Chapter 2 Datenmanipulation
In diesem Kapitel laden und transformieren wir Daten. Das ist ein Standardschritt und wahrscheinlich der zeitaufwändigste Schritt bei der Datenanalyse. Die Datenvorbereitung ist notwendig, da die Datenanalyse Daten in einem bestimmten Format erfordert. Welches Format das ist, hängt vom Modell ab. Ich stelle euch dplyr vor, das Standardpaket zur Datenmanipulation. Am Anfang wirkt es etwas kompliziert, aber ich verspreche euch: Wenn ihr Datenanalysen in R durchführt, werdet ihr viel damit arbeiten und recht schnell sicher damit umgehen. Das Ziel dieses Kapitels ist es, euch zu zeigen, wie man Daten so manipuliert, dass wir sie in das Format bringen können, das wir für eine ordentliche Analyse benötigen. Viel Spaß!

2.1 Pakete
Bisher haben wir ausschließlich sogenannte „Base-R-Funktionen” oder „eingebaute Funktionen” verwendet. R hat jedoch eine aktive Community, und manchmal werden weitere Operationen benötigt – dafür verwenden wir Pakete. Diese enthalten zusätzliche Funktionen, die wir im folgenden Abschnitt intensiv nutzen werden.
2.2 Mit Paketen arbeiten
2.2.1 Pakete installieren
Um Pakete zu installieren, verwendet man den treffend benannten install.packages()-Befehl in R. Beachtet, dass es notwendig ist, ein Paket direkt in R zu installieren. Dieser Schritt ist nur einmal erforderlich:
Rufe den
install.packages()-Befehl auf.Schreibe den Namen des Pakets in Anführungszeichen in die Funktion.
install.packages("pacman")
2.2.2 Pakete laden
Während ein Paket nur einmal installiert werden muss, muss es jedes Mal geladen werden, wenn das Skript geöffnet wird. Das geschieht mit der library()-Funktion in R:
Rufe die
library()-Funktion auf.Schreibe den Namen des Pakets hinein.
library(pacman)
Es ist immer wichtig, einen effizienten Arbeitsablauf in R zu haben. Traditionelle R-Nutzer laden alle benötigten Pakete am Anfang ihres Skripts. So müssen sie nur zum Anfang des Skripts zurückgehen und die Pakete jedes Mal laden, wenn sie das Skript öffnen. Es gibt jedoch elegantere und pragmatischere Möglichkeiten.
Eine davon ist das pacman-Paket:
Wenn man den Paketnamen mit
::dahinter schreibt, weist man R an, in das Paket zu gehen und einen bestimmten Befehl daraus abzurufen – in unserem Fall denp_load-Befehl.Der
p_load-Befehl lädt die in den Klammern angegebenen Pakete und prüft, ob sie installiert sind. Falls nicht, installiert und lädt er sie automatisch.
2.4 Ran an die Daten: Das dplyr-Paket

Das dplyr-Paket ist DAS Standardpaket für die Datenmanipulation (neben Base R natürlich). Es verfügt über wesentliche und nützliche Funktionen. Wenn ihr die Flexibilität dieser Funktionen versteht, könnt ihr problemlos mit jedem Datensatz umgehen.
2.4.1 Der filter()-Befehl
Die erste Funktion, die ich vorstelle, ist filter(). Mit ihr können wir bestimmte Bedingungen festlegen, um unseren Datensatz entsprechend einzuschränken.
Wir benötigen
filter()und dann eine Variable, nach der wir filtern möchten. In meinem Beispiel möchte ich nur alle Beobachtungen behalten, die „HU” in dercntry-Variable haben. Inhaltlich bedeutet das, dass ich nur auf Beobachtungen aus Ungarn einschränke. Ich verwende den==-Operator, da ich alle Beobachtungen haben möchte, bei denen die Bedingung wahr ist.Hier eine kurze Erinnerung an logische Operatoren in R:
Logischer Operator Bedeutung == gleich < kleiner als > größer als <= kleiner oder gleich >= größer oder gleich ! (z. B. !=; >!; <!…) ungleich, nicht größer als, nicht kleiner als & elementweiser UND-Operator. Gibt TRUE zurück, wenn beide Elemente wahr sind | elementweiser ODER-Operator. Gibt TRUE zurück, wenn eine Aussage wahr ist
2.4.1.1 Filtern nach einer einzigen Bedingung
Zunächst definieren wir ein neues Objekt, nennen wir es
d1.Dann nehmen wir die Daten, die wir filtern möchten – in unserem Fall
ess.Wir definieren eine Pipe, schreiben
filter()und legen eine Bedingung fest: Hier sollen nur Fälle behalten werden, bei denencntrygleich dem ISO2C-Code für Ungarn,"HU", ist.Im nächsten Code machen wir dasselbe und filtern für Fälle, die gleich oder kleiner als 40 sind – so erhalten wir einen Datensatz mit Beobachtungen, die 40 Jahre oder jünger sind.
Hinweis: Da
cntryeine Zeichenvariable ist, muss die Bedingung in Anführungszeichen gesetzt werden. Die Variableageaist numerisch, daher genügt die Zahl.
