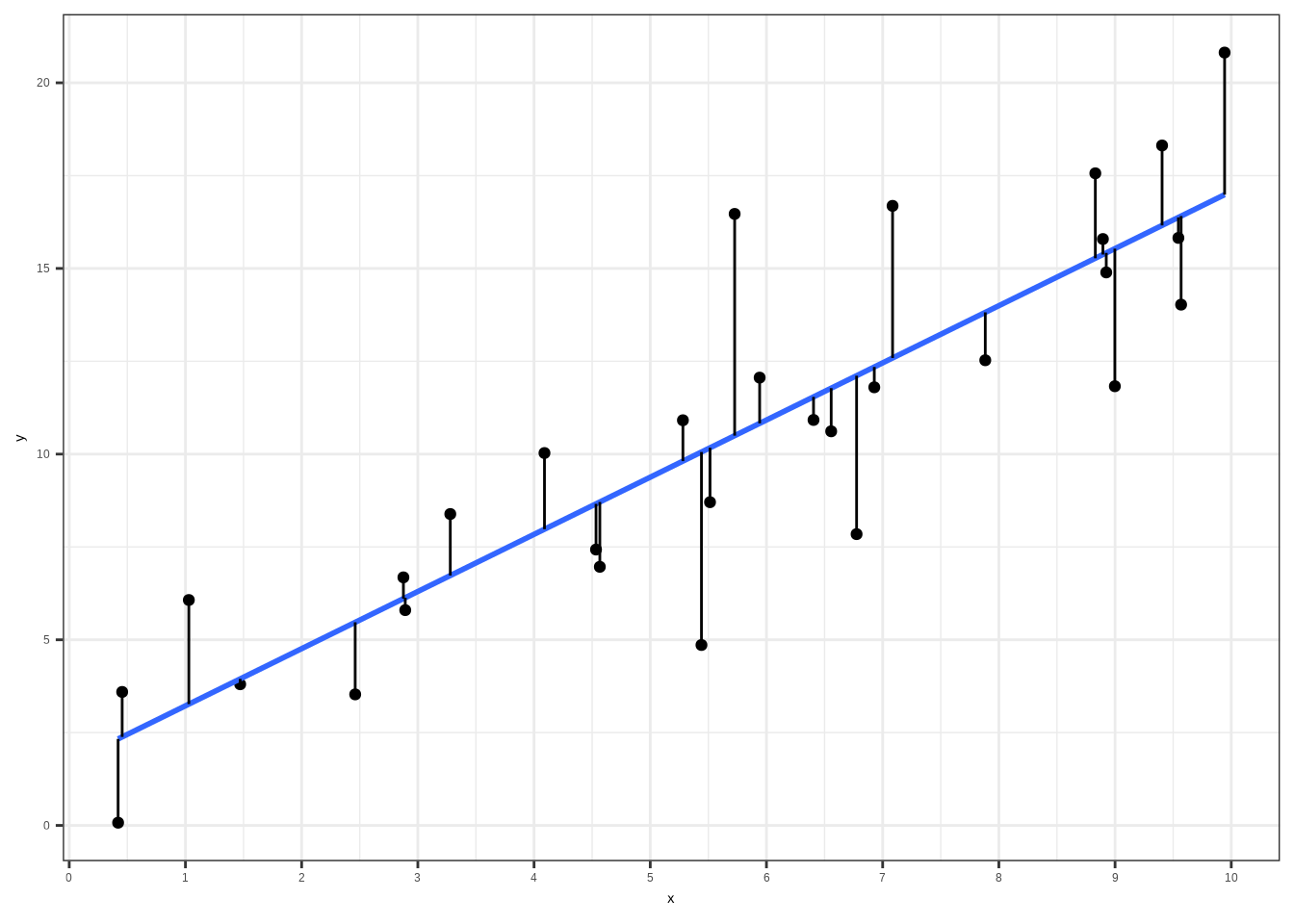
5.1.2.2 Berechnung von Hand
Wir könnten \(\hat{\beta_0}\) und \(\hat{\beta_1}\) auch von Hand berechnen. Die Formeln lauten wie folgt:
\[ \hat{\beta_1} = \frac{\sum_{i=1}^n(x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n(x_i - \bar{x})^2} \]
dabei ist \(x_i\) die Antwort von Beobachtung i für unsere unabhängige Variable x und \(\bar{x}\) der Durchschnittswert. Diese beiden Werte werden subtrahiert, wodurch die Abweichung vom Mittelwert berechnet wird. Dasselbe gilt für unsere abhängige Variable y, wobei \(y_i\) die Antwort von Beobachtung i und \(\bar{y}\) der Durchschnittswert aller Beobachtungen ist. Dies wird für jede Beobachtung i, also n-mal, durchgeführt, was durch das Summenzeichen dargestellt wird. Damit haben wir die sogenannte Kovarianz berechnet.
Die Kovarianz wird dann durch die quadrierte Abweichung vom Mittelwert unserer unabhängigen Variablen x dividiert. So erhalten wir den geschätzten Koeffizienten unseres Modells \(\hat{\beta_1}\). Klingt kompliziert, aber schauen wir es uns in R an:
# Zunächst berechnen wir die Kovarianz
cov <- sum((df$x - mean(df$x)) * (df$y - mean(df$y)))
# Nun berechnen wir die Varianz von x
x_sq <- sum((df$x - mean(df$x))^2)
x_sq## [1] 246.1869## [1] 1.539357Um den Achsenabschnitt \(\hat{\beta_0}\) zu erhalten, nehmen wir das Ergebnis der Steigung und setzen es in folgende Formel ein:
\[ \hat{\beta_0} = \bar{y} - \hat{\beta_1}*\bar{x} \]
Wir multiplizieren \(\hat{\beta_1}\) mit dem Mittelwert unserer unabhängigen Variable X und subtrahieren das Ergebnis vom Mittelwert unserer abhängigen Variable y.
## [1] 1.682133Nun haben wir unsere Parameter geschätzt und können sie in die systematische Komponente einsetzen:
\[ Y_i = 1.68 + 1.54 * X_i \]
5.1.2.3 Automatische Berechnung
Diese manuelle Vorgehensweise ist viel zu zeitaufwendig. R verfügt über eine eingebaute Funktion namens lm(), die die Parameter für uns berechnet:
# Lineare Regression berechnen
model1 <- lm(y ~ x,
data = df)
# Zusammenfassung der Modellergebnisse ausgeben
summary(model1)##
## Call:
## lm(formula = y ~ x, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.1985 -1.4215 -0.4309 1.5505 5.9720
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.6821 1.0376 1.621 0.116
## x 1.5394 0.1621 9.496 2.97e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.543 on 28 degrees of freedom
## Multiple R-squared: 0.7631, Adjusted R-squared: 0.7546
## F-statistic: 90.18 on 1 and 28 DF, p-value: 2.974e-10Wenn wir die Ergebnisse überprüfen, sehen wir, dass wir alles richtig gemacht haben und genau dieselben Werte erhalten. Die Interpretation des Koeffizienten lautet: Bei einer Erhöhung der unabhängigen Variable X um eine Einheit steigt die abhängige Variable im Durchschnitt um 0,68 Einheiten, unter sonst gleichen Bedingungen. Ihr habt sicher bemerkt, dass ihr mehr Informationen über das Modell erhaltet als nur die Koeffizienten. Darauf kommen wir später zurück.