## idnt year cntry agea gndr happy eisced netusoft trstprl
## 1 4501 2020 HU 21 2 3 6 4 3
## 2 4502 2020 HU 48 1 5 5 3 5
## 3 4503 2020 HU 80 1 6 3 4 4
## 4 4504 2020 HU 38 1 6 3 2 1
## 5 4505 2020 HU 40 2 10 3 3 9
## 6 4506 2020 HU 40 1 1 7 2 2
## lrscale
## 1 2
## 2 3
## 3 1
## 4 3
## 5 7
## 6 3## idnt year cntry agea gndr happy eisced netusoft trstprl
## 1 3 2020 BE 28 2 3 4 5 4
## 2 8 2020 BE 28 2 5 1 2 1
## 3 9 2020 BE 39 2 8 3 1 4
## 4 12 2020 BE 23 1 77 1 4 4
## 5 14 2020 BE 40 2 3 5 2 3
## 6 15 2020 BE 21 1 1 4 1 8
## lrscale
## 1 7
## 2 1
## 3 6
## 4 7
## 5 2
## 6 52.4.1.2 Filtern nach mehreren Bedingungen
# Fälle aus Ungarn und Frankreich filtern
d1 <- ess %>%
filter(cntry %in% c("HU", "FR"))
# Überprüfen
head(d1) ## idnt year cntry agea gndr happy eisced netusoft trstprl
## 1 2701 2020 FR 41 9 7 7 8 8
## 2 2702 2020 FR 64 1 2 5 4 5
## 3 2703 2020 FR 90 1 5 6 5 1
## 4 2704 2020 FR 23 1 9 3 3 9
## 5 2705 2020 FR 30 2 8 7 2 7
## 6 2706 2020 FR 42 2 10 88 9 9
## lrscale
## 1 6
## 2 4
## 3 8
## 4 3
## 5 9
## 6 5# Fälle unter 40 aus Ungarn und Frankreich filtern
d2 <- ess %>%
filter(cntry %in% c("HU", "FR") &
agea <= 40)
# Überprüfen
head(d2)## idnt year cntry agea gndr happy eisced netusoft trstprl
## 1 2704 2020 FR 23 1 9 3 3 9
## 2 2705 2020 FR 30 2 8 7 2 7
## 3 2708 2020 FR 17 1 1 2 2 8
## 4 2709 2020 FR 26 2 10 1 4 9
## 5 2710 2020 FR 34 1 8 3 1 3
## 6 2711 2020 FR 30 1 5 3 5 9
## lrscale
## 1 3
## 2 9
## 3 3
## 4 6
## 5 8
## 6 102.4.2 Die select()-Funktion
Wir interessieren uns natürlich nicht für alle Variablen, die ein Datensatz bietet (meistens). Um die benötigten Variablen auszuwählen, können wir die select()-Funktion verwenden. Das hängt natürlich von unserer Forschungsfrage ab. Nehmen wir an, wir möchten Jahr, Land, die happy-Variable, Alter, Geschlecht und Bildung auswählen.
2.4.2.1 Variablen auswählen und löschen
- Wir müssen lediglich die Spaltennamen an
select()übergeben. Das war’s.
# Relevante Variablen auswählen
d1 <- ess %>%
select(year, cntry, happy, agea, gndr, eisced)
# Überprüfen
head(d1) ## year cntry happy agea gndr eisced
## 1 2020 BE 1 45 1 6
## 2 2020 BE 3 65 1 5
## 3 2020 BE 3 28 2 4
## 4 2020 BE 1 81 1 7
## 5 2020 BE 4 56 2 7
## 6 2020 BE 3 64 1 52.4.2.2 Variablen löschen
- Um eine Spalte zu löschen, setzt man einfach ein Minuszeichen vor den Spaltennamen. Das war’s – der Rest bleibt gleich.
## year cntry happy gndr eisced
## 1 2020 BE 1 1 6
## 2 2020 BE 3 1 5
## 3 2020 BE 3 2 4
## 4 2020 BE 1 1 7
## 5 2020 BE 4 2 7
## 6 2020 BE 3 1 52.4.2.3 select() mit filter() kombinieren
Ein großer Vorteil des Pipings ist, dass wir Daten in einem oder wenigen Schritten bereinigen können. Dabei muss man lediglich beachten, was in welcher Reihenfolge steht – der letzte Befehl wird zuerst ausgeführt.
In diesem Beispiel wählen wir 7 Variablen aus und filtern dann nach allen Beobachtungen unter 40.
Die beiden Befehle sind durch eine Pipe getrennt.
# Befehle kombinieren
d1 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced)
# Überprüfen
head(d1)## year cntry happy agea gndr eisced
## 1 2020 BE 3 28 2 4
## 2 2020 BE 5 28 2 1
## 3 2020 BE 8 39 2 3
## 4 2020 BE 77 23 1 1
## 5 2020 BE 1 21 1 4
## 6 2020 BE 5 23 2 62.4.3 Die arrange()-Funktion
Wenn wir möchten, dass unsere Daten in einer bestimmten Reihenfolge vorliegen, können wir sie mit arrange() sortieren.
2.4.3.1 Aufsteigend sortieren
arrange()wird aufgerufen, danach die Variable, nach der sortiert werden soll. Standardmäßig sortiertarrange()immer aufsteigend.
# arrange() hinzufügen
d1 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced) %>%
arrange(agea)
# Überprüfen
head(d1)## year cntry happy agea gndr eisced
## 1 2020 BE 6 15 2 4
## 2 2020 BE 2 15 1 1
## 3 2020 BG 3 15 9 99
## 4 2020 BG 4 15 1 6
## 5 2020 BG 2 15 2 2
## 6 2020 BG 2 15 1 32.4.3.2 Absteigend sortieren
- Für eine absteigende Sortierung muss
desc()innerhalb vonarrange()aufgerufen werden, mit dem Variablennamen indesc().
# Absteigend sortieren
d1 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced) %>%
arrange(desc(agea))
# Überprüfen
head(d1)## year cntry happy agea gndr eisced
## 1 2020 BE 8 39 2 3
## 2 2020 BE 1 39 1 2
## 3 2020 BE 10 39 2 5
## 4 2020 BE 2 39 1 3
## 5 2020 BE 6 39 2 7
## 6 2020 BE 3 39 1 12.4.4 Die Funktionen rename() und relocate()
Zwei Funktionen, die unseren Datensatz strukturierter und übersichtlicher machen, sind rename() und relocate() – sie tun, was ihre Namen versprechen:
2.4.4.1 Variablen umbenennen: rename()
rename()folgt einer einfachen Logik: Man ruft die Funktion auf, schreibt den neuen Namen (also den Namen, den man zuweisen möchte), setzt ein Gleichheitszeichen und gibt dann den alten Namen (also den aktuellen Spaltennamen) an.
Hinweis: Wenn eine Variable binär ist, also zwei diskrete Kategorien hat, benennt man sie nach der Kategorie, die dem höheren Wert entspricht. Wenn männlich = 0 und weiblich = 1, benennt man die Variable nach der höheren Kategorie 1 – also
weiblich.
# Variablen umbenennen
d1 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced) %>%
arrange(desc(agea)) %>%
rename(land = cntry,
alter = agea,
bildungsstand = eisced,
weiblich = gndr)
# Überprüfen
head(d1)## year land happy alter weiblich bildungsstand
## 1 2020 BE 8 39 2 3
## 2 2020 BE 1 39 1 2
## 3 2020 BE 10 39 2 5
## 4 2020 BE 2 39 1 3
## 5 2020 BE 6 39 2 7
## 6 2020 BE 3 39 1 12.4.4.2 Variablen verschieben: relocate()
Man ruft
relocate()auf und legt die Reihenfolge der Spalten fest.Einzelne Spalten können auch gezielt verschoben werden: Man gibt den Namen der Spalte an, die verschoben werden soll, und dann entweder
.beforeund eine Spalte oder.afterund eine Spalte. Die Spalte wird dann vor oder nach der angegebenen Spalte platziert. Beide Argumente werden durch ein Komma getrennt.
# Variablen neu anordnen
d1 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced) %>%
arrange(desc(agea)) %>%
rename(land = cntry,
alter = agea,
bildungsstand = eisced,
weiblich = gndr) %>%
relocate(bildungsstand, alter, weiblich, land, happy, year) # Reihenfolge festlegen
# Überprüfen
head(d1)## bildungsstand alter weiblich land happy year
## 1 3 39 2 BE 8 2020
## 2 2 39 1 BE 1 2020
## 3 5 39 2 BE 10 2020
## 4 3 39 1 BE 2 2020
## 5 7 39 2 BE 6 2020
## 6 1 39 1 BE 3 2020# Nach einer Spalte verschieben
d2 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced) %>%
arrange(desc(agea)) %>%
rename(land = cntry,
alter = agea,
bildungsstand = eisced,
weiblich = gndr) %>%
relocate(land, .after = alter)
# Überprüfen
head(d2)## year happy alter land weiblich bildungsstand
## 1 2020 8 39 BE 2 3
## 2 2020 1 39 BE 1 2
## 3 2020 10 39 BE 2 5
## 4 2020 2 39 BE 1 3
## 5 2020 6 39 BE 2 7
## 6 2020 3 39 BE 1 1# Vor eine Spalte verschieben
d3 <- ess %>%
filter(agea < 40) %>%
select(year, cntry, happy, agea, gndr, eisced) %>%
arrange(desc(agea)) %>%
rename(land = cntry,
alter = agea,
bildungsstand = eisced,
weiblich = gndr) %>%
relocate(land, .before = alter)
# Überprüfen
head(d3)## year happy land alter weiblich bildungsstand
## 1 2020 8 BE 39 2 3
## 2 2020 1 BE 39 1 2
## 3 2020 10 BE 39 2 5
## 4 2020 2 BE 39 1 3
## 5 2020 6 BE 39 2 7
## 6 2020 3 BE 39 1 12.4.5 Die mutate()-Funktion
Der nächste Befehl ist das mächtige mutate(). Zunächst kann man sich mutate() einfach als eine Funktion vorstellen, mit der man Variablen nach Belieben transformieren oder verändern kann.
Man ruft
mutate()auf und definiert zunächst den Namen einer neuen Spalte – einen Namen, der noch nicht im Datensatz existiert. Man könnte auch den Namen einer vorhandenen Spalte verwenden, aber Vorsicht: Dann werden die alten Werte überschrieben, was nicht immer gewünscht ist. Daher empfehle ich, immer neue Spalten zu definieren.Nach dem neuen Namen setzt man ein Gleichheitszeichen und definiert die Berechnung. In unserem Fall multiplizieren wir
happy– also alle Werte in derhappy-Spalte – mit 10.
## idnt year cntry agea gndr happy eisced netusoft trstprl
## 1 1 2020 BE 45 1 1 6 2 2
## 2 2 2020 BE 65 1 3 5 4 3
## 3 3 2020 BE 28 2 3 4 5 4
## 4 4 2020 BE 81 1 1 7 3 2
## 5 5 2020 BE 56 2 4 7 5 6
## 6 6 2020 BE 64 1 3 5 4 6
## lrscale happy_10
## 1 3 10
## 2 6 30
## 3 7 30
## 4 6 10
## 5 4 40
## 6 10 30mutate() kann jedoch mehr als nur Berechnungen durchführen. Wir können damit auch neue Spalten erstellen, indem wir vorhandene Spalten in andere Klassen umwandeln:
new_variableist lediglich eine zufällige mathematische Operation mit zwei Variablen.Der zweite
mutate()-Aufruf ändert die Klasse dergndr-Variable in einen Zeichenvektor und speichert sie entsprechend im Datensatz.
# Weiteres Mutieren
d2 <- ess %>%
mutate(neue_variable = happy * 10 / eisced + 67,
weiblich_char = as.character(gndr)) %>%
select(weiblich_char, neue_variable)
# Überprüfen
head(d2)## weiblich_char neue_variable
## 1 1 68.66667
## 2 1 73.00000
## 3 2 74.50000
## 4 1 68.42857
## 5 2 72.71429
## 6 1 73.00000Was mutate() so mächtig macht, ist, dass man andere Funktionen darin verwenden kann, um Variablen nach Wunsch zu definieren. Stellt euch die happy-Variable vor. Zur Erinnerung: Diese Variable enthält die Antworten auf die Frage „Wie glücklich sind Sie?” im Fragebogen des European Social Survey. Sie ist auf einer Skala von 0 (überhaupt nicht glücklich) bis 10 (sehr glücklich) skaliert.
Angenommen, wir möchten das ändern. Wir möchten eine Variable mit nur drei Kategorien erstellen (unglücklich, neutral, glücklich). Alle Werte von 0–4 sollen als „unglücklich”, 5 als „neutral” und alles über 5 als „glücklich” eingestuft werden. Wie geht das in R?
Es gibt verschiedene Möglichkeiten – ich zeige euch einige davon:
2.4.5.1 Rekodieren mit mutate() und recode()
Man kann die recode()-Funktion verwenden:
Zuerst definieren wir einen neuen Spaltennamen, in unserem Beispiel
happy_cat.Dann rufen wir
recode()auf und übergeben die zu transformierende Variable, in unserem Fallhappy.Die Kategorie, die wir transformieren möchten, wird in
``gesetzt. Danach ein Gleichheitszeichen und der neue Wert, den wir der Kategorie zuweisen möchten.
Hinweis: Wir können verschiedene Werte zuweisen. Über
NA_real_kommen wir später noch.