5.1.3 Vorhersagen mit linearer Regression
Wir könnten Vorhersagen auf Basis unserer OLS-Berechnungen erstellen. Betrachten wir die systematische Komponente, die wir berechnet haben:
\[ \hat{y_i} = 1.68 + 1.54x_i \]
Wir müssen lediglich x-Werte einsetzen und erhalten gemäß unserem Modell eine Vorhersage des y-Werts \(\hat{y_i}\). Wir können das für alle x-Werte in unserem Datensatz tun und eine Spalte mit allen vorhergesagten Werten erhalten – nennen wir sie y_dach:
# Zunächst berechnen wir die Vorhersagen für y
df$y_dach <- 1.6821 + 1.5394*df$x
# Alternativ automatisch mit der predict()-Funktion
df$auto_y_dach <- predict(model1)
# Überprüfung
head(df)## x y kategorische_variable y_dach
## 1 2.875775 6.680633 0 6.109068
## 2 7.883051 12.527668 1 13.817269
## 3 4.089769 10.029008 0 7.977891
## 4 8.830174 17.562679 1 15.275270
## 5 9.404673 18.312220 1 16.159653
## 6 0.455565 3.594825 0 2.383397
## auto_y_dach
## 1 6.108979
## 2 13.816967
## 3 7.977750
## 4 15.274927
## 5 16.159286
## 6 2.3834115.2 Hypothesentesten in R
Wir sind nicht nur daran interessiert, ob unser Modell passt oder nicht. Wir möchten reale Phänomene untersuchen. Und wenn unser Modell nicht gut passt, müssen wir Anpassungen vornehmen. Der nächste Schritt ist, mehr über die Welt herauszufinden. Forscher tun dies, indem sie Hypothesen formulieren. Das sind nichts anderes als Annahmen, die man theoretisch über die Welt aufstellt. Nehmen wir an, ihr geht davon aus, dass Bildung einen Einfluss auf das Einkommen hat. Das wäre eure Alternativhypothese \(H_A\). Was ihr nun tun möchtet, ist, sie gegen die sogenannte Nullhypothese \(H_0\) zu testen. Das ist nichts anderes als das Gegenteil unserer Alternativhypothese, also dass Bildung keinen Einfluss auf das Einkommen hat. Formulieren wir beide, um einen Überblick zu haben:
\(H_0\) = Bildung hat keinen Einfluss auf das Einkommen.
\(H_A\) = Je gebildeter eine Person ist, desto höher ist ihr Einkommen.
Der Vorteil dieses Ansatzes liegt auf der Hand: Eine der beiden Aussagen muss wahr sein. Daher ist statistisches Testen notwendig. Bevor wir es euch vorstellen, müssen wir jedoch entscheiden, wie wir unsere Alternativhypothese testen wollen – genauer gesagt, wie wir unsere Variablen messen möchten. Für unser Beispiel entscheiden wir uns für eine Umfrage und erheben Daten, indem wir eine Zufallsstichprobe von 1000 Personen über 18 Jahren in Deutschland befragen (N = 1000). Wir messen unsere unabhängige Variable Bildung, indem wir die Befragten nach den Jahren fragen, die sie in ihre Ausbildung investiert haben. Das Einkommen erfragen wir direkt.
Fällt euch mögliche Kritik an unserer Datenerhebungsstrategie ein?
5.2.1 Standardfehler
5.2.1.1 Wurzel des mittleren quadratischen Fehlers (RMSE)
Bevor wir zu den Standardfehlern übergehen, stelle ich eine weitere Kennzahl vor: den Wurzel des mittleren quadratischen Fehlers (RMSE). Er ist die durchschnittliche Differenz zwischen den tatsächlichen Werten \(y_i\) und unseren vorhergesagten Werten \(\hat{y_i}\). Zur Berechnung quadrieren wir die Residuen, um nur positive Werte zu erhalten. Dann berechnen wir den Mittelwert und ziehen abschließend die Quadratwurzel:
\[ \text{RMSE} = \sqrt{\frac{\sum_{i=1}^{n}(\hat{y}_i - y_i)^2}{n}} \]
#Getting the residuals
residuen <- df$y_dach - df$y
#Getting the squared residuals
quadrierte_residuen <- residuen^2
#Getting the mean of the squared residuals
mittelwert_qu_resid <- mean(quadrierte_residuen)
#Getting the RSME
rmse <- sqrt(mittelwert_qu_resid)
#Or in one line
#rmse <- sqrt(mean((df$y_dach - df$y)^2))Als Faustregel gilt: Je niedriger der RMSE, desto besser. Er ist ein nicht-standardisiertes Gütemaß. Sein Pendant ist das R-Quadrat, ein standardisiertes Maß. Beide sollten verwendet werden, um ein Bild davon zu bekommen, wie eng die vorhergesagten Werte um die tatsächlichen Werte verteilt sind.
5.2.1.2 Standardfehler des Schätzers
Der Standardfehler eines Koeffizientenschätzers ist die Kennzahl, die direkt neben dem Koeffizienten in der Regressionsausgabe angezeigt wird. Er ist die Quadratwurzel der Varianz des Regressionskoeffizienten.
#Getting the residuals
residuen <- df$y - df$y_dach
#getting sigma squared
sigma_qu <- sum(residuen^2) / (nrow(df) - 2)
#getting standard error of beta 1
sf_beta1 <- sqrt(sigma_qu / sum((df$x - mean(df$x))^2))
#print it
sf_beta1## [1] 0.16209855.2.2 T-Wert oder T-Statistik
Die Formel zur Berechnung des t-Werts ist einfach:
\[ t_i = \frac{\beta_i}{SE(\beta_i)} \]
dabei ist \(\beta_i\) der durch die lineare Regression berechnete Koeffizient und \(SE(\beta_i)\) der Standardfehler. Berechnen wir ihn manuell für unser Beispiel:
# t-Wert von Hand
t_wert_intercept <- -0.32773/0.30271
t_wert_x <- 0.67949/0.04813
# Ausgabe
print(t_wert_intercept) # -1.082653## [1] -1.082653## [1] 14.11781Der t-Wert allein sagt uns noch nichts über statistische Signifikanz aus. Er wird verwendet, um den p-Wert zu berechnen, der uns über die Signifikanz des Wertes informiert. Bevor wir ihn berechnen, müssen wir jedoch einige wichtige Konzepte verstehen.
Freiheitsgrade sind das erste Konzept. Nehmen wir an, wir haben eine Stichprobe aus mir und meiner Schwester (N = 2). Wir haben die Anzahl der Bücher jeder Person erfasst und einen Mittelwert von 30 berechnet. Ich habe 20 Bücher. Wie viele Bücher hat meine Schwester? Offensichtlich 40, wenn der Mittelwert 30 ist. Gegeben meinem Wert und dem Mittelwert der Stichprobe ist der Wert meiner Schwester zwingend vorgegeben. Genau das beschreiben die Freiheitsgrade: die Anzahl der Werte, die bei gegebenem Mittelwert frei gewählt werden können. Oder technisch ausgedrückt: die maximale Anzahl logisch unabhängiger Werte.
Die Regel lautet: Je größer die Stichprobe, desto höher die Freiheitsgrade und je kleiner die Stichprobe, desto geringer die Freiheitsgrade.