##
## 1 2 3 4 5 6 7 8 9 10 77 88 99
## 849 918 888 897 888 852 883 877 908 895 49 46 50# Variablen rekodieren
d1 <- ess %>%
mutate(
gndr_fac = as.factor(gndr),
happy_cat = dplyr::recode(happy,
`1` = 0,
`2` = 0,
`3` = 0,
`4` = 0,
`5` = 1,
`6` = 2,
`7` = 2,
`8` = 2,
`9` = 2,
`10` = 2,
`77` = NA_real_,
`88` = NA_real_,
`99` = NA_real_),
weiblich = dplyr::recode(gndr_fac,
`1` = "männlich",
`2` = "weiblich",
`9` = NA_character_))
# Ergebnis prüfen
table(d1$happy_cat)##
## 0 1 2
## 3552 888 4415##
## männlich weiblich
## 4381 44042.4.5.2 Rekodieren mit mutate() und case_when()
Wie man sieht, ist der recode()-Befehl sehr ausführlich. tidyverse bietet einen viel intuitiveren Befehl: die case_when()-Funktion. Diese ist eine verallgemeinerte ifelse()-Funktion, d. h. wir können logische Operatoren verwenden. recode() gibt zwar vollständige Kontrolle über die Daten, aber so viel Kontrolle brauchen wir oft nicht:
Wir definieren wieder
happy_cat.Wir rufen
case_when()auf und übergeben die zu transformierende Variable.Wir definieren eine logische Aussage: Hier soll
happykleiner als 5 sein, d. h. alle Werte unter 5 sollen transformiert werden.Wir schreiben die Tilde
~und sagen R, welcher Wert alle Werte ersetzen soll, für die die logische Aussage WAHR ist.
Hinweis: Was in
case_when()nicht explizit angegeben wird, wird als NA kodiert.
# Rekodieren mit case_when
d1 <- ess %>%
mutate(gndr_fac = as.factor(gndr),
happy_cat = case_when(
happy < 5 ~ 0,
happy == 5 ~ 1,
happy > 5 ~ 2),
weiblich = case_when(
gndr == 1 ~ "männlich",
gndr == 2 ~ "weiblich"
))
# Überprüfen
table(d1$weiblich)##
## männlich weiblich
## 4381 4404##
## 0 1 2
## 3552 888 45602.4.5.3 Rekodieren mit mutate() und ifelse()
Erinnert ihr euch an die ifelse()-Funktion? Wie bereits erwähnt, ist case_when() eine verallgemeinerte ifelse()-Funktion. Wer es klassisch mag, kann auch mit ifelse() rekodieren:
# Rekodieren mit der ifelse()-Funktion
d1 <- ess %>%
mutate(gndr_fac = as.factor(gndr),
happy_cat = ifelse(happy < 5, 0,
ifelse(happy == 5, 1,
ifelse(happy > 5, 2, NA))),
weiblich = ifelse(gndr_fac == 1, "männlich",
ifelse(gndr_fac == 2, "weiblich", NA))
)
# Überprüfen
table(d1$happy_cat)##
## 0 1 2
## 3552 888 4560##
## männlich weiblich
## 4381 44042.4.6 Umgang mit fehlenden Werten / unvollständigen Daten
Wie gerade gesehen, sind nicht alle Daten in einem Datensatz vollständig. Natürlich nicht – es gibt verschiedene Ursachen für unvollständige oder fehlende Daten. Könnt ihr euch Gründe vorstellen, warum?
In der Datenwissenschaft müssen wir fehlende Werte direkt behandeln. Im Codebuch deklariert der ESS verschiedene Typen von fehlenden Werten mit hohen Zahlen: 7(7) bedeutet „Verweigerung” (die befragte Person hat die Antwort verweigert), 8(8) bedeutet „Weiß nicht” und 9(9) „Keine Antwort”.
Der ESS tut dies, da manche Forscher an fehlenden Werten und deren Ursachen interessiert sind und diese untersuchen möchten.
Für uns ist das ein Problem, da wir keine Analysen mit fehlenden Werten durchführen können. Es gibt zwei Möglichkeiten:
- Fehlende Werte mithilfe von Statistiken künstlich auffüllen – das nennt sich Multiple Imputation. Das erfordert jedoch fortgeschrittene Datenwissenschaftskenntnisse und ist für Anfänger nicht zu empfehlen.
- Unvollständige Beobachtungen löschen, um einen Datensatz ohne fehlende Werte zu erhalten.
Der ESS weist fehlenden Werten Zahlenwerte zu. Zunächst müssen wir R mitteilen, dass diese Werte als fehlend behandelt werden sollen – andernfalls würden sie unsere Analysen verzerren. Im Folgenden müssen wir die Variablen rekodieren und R mitteilen, dass die fehlenden Werte entsprechend deklariert werden:
- Das haben wir bereits gezeigt. Im Folgenden verwende ich
case_when().
Wir wählen die zweite Option. Das Rekodieren von nutzlosen Werten zu NAs sollte inzwischen vertraut sein. Zur Erinnerung: ifelse() und recode() benötigen explizite Eingaben, um Werte in NAs umzuwandeln.
# Fehlende Werte erstellen und einen Mutations-Workflow zeigen
d1 <- ess %>%
filter(agea >= 40) %>%
select(year, cntry, netusoft, agea, eisced, gndr, happy) %>%
arrange(desc(agea)) %>%
rename(
internet_nutzung = netusoft,
alter = agea,
bildungsstand = eisced,
weiblich = gndr) %>%
mutate(
internet_nutzung = case_when(
internet_nutzung > 5 ~ NA_real_,
TRUE ~ internet_nutzung),
alter = case_when(
alter == 999 ~ NA_real_,
TRUE ~ alter),
bildungsstand = case_when(
bildungsstand %in% c(55, 77, 88, 99) ~ NA_real_,
TRUE ~ bildungsstand),
weiblich = case_when(
weiblich == 1 ~ 0,
weiblich == 2 ~ 1,
weiblich == 9 ~ NA_real_,
TRUE ~ weiblich),
happy = case_when(
happy %in% c(77, 88, 99) ~ NA_real_,
TRUE ~ happy)
) %>%
arrange(alter)
# Überprüfen
head(d1) ## year cntry internet_nutzung alter bildungsstand weiblich
## 1 2020 BE 2 40 5 1
## 2 2020 BE 2 40 6 0
## 3 2020 BE 4 40 1 0
## 4 2020 BE 2 40 5 0
## 5 2020 BE 3 40 6 1
## 6 2020 BE 2 40 6 0
## happy
## 1 3
## 2 10
## 3 9
## 4 6
## 5 9
## 6 4Wenn man den Datensatz ausgibt, sieht man, dass einige Werte nun „NA” heißen – das steht für „Not Available” (nicht verfügbar).
Fehlende Werte lassen sich mit der
tidyverse-Methode einfach durch Pipen zudrop_na()entfernen.Die Base-R-Methode wäre, den Datensatznamen in
na.omit()zu übergeben.
Wir weisen beide Ergebnisse einem neuen Dataframe zu. Das Ergebnis zeigt, dass alle Zeilen mit NAs entfernt wurden. Das ist auch ein Grund, warum es wichtig ist, nur die benötigten Variablen auszuwählen – so werden nur unvollständige Beobachtungen unserer relevanten Variablen gelöscht. Daher gilt immer: Erst transformieren, dann löschen.
## year cntry internet_nutzung alter bildungsstand weiblich
## 1 2020 BE 2 40 5 1
## 2 2020 BE 2 40 6 0
## 3 2020 BE 4 40 1 0
## 4 2020 BE 2 40 5 0
## 5 2020 BE 3 40 6 1
## 6 2020 BE 2 40 6 0
## happy
## 1 3
## 2 10
## 3 9
## 4 6
## 5 9
## 6 4# NAs entfernen (tidyverse)
d2 <- d1 %>%
drop_na()
# Prüfen, ob noch NAs vorhanden sind
colSums(is.na(d2))## year cntry internet_nutzung
## 0 0 0
## alter bildungsstand weiblich
## 0 0 0
## happy
## 0## year cntry internet_nutzung
## 0 0 0
## alter bildungsstand weiblich
## 0 0 0
## happy
## 0Wir sehen, dass keine fehlenden Werte mehr im Datensatz vorhanden sind und die Anzahl der Beobachtungen reduziert wurde.
2.4.7 Die Funktionen group_by() und summarize()
Zwei der nützlichsten Befehle in R für zusammenfassende Statistiken sind group_by() und summarize().
group_by() hilft uns, wenn wir kategoriale Variablen mit mehreren Beobachtungen haben und eine Kennzahl für diese Gruppe berechnen möchten. Der geladene ESS hat beispielsweise 9000 Befragte, die nach ihrem Glücksempfinden gefragt wurden. Stellt euch vor, ihr seid daran interessiert, das durchschnittliche Glücksempfinden von Männern und Frauen zu berechnen. Die group_by()-Funktion legt die Gruppen fest, über die aggregiert werden soll – z. B. Geschlecht.
2.4.7.1 Mit einer Gruppierungsvariablen und einer Kennzahl
summarize() legt die Kennzahl fest, die wir berechnen möchten. Zum Beispiel wollen wir den Mittelwert des Glücksempfindens von Männern und Frauen berechnen. Oder den Median. Schauen wir uns das an:
Zunächst rufen wir
group_by()auf und definieren die Gruppe, über die aggregiert werden soll. In unserem Beispiel möchten wir nach Geschlecht aggregieren. Zuvor müssen wir fehlende Werte entfernen oder die Variable in die gewünschten Kategorien umwandeln – daher rufen wir zuerstmutate()auf und transformieren die Variable.Dann rufen wir
summarize()auf und definieren den Namen der neuen Spalte – nennen wir siedurchschnitt_happiness. Dann rufen wir die Kennzahl der gewünschten Variable auf. In unserem Beispiel interessiert uns der Durchschnitt, alsomean()mit derhappy-Variable:
# group_by und summarize
d1 <- ess %>%
mutate(
gndr_fac = as.factor(gndr),
weiblich = case_when(
gndr_fac == 1 ~ "männlich",
gndr_fac == 2 ~ "weiblich",
gndr_fac == 9 ~ NA_character_
)) %>%
drop_na() %>%
group_by(weiblich) %>%
dplyr::summarize(duchschnitt_happiness = mean(happy))
# Überprüfen
head(d1)## # A tibble: 2 × 2
## weiblich duchschnitt_happiness
## <chr> <dbl>
## 1 männlich 7.17
## 2 weiblich 6.54Et voilà – wir erhalten einen Datensatz mit zwei Beobachtungen, da wir nur zwei Gruppen haben. Die zweite Spalte ist die durchschnitt_happiness-Spalte, die wir in summarize() definiert haben.
2.4.7.2 Mit mehreren Gruppierungsvariablen und Kennzahlen
group_by() und summarize() sind natürlich viel flexibler. Zum Beispiel können wir mehrere Gruppen definieren. Was wäre, wenn wir das Glücksempfinden von Frauen und Männern in den verschiedenen ESS-Ländern untersuchen möchten? Einfach die Ländervariable und die Geschlechtsvariable in group_by() aufnehmen. Wenn uns außerdem mehrere Kennzahlen interessieren – kein Problem, einfach weitere Spalten in summarize() definieren. Auch hier müssen wir die Daten zunächst bereinigen.
# Gruppieren und zusammenfassen
d1 <- ess %>%
mutate(
land = cntry,
gndr_fac = as.factor(gndr),
weiblich = case_when(
gndr_fac == 1 ~ "männlich",
gndr_fac == 2 ~ "weiblich",
gndr_fac %in% c(77, 88, 99) ~ NA_character_),
alter = case_when(
agea == 999 ~ NA_real_,
TRUE ~ agea)
) %>%
drop_na() %>%
group_by(land, weiblich) %>%
dplyr::summarize(durchschnitt_happiness = mean(happy),
median_happiness = median(happy),
durchschnitt_alter = mean(alter),
median_alter = median(alter))## `summarise()` has regrouped the output.
## ℹ Summaries were computed grouped by land and weiblich.
## ℹ Output is grouped by land.
## ℹ Use `summarise(.groups = "drop_last")` to silence this
## message.
## ℹ Use `summarise(.by = c(land, weiblich))` for per-operation
## grouping (`?dplyr::dplyr_by`) instead.## # A tibble: 6 × 6
## # Groups: land [3]
## land weiblich durchschnitt_happiness median_happiness
## <chr> <chr> <dbl> <dbl>
## 1 BE männlich 7.79 6
## 2 BE weiblich 6.14 6
## 3 BG männlich 8.69 6
## 4 BG weiblich 6.26 6
## 5 CH männlich 5.72 5.5
## 6 CH weiblich 7.17 5
## # ℹ 2 more variables: durchschnitt_alter <dbl>,
## # median_alter <dbl>2.5 Datensätze zusammenführen
2.5.1 Einführung ins Mergen mit dplyr und Datenvorbereitung
Manchmal kann es vorkommen, dass man Variablen benötigt, die nicht in einem einzigen Datensatz vorhanden sind, sondern in einem anderen. In diesem Fall lädt man beide Datensätze und verbindet sie miteinander. Das funktioniert nur, wenn eine ähnliche Datenstruktur vorhanden ist – also kennt eure Daten!
Als Beispiel zeige ich, wie das mit Weltbank-Daten funktioniert. Aus diesen Daten lassen sich nahezu alle wichtigen wirtschaftlichen Indikatoren für Länder seit den 1970er Jahren abrufen. Meistens müssen diese jedoch mit Datensätzen zusammengeführt werden, die uns interessieren. Wir werden die Weltbank-Daten mit den ESS-Daten zusammenführen, sodass wir Variablen analysieren können, die nicht im selben Datensatz erhoben wurden.