T-Verteilungen sind die Verteilungen, mit denen wir den p-Wert berechnen werden. Ich werde gleich ausführlicher darauf eingehen. Sie sind mit den Freiheitsgraden verknüpft, da diese das Randverhalten und die Form der Kurve bestimmen, bis zu dem Punkt, an dem die t-Verteilung einer Standardnormalverteilung ähnelt. Visualisieren wir das:
# Daten generieren
x <- seq(-5, 5, length.out = 100)
# Dichten berechnen
dichten <- data.frame(
x = rep(x, 4),
dichte = c(dt(x, df = 1), dt(x, df = 2), dt(x, df = 10), dnorm(x, mean = 0, sd = 1)),
verteilung = rep(c("t(df=1)", "t(df=2)", "t(df=10)", "Normal"), each = 100)
)
dichten$verteilung <- factor(dichten$verteilung,
levels = c("Normal",
"t(df=10)",
"t(df=2)",
"t(df=1)"))
# Plot erstellen
ggplot(dichten, aes(x = x, y = dichte, color = verteilung)) +
geom_line() +
theme_minimal() +
labs(x = "x", y = "Dichte",
title = "t-Verteilungen mit verschiedenen Freiheitsgraden") +
scale_color_manual(values = c("black", "red", "green", "blue")) +
scale_x_continuous("X", seq(-5,5,1), limits = c(-5,5))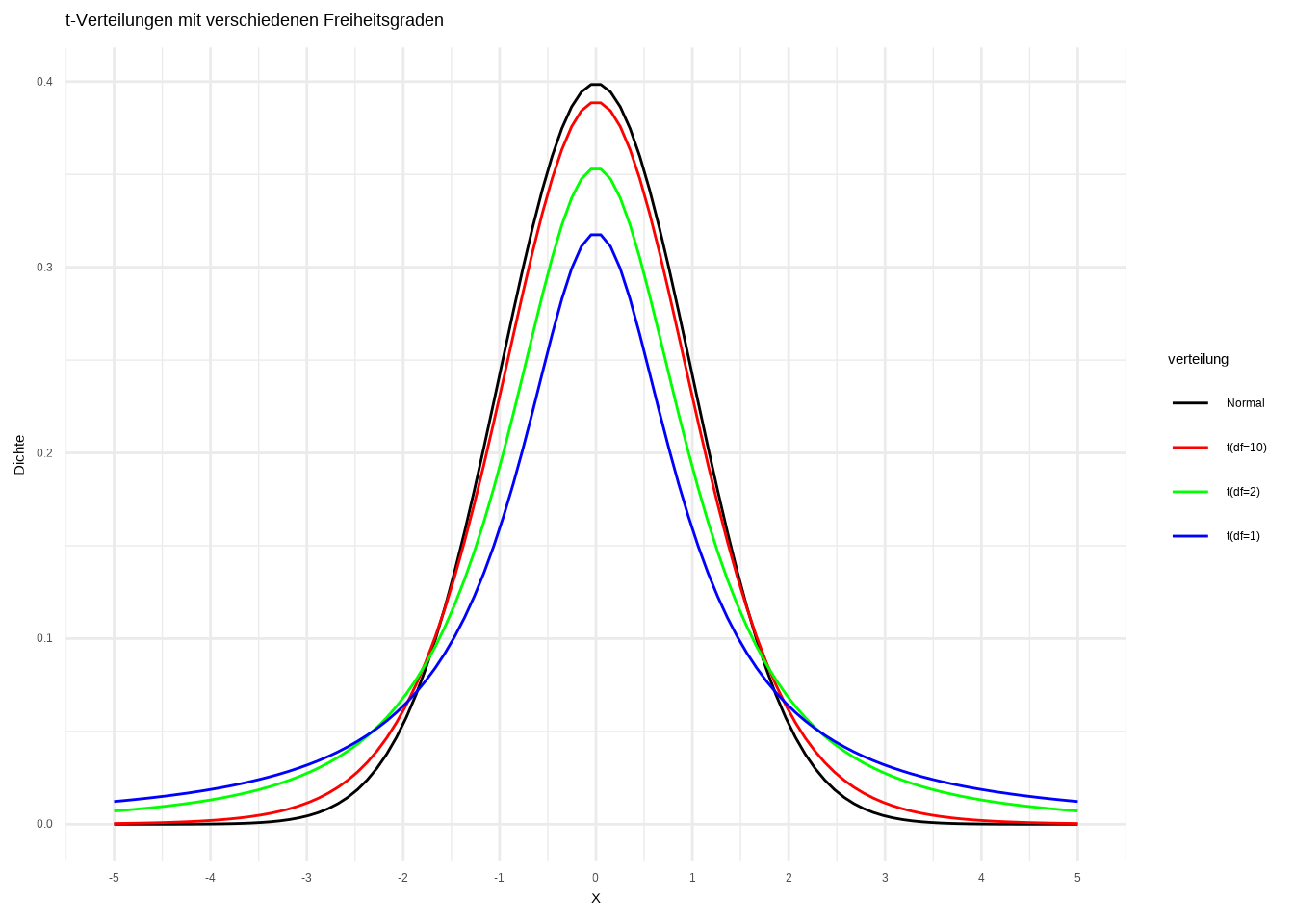
- Bevor wir herausfinden, wie wir bestimmen, ob ein Wert die Ablehnung der Nullhypothese erlaubt, müssen wir einen sogenannten kritischen Wert festlegen. Das ist keine Mathematik, sondern eine Wahrscheinlichkeit, über die wir selbst entscheiden. Genauer gesagt: die Wahrscheinlichkeit, dass unser t-Wert und damit unser Koeffizient rein zufällig aufgetreten ist. Wenn wir sagen, die Wahrscheinlichkeit, dass er zufällig aufgetreten ist, beträgt 10 %, dann ist das unser kritischer Wert. Als Faustregel gilt, dass eine Wahrscheinlichkeit von weniger als 5 %, dass der Koeffizient zufällig aufgetreten ist, auf statistische Signifikanz hinweist. Beachte, dass der kritische Wert je nach Stichprobengröße, Freiheitsgraden, Fachgebiet usw. variieren kann.
# Seed setzen
set.seed(42)
# Daten generieren
x <- seq(-5, 5, length.out = 100)
t_dichte <- function(x) dt(x, df = 28)
# Dichten berechnen
t_wert_data <- data.frame(
x = rep(x, 1),
dichte = dt(x, df = 28),
verteilung = rep("t(df=28)", 100)
)
# Plot erstellen
ggplot(t_wert_data, aes(x = x, y = dichte)) +
geom_line(lineend = "round") +
stat_function(fun = t_dichte, geom = "area", fill = "gray",
alpha = 0.75, xlim = c(-5, -1.701), n = 10000) +
stat_function(fun = t_dichte, geom = "area", fill = "gray",
alpha = 0.75, xlim = c(5, 1.701), n = 10000) +
geom_vline(xintercept = -1.701, linetype = "dashed",
colour = "red") +
geom_vline(xintercept = 1.701, linetype = "dashed",
colour = "red") +
ggtitle("t-Verteilung mit 28 Freiheitsgraden",
subtitle = "Der graue Bereich markiert das Intervall signifikanter Werte auf dem 95%-Niveau") +
geom_segment(x = -1.082653,
xend = -1.082653,
yend = dt(-1.082653, df = 28),
y = -1,
color = "pink",
linetype = "dashed",
linewidth = 0.2) +
annotate("point", x = -1.082653, y = dt(-1.082653, df = 28),
color = "pink") +
scale_x_continuous("X", seq(-5,5,1), limits = c(-5,5)) +
theme_classic() +
theme(legend.position = "none")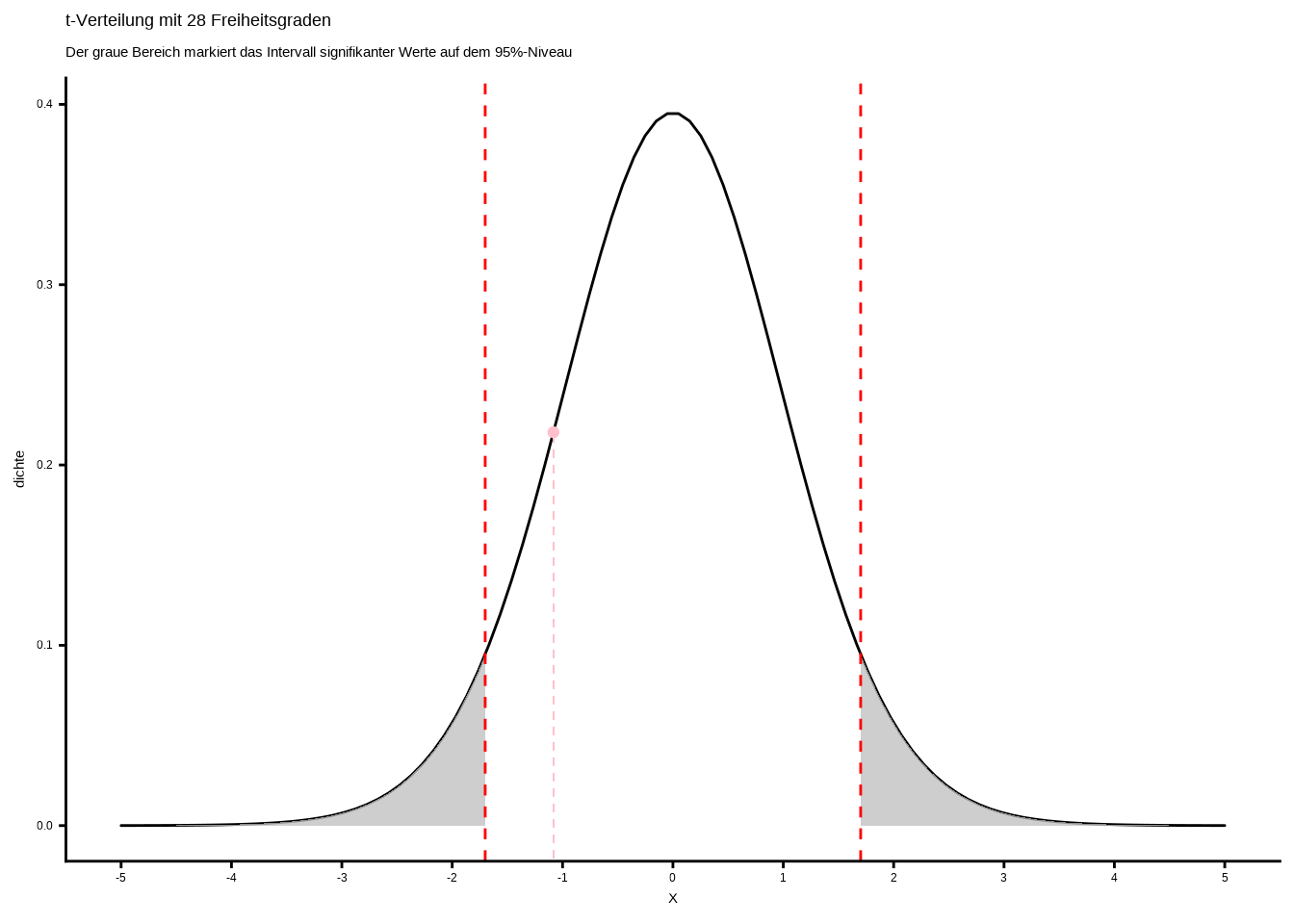
- Wie wir sehen, liegt die blaue Linie, die den Wert des Achsenabschnitts darstellt, nicht in dem Bereich, in dem sie sein müsste, damit wir die Nullhypothese ablehnen könnten. Der t-Wert unseres Koeffizienten der Variable liegt hingegen mit etwa 14 weit über dem Schwellenwert, sodass wir die Nullhypothese ablehnen können. So funktioniert der t-Wert. Das Problem ist, dass der Schwellenwert je nach Freiheitsgraden variiert und man ihn nicht für jeden Freiheitsgrad im Kopf haben kann. Man könnte ihn jedes Mal nachschlagen – oder man verwendet p-Werte, die direkt die Wahrscheinlichkeit angeben, dass der Koeffizient rein zufällig aufgetreten ist.