Es gibt verschiedene Möglichkeiten, Weltbank-Daten zu beziehen. Ich zeige euch die effizienteste: das Paket WDI, mit dem Daten direkt über eine API (Application Programming Interface) abgerufen werden können. Kurz gesagt: Wir müssen nichts herunterladen und erhalten die Daten direkt per Code.
Zunächst definieren wir, welche Länder einbezogen werden sollen:
Dann legen wir fest, welche Variablen wir möchten. Das geschieht über den offiziellen Indikator – also den Variablennamen. Die Indikatoren sind auf der Website der Weltbank zu finden. Einfach auf die gewünschte Variable klicken, dann auf Details, und dort ist der Indikator angegeben. Ich verwende BIP pro Kopf, Kraftstoffexporte und CO2-Emissionen (kt).
Jetzt sind wir bereit, die API zu verwenden:
Wir rufen die
WDI()-Funktion auf.Mit dem Argument
countrylegen wir fest, welche Länder einbezogen werden sollen.Wir definieren auch die Indikatoren.
Mit dem Argument
start =definieren wir das Startjahr, bis zu dem Daten zurückreichen sollen, und mitend =das Endjahr. Beide Argumente legen den Zeitraum fest.
# wb <- WDI(
# country = countries,
# indicator = indicator,
# start = 2020,
# end = 2020)
# Das kann eine Weile dauern, besonders bei mehr Ländern, mehr Indikatoren und längeren Zeiträumen.
# Daten simulieren
wb <- data.frame(
iso2c = c("BE", "BG", "CH", "EE", "FR", "GB"),
NY.GDP.PCAP.CD = c(45587.97, 10148.34, 85897.78, 23565.18, 39179.74, 40217.01),
TX.VAL.FUEL.ZS.UN = c(5.021, 4.644, 0.6111, 4.863, 1.886, 7.062),
EN.ATM.CO2E.KT = c(85364.10, 34138.10, 34916.10, 7097.52, 267154.70, 308650.30)
)
# Überprüfen
head(wb)## iso2c NY.GDP.PCAP.CD TX.VAL.FUEL.ZS.UN EN.ATM.CO2E.KT
## 1 BE 45587.97 5.0210 85364.10
## 2 BG 10148.34 4.6440 34138.10
## 3 CH 85897.78 0.6111 34916.10
## 4 EE 23565.18 4.8630 7097.52
## 5 FR 39179.74 1.8860 267154.70
## 6 GB 40217.01 7.0620 308650.30Bereinigen wir den Datensatz (nur benötigte Variablen, alphabetisch sortiert, umbenannt und eine Variable gerundet, um die Zahlen verständlicher zu machen):
# Weltbank-Daten bereinigen
wb <- wb %>%
select(iso2c, NY.GDP.PCAP.CD, TX.VAL.FUEL.ZS.UN, EN.ATM.CO2E.KT) %>%
arrange(iso2c) %>%
rename(bip_pro_kopf = NY.GDP.PCAP.CD,
öl_exp = TX.VAL.FUEL.ZS.UN,
co2 = EN.ATM.CO2E.KT) %>%
mutate(öl_exp = round(öl_exp, 2))
# Überprüfen
head(wb)## iso2c bip_pro_kopf öl_exp co2
## 1 BE 45587.97 5.02 85364.10
## 2 BG 10148.34 4.64 34138.10
## 3 CH 85897.78 0.61 34916.10
## 4 EE 23565.18 4.86 7097.52
## 5 FR 39179.74 1.89 267154.70
## 6 GB 40217.01 7.06 308650.30Jetzt bereiten wir unsere ESS-Daten vor: Wir wählen die interessierenden Länder aus, benennen die Ländervariable um (der Grund wird später klar), gruppieren nach Land (iso2c) und Jahr, um das durchschnittliche Glücksempfinden pro Land zu berechnen. Abschließend runden wir den Wert auf zwei Dezimalstellen.
# ESS vorbereiten
d1 <- ess %>%
filter(cntry == c("BE", "BG", "CZ", "EE", "FI")) %>%
rename(iso2c = cntry) %>%
group_by(iso2c, year) %>%
summarise(happy_agg = round(mean(happy), 2))
# Überprüfen
head(d1) ## # A tibble: 5 × 3
## # Groups: iso2c [5]
## iso2c year happy_agg
## <chr> <dbl> <dbl>
## 1 BE 2020 7.53
## 2 BG 2020 6.41
## 3 CZ 2020 7.08
## 4 EE 2020 8.52
## 5 FI 2020 7.512.5.2 left_join() und right_join() mit einem Identifikator
Zum Zusammenführen von Daten gibt es wichtige Funktionen aus dem dplyr-Paket: left_join() und right_join(). Da sie etwas komplex zu verstehen sind, gehen wir sie gemeinsam durch – am Ende könnt ihr die bevorzugte Methode wählen.