5.2.3 p-Werte
Der p-Wert ist eine Statistik, die uns die Wahrscheinlichkeit anzeigt, dass ein statistisches Maß (in unserem Beispiel 0) größer oder kleiner als ein beobachteter Wert ist (in unserem Beispiel der geschätzte Koeffizient). Die Nullhypothese würde besagen, dass unsere unabhängige Variable X keinen Einfluss auf Y hat. Statistisch gesprochen würde das bedeuten, dass unser Koeffizient eine hohe Wahrscheinlichkeit hat, null zu sein – denn null bedeutet kein Effekt, und wir könnten die Nullhypothese nicht ablehnen. Wenn die Wahrscheinlichkeit, dass unser geschätzter Koeffizient null ist, jedoch gering ist, können wir die Nullhypothese möglicherweise ablehnen und einen Effekt festgestellt haben.
Bevor wir euch zwei Wege zeigen, den p-Wert zu finden, müssen wir erneut einen kritischen Wert festlegen. Als Faustregel gilt: Wenn der p-Wert kleiner als 5 % ist, können wir die Nullhypothese ablehnen. Je nach verschiedenen Faktoren kann dies jedoch auch anders sein – abhängig von euren Daten, der Stichprobengröße, den Freiheitsgraden usw.
Für unser Beispiel folgen wir der Faustregel und setzen das Signifikanzniveau auf 0,05. Das bedeutet: Wenn der Koeffizient eine geringere Wahrscheinlichkeit (p-Wert < 0,05) als 5 % hat, null zu sein, können wir die Nullhypothese ablehnen – andernfalls nicht.
Da die Mathematik kompliziert ist und nicht dazu beiträgt, die Intuition zu verstehen, zeige ich euch direkt, wie man den p-Wert von Hand berechnet:
# p-Werte von Hand berechnen
p_value_1 <- 2 * pt(-abs(t_wert_intercept), 28)
p_value_2 <- 2 * pt(-abs(t_wert_x), 28)
# Ausgabe
print(p_value_1) ## [1] 0.2881981## [1] 2.941061e-14Wir erhalten dieselben Werte wie in unserer Regression. Da wir zuvor festgelegt haben, dass unser kritischer Wert (bezeichnet als \(\alpha\)) kleiner als 0,05 sein muss, um die Nullhypothese abzulehnen, können wir die Nullhypothese für den Koeffizienten unserer Variable x ablehnen. Da der Koeffizient positiv ist, lautet die Interpretation: x hat im Durchschnitt einen positiven Effekt auf y, da die Wahrscheinlichkeit, dass der Wert von null abweicht, unter dem kritischen Wert von 5 % liegt.
5.2.4 Konfidenzintervalle
Die letzte Methode zum Testen von Hypothesen sind Konfidenzintervalle. Ich empfehle deren Verwendung, da sie intuitiver und leichter zu interpretieren sind als p-Werte. Um Konfidenzintervalle zu verstehen, müssen wir uns den Unterschied zwischen Population und Stichprobe in Erinnerung rufen. Die Population umfasst alle Personen, auf die wir schließen möchten – bei einer Wahl beispielsweise alle wahlberechtigten Bürger. Nehmen wir an, dass der Stimmenanteil der Partei A in der Population 24 % beträgt. Das nennen wir den wahren Populationsparameter. Unser Ziel ist es, diesen Parameter mit statistischen Methoden zu schätzen, da das effizienter ist. Stellt euch Deutschland vor: Wir können nicht 80 Millionen Menschen vor der Wahl befragen. Stattdessen ziehen wir eine repräsentative Stichprobe. Das Problem ist, dass selbst eine repräsentative Stichprobe heute einen Stimmenanteil von 23 % für Partei A ergeben könnte, morgen aber 25 % (Warum könnte das so sein?).
Im Folgenden nehmen wir an, dass wir 1000 Stichproben vor der Wahl ziehen, um den Stimmenanteil von Partei A zu ermitteln. Wir wissen, dass unser wahrer Populationsparameter 24 % beträgt. Aber bevor wir beginnen, müssen wir erneut eine Regel festlegen – sie ist im Grunde die Definition von Konfidenzintervallen:
- In 95 % aller Stichproben, die gezogen werden könnten, werden die Konfidenzintervalle den wahren Populationsparameter enthalten.
Wenn wir also 1000 Stichproben ziehen, müssen in 950 davon die Konfidenzintervalle den wahren Populationsparameter enthalten:
Edit: Im Folgenden kürzen wir Konfidenzintervalle (Mehrzahl) mit CIs und Konfidenzintervall (Einzahl) mit ci ab
# Da dies eine Simulation ist, setzen wir einen Seed
set.seed(187)
# Vektoren für das obere und untere Konfidenzintervall erstellen
unteres_ci <- numeric(100)
oberes_ci <- numeric(100)
schätzungen <- numeric(100)
# Diese Schleife repräsentiert die Stichprobenziehungen
for(i in 1:length(unteres_ci)) {
Y <- rnorm(100, mean = 24, sd = 2)
schätzungen[i] <- Y[i]
oberes_ci[i] <- Y[i] - 1.96 * 24 / 10
unteres_ci[i] <- Y[i] + 1.96 * 24 / 10
}
# Beide Vektoren zusammenführen
CIs <- data.frame(schätzungen, unteres_ci, oberes_ci)
# Ausgabe
head(CIs)## schätzungen unteres_ci oberes_ci
## 1 22.86723 27.57123 18.16323
## 2 25.36001 30.06401 20.65601
## 3 26.32276 31.02676 21.61876
## 4 23.37235 28.07635 18.66835
## 5 22.71026 27.41426 18.00626
## 6 21.89276 26.59676 17.18876Nun haben wir unsere 1000 Stichproben gezogen und unsere Schätzungen sowie die zugehörigen Intervalle berechnet – also 1000 Stichproben über den Stimmenanteil von Partei A. Überprüfen wir, ob der wahre Populationsparameter in 95 % der berechneten Konfidenzintervalle enthalten ist:
# Wahren Mittelwert festlegen
wahrer_mittelwert <- 24
# Diejenigen identifizieren, die den wahren Populationsparameter 24 nicht enthalten
CIs$missed <- ifelse(CIs$oberes_ci > wahrer_mittelwert | CIs$unteres_ci < wahrer_mittelwert, "Außerhalb", "Innerhalb")
# Jeder Stichprobe eine Identifikationsnummer geben
CIs$id <- 1:nrow(CIs)
# Plotten
ggplot(data = CIs) +
geom_pointrange(
aes(
x = schätzungen, # Punktschätzer
xmin = unteres_ci, # unteres KI
xmax = oberes_ci, # oberes KI
y = id, # y-Achse – nur die Beobachtungsnummer
color = missed # Farbe variiert je nach missed-Variable
)
) +
geom_vline(
aes(xintercept = wahrer_mittelwert), # Vertikale Linie beim wahren Mittelwert
) +
scale_color_manual(values = c("red", "azure4")) +
theme_minimal() +
labs(
title = "Konfidenzintervall für den Mittelwert",
subtitle = "Wahrer Populationsparameter = 24",
x = "Schätzungen",
y = "Stichprobe",
color = "Ist der wahre Populationsparameter im KI enthalten?"
) +
theme(legend.position = "top") +
scale_x_continuous(breaks = c(seq(15, 30, by = 1)))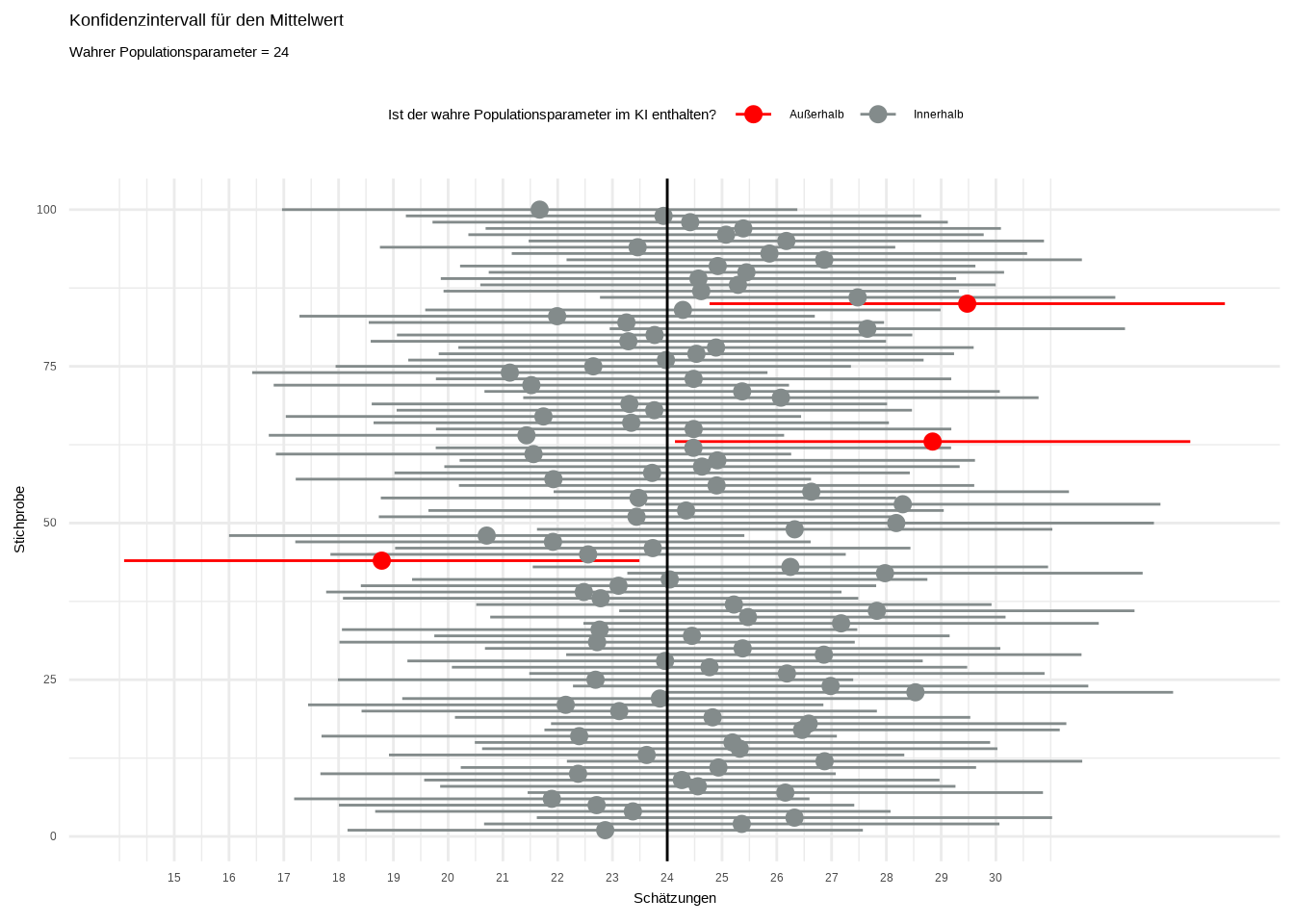
Wir können sehen, dass die Mehrheit der berechneten Intervalle den wahren Populationsparameter enthält. Es gibt jedoch drei, die ihn nicht enthalten – das liegt im Rahmen unserer Definition.
Wie ist das nun bei Konfidenzintervallen für Koeffizienten der linearen Regression? Es ist dieselbe Geschichte: Wir berechnen einen Schätzer – in diesem Fall einen Koeffizienten. Der wahre Populationsparameter ist unbekannt, aber wir wissen, dass er in 95 % der Intervalle enthalten ist.