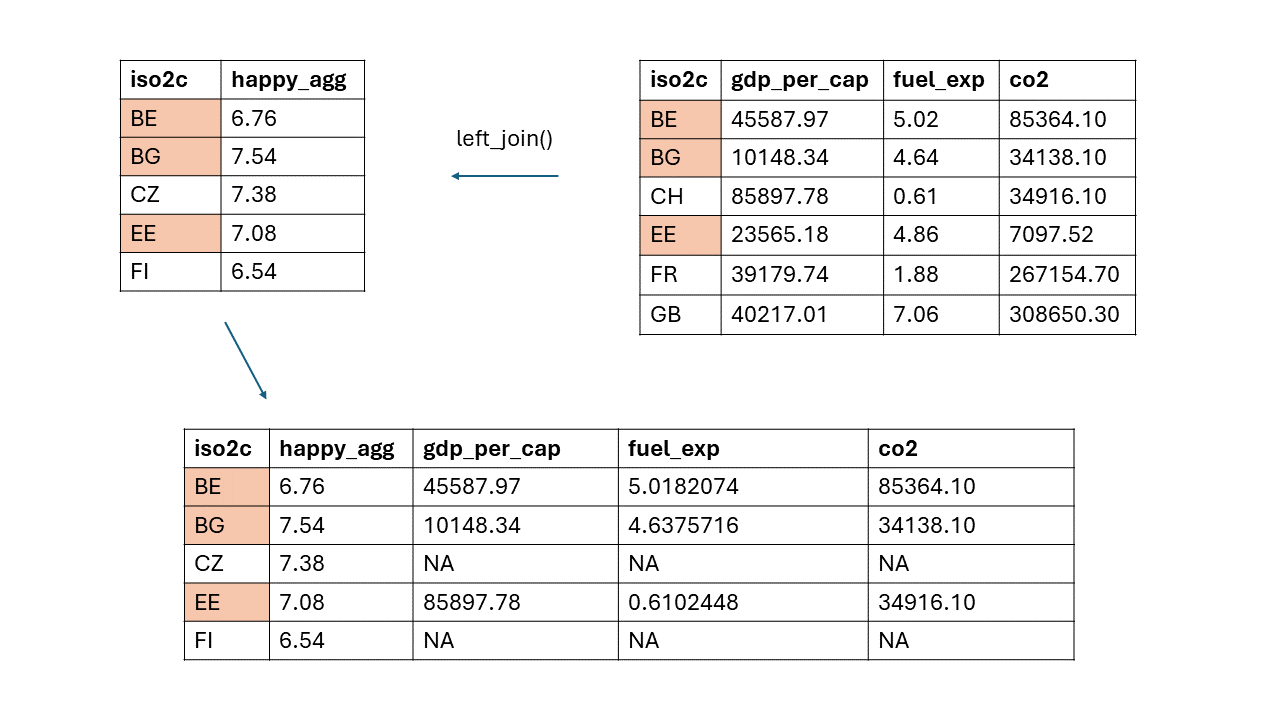
left_join(): Alle Beobachtungen der ersten (linken) Tabelle werden beibehalten, einschließlich passender Beobachtungen der zweiten (rechten) Tabelle. Die Daten aus der rechten Tabelle werden an die linke Tabelle angehängt. Der resultierende Datensatz hat dieselbe Zeilenanzahl wie die linke Tabelle:
right_join(): Alle Beobachtungen der zweiten (rechten) Tabelle werden beibehalten, einschließlich passender Beobachtungen der ersten (linken) Tabelle. Die Tabelle übernimmt die Zeilenanzahl der rechts verbundenen Tabelle.
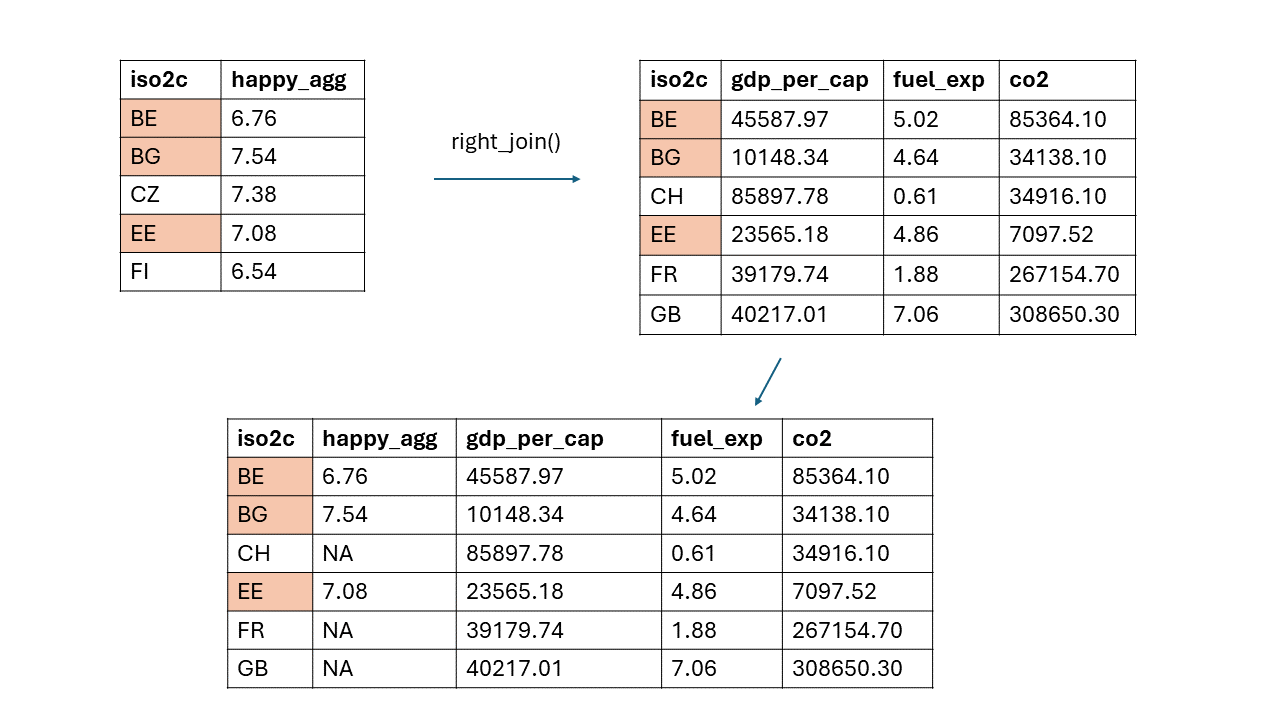
Letztlich ist es eine Frage der Programmiergewohnheit und des persönlichen Geschmacks. Ich zeige euch beide.
Um zwei Datensätze zusammenzuführen, benötigt man mindestens eine gemeinsame Variable als eindeutigen Identifikator. Da jedes Land einmalig im Datensatz ist, dient es als Identifikator – also die Variable, anhand derer R die Datensätze zusammenführt:
Zunächst definieren wir ein neues Objekt
merged_data.Dann rufen wir
left_join()auf.Wir legen die linke und die rechte Tabelle fest.
Wir definieren das
by =-Argument mit dem eindeutigen Identifikator in Anführungszeichen.
Für right_join() geht man genauso vor – aber man erhält ein anderes Ergebnis.
## # A tibble: 6 × 6
## # Groups: iso2c [6]
## iso2c year happy_agg bip_pro_kopf öl_exp co2
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 BE 2020 7.53 45588. 5.02 85364.
## 2 BG 2020 6.41 10148. 4.64 34138.
## 3 EE 2020 8.52 23565. 4.86 7098.
## 4 CH NA NA 85898. 0.61 34916.
## 5 FR NA NA 39180. 1.89 267155.
## 6 GB NA NA 40217. 7.06 308650.2.5.3 left_join() und right_join() mit zwei Identifikatoren
Manchmal gibt es mehrere Dimensionen. Was, wenn wir auch das Jahr einbeziehen? Dann ist jede Länder-Jahr-Beobachtung unser eindeutiger Identifikator. Warum? Weil eine Beobachtung im Land X zum Zeitpunkt Y erhoben wurde. Deshalb sollte man immer seine Daten und sein Forschungsziel kennen – entsprechend muss der Code geschrieben werden.