Die Berechnung ist recht einfach und ihr habt sie bereits gesehen:
\[ KI_{unten} = \beta_i - 1.96 * SE(\beta_i) \\ KI_{oben} = \beta_i + 1.96 * SE(\beta_i) \]
## 2.5 % 97.5 %
## (Intercept) -0.4432173 3.807484
## x 1.2073136 1.871401# Konfidenzintervalle von Hand für Achsenabschnitt und x berechnen
ci_unteres_int <- model1$coefficients[1] - 1.96 * summary(model1)$coef[, "Std. Error"][1]
ci_oberes_int <- model1$coefficients[1] + 1.96 * summary(model1)$coef[, "Std. Error"][1]
# Ausgabe
print(ci_unteres_int)## (Intercept)
## -0.3514894## (Intercept)
## 3.715756# Schätzer X
ci_unteres_est <- model1$coefficients[2] - 1.96 * summary(model1)$coef[, "Std. Error"][2]
ci_oberes_est <- model1$coefficients[2] + 1.96 * summary(model1)$coef[, "Std. Error"][2]
# Ausgabe
print(ci_unteres_est)## x
## 1.221644## x
## 1.8570715.3 Multivariate Regression
Die Welt ist komplex, und wenn wir eine abhängige Variable Y haben – z. B. das Einkommen –, können wir sie natürlich nicht ausschließlich durch die Bildungsjahre, den Beruf oder einen anderen einzelnen Faktor erklären. Es ist vielmehr plausibel, dass all diese Faktoren eine Rolle spielen. Das multivariate lineare Regressionsmodell ermöglicht es uns, die Variation in unserer abhängigen Variable Y mit mehreren unabhängigen Variablen X zu erklären. Mathematisch verändert sich die systematische Komponente wie folgt:
\[ Y_i = \beta_0 + \beta_1X_{1i} + \beta_2X_{2i} + ... + \beta_kX_{ki} + \epsilon_i \]
dabei gilt:
Der Index i läuft über die Beobachtungen (Befragte, Länder,…), i = 1,…,n
\(Y_i\) ist die abhängige Variable, die wir erklären möchten
\(X_{1i}\) ist die erste unabhängige bzw. erklärende Variable
\(X_{2i}\) ist die zweite unabhängige bzw. erklärende Variable
\(X_{ki}\) ist die k-te unabhängige bzw. erklärende Variable, wobei k die Anzahl aller unabhängigen Variablen im Modell ist
\(\beta_0\) ist der Achsenabschnitt der Regressionsgeraden
\(\beta_1\) ist die Steigung der Regressionsgeraden der ersten erklärenden Variable
\(\beta_2\) ist die Steigung der Regressionsgeraden der zweiten erklärenden Variable
\(\beta_k\) ist die Steigung der Regressionsgeraden der k-ten erklärenden Variable
\(\epsilon_i\) ist der Fehlerterm
In R können wir ein multivariates Modell sehr einfach mit der bereits bekannten Funktion lm() implementieren. Führen wir eine multiple Regression mit unserer unabhängigen Variable X und unserer kategorialen Variable Z durch. Die systematische Komponente für dieses Modell lautet:
\[ Y_i = \beta_0 + \beta_1X_i + \beta_2Z_i + \epsilon_i \]
Berechnen wir die Steigungen:
##
## Call:
## lm(formula = y ~ x + kategorische_variable, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5183 -1.3840 -0.5014 1.2393 5.5808
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.9799 1.0679 1.854 0.0747
## x 1.5557 0.1621 9.596 3.42e-10
## kategorische_variable1 -1.0667 0.9637 -1.107 0.2781
##
## (Intercept) .
## x ***
## kategorische_variable1
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.533 on 27 degrees of freedom
## Multiple R-squared: 0.7734, Adjusted R-squared: 0.7566
## F-statistic: 46.07 on 2 and 27 DF, p-value: 1.982e-09Wir sehen, dass das gut funktioniert – wir mussten lediglich die unabhängige Variable in den Befehl einfügen, genau wie in der systematischen Komponente. Die Interpretation ist analog zur einfachen linearen Regression: Bei einer Erhöhung der unabhängigen Variable x um eine Einheit steigt die abhängige Variable y im Durchschnitt um 0,67 Einheiten, unter sonst gleichen Bedingungen. Für Kategorie 1 im Vergleich zu Kategorie 0 steigt die abhängige Variable y im Durchschnitt um 0,52 Einheiten, unter sonst gleichen Bedingungen. Nun können wir die berechneten Koeffizienten in unsere systematische Komponente einsetzen und Vorhersagen treffen:
\[ Y_i = -0.54 + 0.67X_i + 0.52Z_i + \epsilon_i \]
Um das zu visualisieren, bräuchten wir ein dreidimensionales Koordinatensystem – denn jede unabhängige Variable entspricht einer Dimension. Ich sagte, dass k die Anzahl unserer unabhängigen Variablen ist; technisch gesehen ist es die Anzahl der Dimensionen unseres Modells. Ich bin kein Fan von Graphen mit mehr als drei Dimensionen und empfehle euch das auch nicht.
5.4 Kategoriale Variablen
Wie ich im ersten Kapitel erwähnt habe, gibt es verschiedene Variablentypen. Rufen wir sie uns in Erinnerung:
| Numerisch | Zahlen | c(1, 2.4, 3.14, 4) |
| Character | Text | c("1", "blue", "fun", "monster") |
| Logisch | Wahr oder falsch | c(TRUE, FALSE, TRUE, FALSE) |
| Faktor | Kategorie | c("Stimme gar nicht zu", "Stimme zu", "Neutral") |
Abhängige Variablen müssen bei der linearen Regression numerisch sein. Unabhängige Variablen können jedoch unterschiedlich skaliert sein. Numerische Variablen sind der einfachste Fall – die Interpretation erfolgt wie in den vorherigen Beispielen beschrieben. Kategoriale Variablen werden jedoch anders interpretiert. Untersuchen wir die kategoriale Variable in unserem Datensatz, kategorische_variable:
##
## 0 1
## 19 11Wir sehen, dass unser Datensatz eine kategoriale Variable mit zwei Kategorien enthält: „A” und „B”. Diese Kategorien könnten für alles stehen: Weiblich und Männlich, Produkt gekauft oder nicht gekauft, Impfstoff oder Placebo usw. Was passiert nun, wenn wir ein Modell damit berechnen?
# Modell mit kategorialer Variable berechnen
model2 <- lm(y ~ kategorische_variable,
data = df)
# Zusammenfassung ausgeben
summary(model2) ##
## Call:
## lm(formula = y ~ kategorische_variable, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.2770 -3.7683 0.1863 4.0996 10.2377
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.5765 1.1985 8.825 1.41e-09
## kategorische_variable1 -0.2265 1.9792 -0.114 0.91
##
## (Intercept) ***
## kategorische_variable1
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.224 on 28 degrees of freedom
## Multiple R-squared: 0.0004673, Adjusted R-squared: -0.03523
## F-statistic: 0.01309 on 1 and 28 DF, p-value: 0.9097Wir sehen einen Koeffizienten von 0,64 – das ist in Ordnung. Aber wie ihr seht, wird die Kategorie „category_A” nicht angezeigt. Warum? Kategoriale Variablen werden auf Basis sogenannter „Referenzkategorien” berechnet. R bestimmt die Referenzkategorie alphabetisch. In diesem Fall ist Kategorie „A” die Referenzkategorie. Sie heißt so, weil sich die berechneten Koeffizienten auf sie beziehen. Die Referenzkategorie „A” nimmt den Wert 0 an. Der Koeffizient der Kategorie B beträgt „0,92”. Das bedeutet: Wenn eine befragte Person zu Kategorie „B” gehört, steigt die abhängige Variable Y im Durchschnitt um 0,64 Einheiten im Vergleich zu Kategorie „A”, unter sonst gleichen Bedingungen.
Das klingt technisch – schauen wir uns ein besseres Verständnis davon an. Wir fügen eine Null zu unserem Code hinzu und betrachten die Ausgabe:
# Modell berechnen
model3 <- lm(y ~ kategorische_variable + 0,
data = df)
# Zusammenfassung ausgeben
summary(model3)##
## Call:
## lm(formula = y ~ kategorische_variable + 0, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.2770 -3.7683 0.1863 4.0996 10.2377
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## kategorische_variable0 10.576 1.198 8.825 1.41e-09
## kategorische_variable1 10.350 1.575 6.571 3.99e-07
##
## kategorische_variable0 ***
## kategorische_variable1 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.224 on 28 degrees of freedom
## Multiple R-squared: 0.8122, Adjusted R-squared: 0.7987
## F-statistic: 60.53 on 2 and 28 DF, p-value: 6.812e-11Die Koeffizienten haben sich verändert, aber nur geringfügig. Subtrahieren wir den Koeffizienten von Kategorie A von Kategorie B:
# Ergebnis
result <- coefficients(model3)[2] - coefficients(model3)[1] # Koeffizienten können so extrahiert werden
# Ausgabe
result## kategorische_variable1
## -0.2264615Wir erhalten denselben Koeffizienten wie zuvor – und genau das macht R automatisch, wenn es Koeffizienten für kategoriale Variablen berechnet. Die Referenzkategorie wird auf 0 gesetzt, und die anderen Kategorien werden relativ dazu skaliert.
5.4.1 Interaktionseffekte
Eine wichtige und weit verbreitete Technik in der Statistik sind Interaktionseffekte. Um die Dinge einfach zu halten, konzentrieren wir uns auf unsere unabhängige Variable X und unsere kategoriale Variable Z. Wie erwähnt zeigt Z die Koeffizienten für unsere Kategorien „A” und „B”. Aber was, wenn wir die Dynamik innerhalb der Gruppe genauer untersuchen könnten? Interaktionseffekte ermöglichen es uns, unsere Variable X mit der kategorialen Variable Z zu multiplizieren. Mathematisch sieht unsere systematische Komponente dann so aus:
\[ Y_i = \beta_0 + \beta_1X_i + \beta_2Z_i + \beta_3X_i*Z_i + e_i \]
dabei gilt:
Der Index i läuft über die Beobachtungen (Befragte, Länder,…), i = 1,…,n
\(Y_i\) ist die abhängige Variable
\(X_i\) ist die unabhängige Variable
\(Z_i\) ist unsere kategoriale Variable
\(\beta_0\) ist der Achsenabschnitt
\(\beta_1\) ist die Steigung
\(\epsilon_i\) ist der Fehlerterm
Im Folgenden zeige ich euch an einem Beispiel, wie Interaktionseffekte verwendet werden. Nehmen wir an, ich habe eine Umfrage unter 1000 Befragten durchgeführt und sie gefragt, wie viele Stunden sie mit R-Online-Kursen wie diesem verbracht haben. Dann habe ich nach ihren Programmierkenntnissen gefragt. Abschließend habe ich gefragt, ob sie mit diesem Kurs oder mit anderen Kursen gelernt haben (0 = andere Kurse, 1 = dieser Kurs). Nun wollen wir herausfinden, ob mehr investierte Stunden zu höheren R-Programmierkenntnissen führen. Außerdem möchten wir untersuchen, ob dieser Kurs im Vergleich zu anderen Kursen zu besseren Kenntnissen führt. Dazu interagieren wir die aufgewendeten Stunden mit der Variable, die angibt, ob die befragte Person andere Kurse oder diesen Kurs absolviert hat.
- Interaktionseffekte können in R implementiert werden, indem man sie explizit in die Funktion
lm()schreibt – entweder mit einem Sternchen*oder einem Doppelpunkt::
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Aufgewendete Stunden generieren
investierte_stunden <- runif(100, min = 0, max = 10)
# Kurs-Dummy generieren (0 = andere Kurse, 1 = dieser Kurs)
dieser_kurs = sample(c(0, 1), 100, replace = TRUE)
# Y mit Interaktionseffekt generieren
coding_fähigkeiten <- 2 + 0.5 * investierte_stunden + 0 *
dieser_kurs + 1.5 * investierte_stunden * dieser_kurs + rnorm(100)
# Dataframe erstellen
df_int <- data.frame(investierte_stunden, dieser_kurs, coding_fähigkeiten)
# Interaktionsmodell anpassen
model_interaktion <- lm(coding_fähigkeiten ~ investierte_stunden * dieser_kurs, data = df_int)
# Modellzusammenfassung ausgeben
summary(model_interaktion)##
## Call:
## lm(formula = coding_fähigkeiten ~ investierte_stunden * dieser_kurs,
## data = df_int)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.9122 -0.7295 -0.0765 0.5901 3.3882
##
## Coefficients:
## Estimate Std. Error t value
## (Intercept) 1.82617 0.32506 5.618
## investierte_stunden 0.52184 0.05380 9.699
## dieser_kurs 0.03336 0.41030 0.081
## investierte_stunden:dieser_kurs 1.47571 0.07068 20.877
## Pr(>|t|)
## (Intercept) 1.88e-07 ***
## investierte_stunden 6.59e-16 ***
## dieser_kurs 0.935
## investierte_stunden:dieser_kurs < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.9799 on 96 degrees of freedom
## Multiple R-squared: 0.9696, Adjusted R-squared: 0.9687
## F-statistic: 1022 on 3 and 96 DF, p-value: < 2.2e-16Interaktionseffekte sind für sich genommen nicht intuitiv. Um ein Gespür dafür zu bekommen, müssen wir sie grafisch darstellen. Das sjPlot-Paket bietet den Befehl plot_model(), der automatisch sogenannte vorhergesagte Wahrscheinlichkeiten plottet. Es würde zu weit führen, vorhergesagte Wahrscheinlichkeiten im Detail zu erklären. Wichtiger ist, dass wir einen Graphen erhalten, der den Interaktionseffekt visualisiert:
Wir rufen
plot_model()auf und übergeben unser Modell mit dem Interaktionseffektmodel_interaktion.Dann geben wir den Typ an und setzen ihn auf
type="int", was explizit Interaktionseffekte plottet.
plot_model(model_interaktion, type = "int") +
scale_x_continuous(breaks = seq(0,10, 1)) +
labs(title = "Programmierkenntnisse nach Kursart im Vergleich",
x = "Aufgewendete Stunden",
y = "R-Programmierkenntnisse") +
scale_color_manual(
values = c("red", "blue"),
labels = c("Andere Kurse", "Dieser Kurs")
) +
theme_sjplot() +
theme(legend.position = "bottom",
legend.title = element_blank())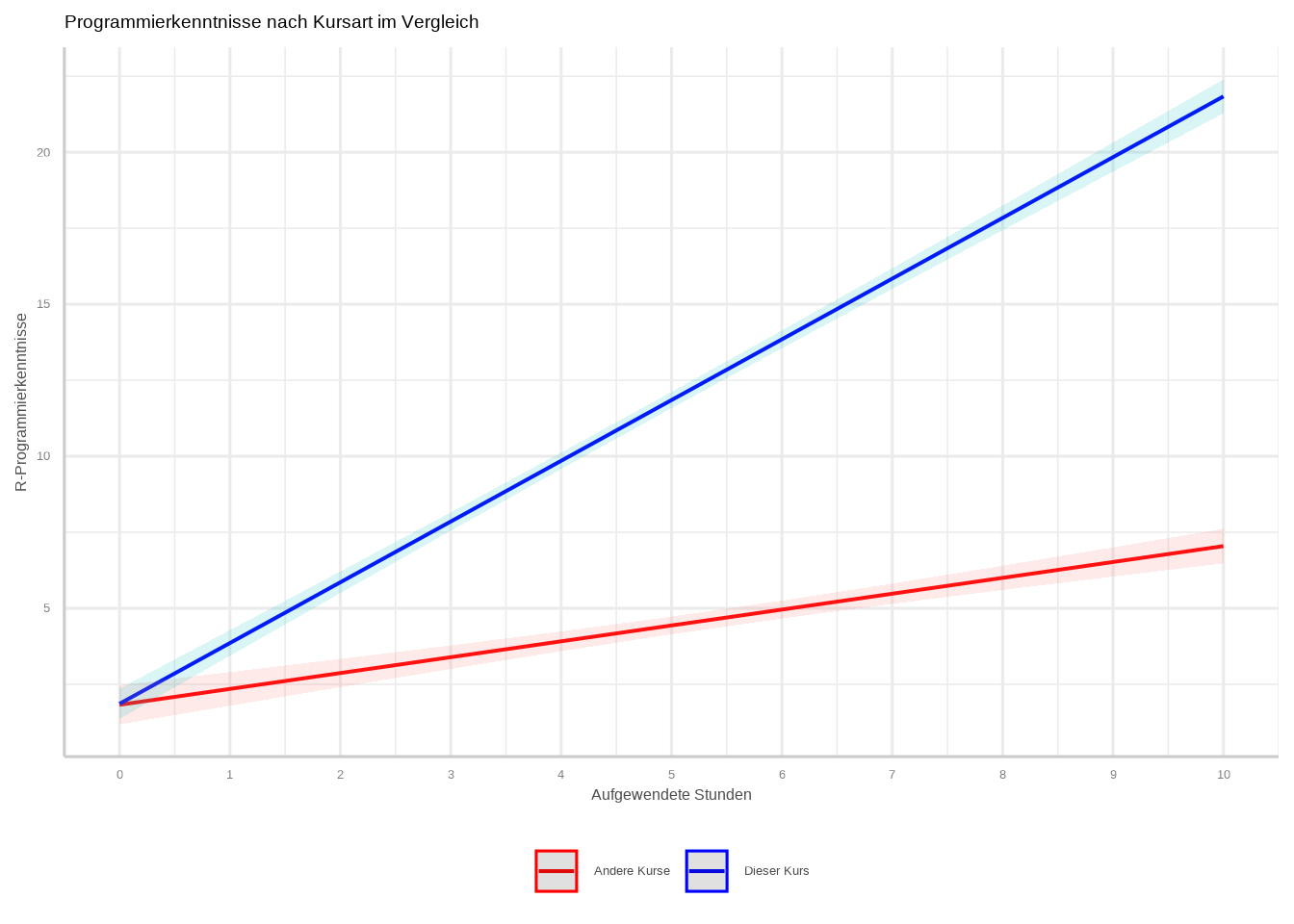
Auf der x-Achse haben wir unsere unabhängige Variable, auf der y-Achse unsere abhängige Variable – soweit wie gewohnt. Wir sehen jedoch zwei Linien: eine für alle Beobachtungen in der Kategorie „Andere Kurse” (rote Linie) und eine für alle Beobachtungen in der Kategorie „Dieser Kurs” (blaue Linie). Genau das macht ein Interaktionseffekt: Für jeden Punkt in unserer unabhängigen Variable wird eine Vorhersage für y in einer Kategorie berechnet sowie eine Linie für jede Beobachtung in der anderen Kategorie.
Zur Interpretation gehen wir in zwei Schritten vor: Zunächst betrachten wir die Richtung der Linien. Wir sehen, dass X einen positiven Effekt auf Y hat – beide Linien steigen mit höheren X-Werten an. Der Interaktionseffekt ermöglicht es uns, den Effekt von X auf Y für alle Gruppen der kategorialen Variable zu vergleichen. In unserem Beispiel bedeutet das, dass Beobachtungen in Gruppe 1 einen stärkeren Effekt zeigen als Beobachtungen in Gruppe 0.
Bringen wir dieses Beispiel zum Leben: Wir untersuchen den Effekt der Lernstunden (x) auf die Prüfungsergebnisse (y) für zwei Gruppen von Studierenden: jene, die einen Vorbereitungskurs besucht haben (Gruppe 1), und jene, die das nicht getan haben (Gruppe 0).
Interpretation:
- Richtung der Linien:
- Beide Linien (für Gruppe 0 und Gruppe 1) steigen an. Das bedeutet, dass mehr investierte Stunden im Durchschnitt zu höheren R-Programmierkenntnissen führen.
- Effektvergleich:
Die Steigung für Gruppe 1 (dieser Kurs) ist steiler als für Gruppe 0 (andere Kurse).
Das bedeutet: Für Studierende, die diesen Kurs absolviert haben, hat jede zusätzliche Lernstunde einen größeren positiven Einfluss auf ihre R-Programmierkenntnisse im Vergleich zu jenen, die einen anderen Kurs absolviert haben.
Durch die Visualisierung und Analyse des Interaktionseffekts können wir aussagekräftige Schlussfolgerungen darüber ziehen, wie verschiedene Faktoren (z. B. die Teilnahme an einem Vorbereitungskurs) die Beziehung zwischen Lernaufwand und Leistungsergebnissen verändern.
5.5 Ausblick
Dieses Kapitel war eine Einführung in das Hypothesentesten und grundlegende statistische Anwendungen. Außerdem wurde das beliebteste und wichtigste Modell vorgestellt: die lineare Regression. Das Kapitel zeigte nicht nur, wie die lineare Regression in R berechnet wird, sondern auch, wie man überprüft, ob Effekte robust sind und wie gut das Modell passt. Darüber hinaus wurden Erweiterungen der linearen Regression eingeführt: die multivariate Regression und kategoriale Variablen.
Die lineare Regression ist die Grundlage von fast allem. Fortgeschrittene Modellierungen verschiedener Klassen abhängiger Variablen bis hin zu Techniken des maschinellen Lernens basieren auf der linearen Regression. Das war auch der Grund, warum ich nicht nur die lineare Regression vorgestellt habe, sondern auch gezeigt habe, wie anfällig das Modell ist. Schlechte Modellierung führt immer zu schlechten Ergebnissen, daher müssen wir anstreben zu überprüfen, wie gut unser Modell zu unseren Daten und damit zu unserem Forschungsinteresse passt.
Weiterführende Links:
- Einen Kurs, den ich empfehlen kann, wenn ihr einen detaillierten Einblick in die Statistik erhalten möchtet, ist „Introduction to Econometrics with R” von Christoph Hanck, Martin Arnold, Alexander Gerber und Martin Schmelzer.
5.6 Übungsaufgaben
Um die lineare Regression zu verstehen, müssen wir keine komplizierten Daten laden. Nehmen wir an, ihr seid Marktanalysten und euer Auftraggeber ist die Produktionsfirma einer Serie namens „Breaking Thrones”. Die Produktionsfirma möchte wissen, wie die Zuschauer die letzte Folge bewertet haben. Ihr führt eine Umfrage durch und fragt die Befragten nach ihrer Zufriedenheit mit dem Serienfinale sowie nach einigen soziodemografischen Merkmalen. Hier ist euer Codebuch:
| Variable | Beschreibung |
|---|---|
| id | Die ID des Befragten |
| satisfaction | Antwort auf die Frage „Wie zufrieden waren Sie mit der letzten Folge von Breaking Throne?“, wobei 0 = völlig unzufrieden und 10 = völlig zufrieden |
| age | Das Alter des Befragten |
| female | Das Geschlecht des Befragten, wobei 0 = Männlich, 1 = Weiblich |
Generieren wir die Daten:
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Daten generieren
final_BT <- data.frame(
id = c(1:10),
satisfaction = round(rnorm(10, mean = 6, sd = 2.5)),
age = round(rnorm(10, mean = 25, sd = 5)),
female = rbinom(10, 1, 0.5)
)
print(final_BT)## id satisfaction age female
## 1 1 5 31 0
## 2 2 5 27 0
## 3 3 10 27 0
## 4 4 6 26 0
## 5 5 6 22 0
## 6 6 10 34 0
## 7 7 7 27 0
## 8 8 3 15 0
## 9 9 4 29 0
## 10 10 5 23 15.6.1 Übung 1: Lineare Regression mit zwei Variablen
Ihr möchtet wissen, ob das Alter einen Einfluss auf die Zufriedenheit mit der letzten Folge hat. Dazu führt ihr eine lineare Regression durch.
a. Berechnet \(\beta_0\) und \(\beta_1\) von Hand.
b. Berechnet \(\beta_0\) und \(\beta_1\) automatisch mit R.
c. Interpretiert alle Größen eures Ergebnisses: Standardfehler, t-Statistik, p-Wert, Konfidenzintervalle und das \(R^2\).
d. Überprüft auf einflussreiche Ausreißer.
5.6.2 Übung 2: Multivariate Regression
a. Fügt die Variable female zu eurer Regression hinzu.
b. Interpretiert die Ausgabe. Was hat sich verändert? Was bleibt gleich?
c. Erstellt einen Interaktionseffekt zwischen Alter und Geschlecht und interpretiert ihn!
d. Plottet den Interaktionseffekt und gestaltet den Plot ansprechend.