Laden wir erneut Weltbank-Daten und bereinigen sie:
# wb <- WDI(
# country = c("BE", "BG"),
# indicator = indicators,
# start = 2019,
# end = 2020)
# Daten simulieren
wb <- data.frame(
iso3c = c("BEL", "BEL", "BGR", "BGR"),
iso2c = c("BE", "BE", "BG", "BG"),
jahr = c(2019, 2020, 2019, 2020),
NY.GDP.PCAP.CD = c(46641.72, 45587.97, 9874.336, 10148.34),
TX.VAL.FUEL.ZS.UN = c(7.38, 5.02, 9.53, 4.64),
EN.ATM.CO2E.KT = c(92989.4, 85364.10, 39159.9, 34138.10)
)
# Daten bereinigen
wb <- wb %>%
select(-iso3c) %>%
arrange(iso2c) %>%
rename(bip_pro_kopf = NY.GDP.PCAP.CD,
öl_exp = TX.VAL.FUEL.ZS.UN,
co2 = EN.ATM.CO2E.KT) %>%
mutate(öl_exp = round(öl_exp, 2))
# Überprüfen
head(wb)## iso2c jahr bip_pro_kopf öl_exp co2
## 1 BE 2019 46641.720 7.38 92989.4
## 2 BE 2020 45587.970 5.02 85364.1
## 3 BG 2019 9874.336 9.53 39159.9
## 4 BG 2020 10148.340 4.64 34138.1Jetzt simulieren wir einige Daten, die wir zusammenführen möchten:
# Daten erstellen
d1 <- data.frame(
iso2c = c("BE", "BE", "BG", "BG", "CZ", "CZ"),
jahr = c(2019, 2020, 2019, 2020, 2019, 2020),
happy_agg = c(5.95, 6.76, 6.56, 7.54, 6.27, 6.88)
)
# Überprüfen
head(d1)## iso2c jahr happy_agg
## 1 BE 2019 5.95
## 2 BE 2020 6.76
## 3 BG 2019 6.56
## 4 BG 2020 7.54
## 5 CZ 2019 6.27
## 6 CZ 2020 6.88Wie sieht es aus, wenn wir zwei Variablen haben und deren Kombination der eindeutige Identifikator ist?
left_join()mit zwei Identifikatoren:
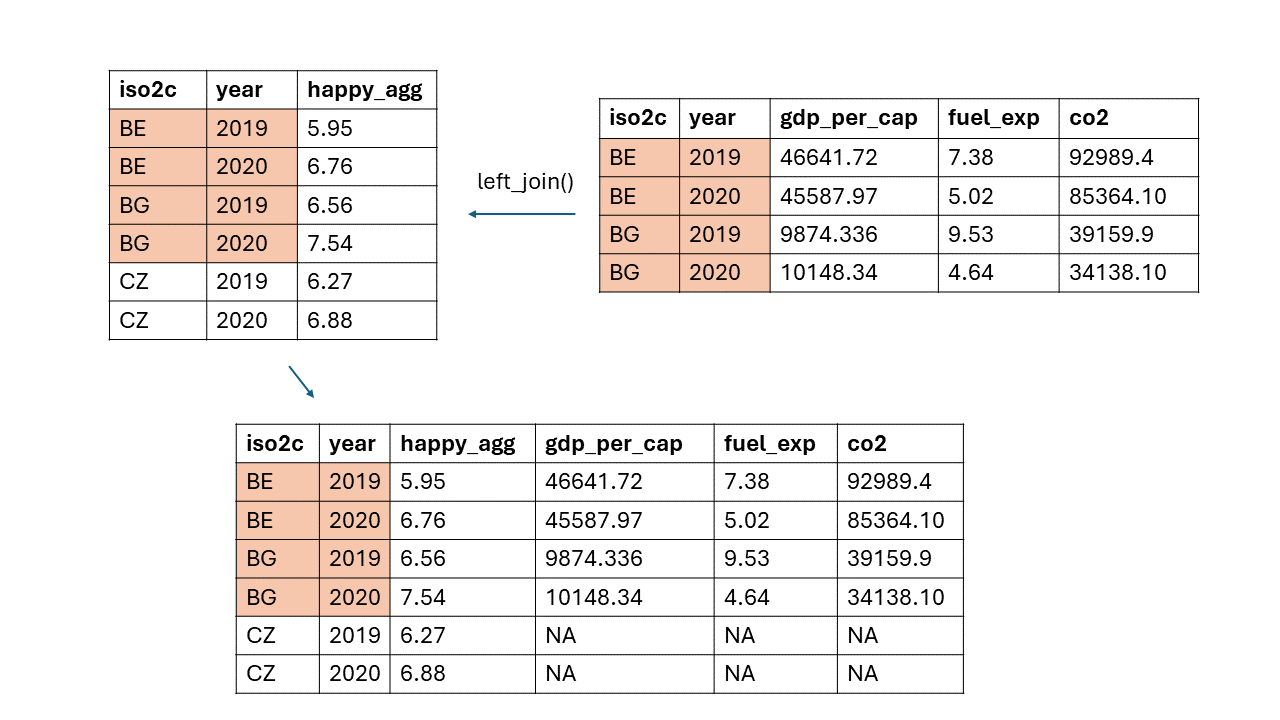
Der Datensatz übernimmt wieder die Zeilenanzahl der linken Tabelle.
Im Code muss das
by-Argument angepasst werden: Wir definieren einen Vektor mit unseren zwei Identifikatoren in Anführungszeichen:
# Daten mit left_join() zusammenführen
merged_data3 <- left_join(d1, wb,
by = c("iso2c", "jahr"))
# Überprüfen
head(merged_data3)## iso2c jahr happy_agg bip_pro_kopf öl_exp co2
## 1 BE 2019 5.95 46641.720 7.38 92989.4
## 2 BE 2020 6.76 45587.970 5.02 85364.1
## 3 BG 2019 6.56 9874.336 9.53 39159.9
## 4 BG 2020 7.54 10148.340 4.64 34138.1
## 5 CZ 2019 6.27 NA NA NA
## 6 CZ 2020 6.88 NA NA NAright_join()mit zwei Identifikatoren:
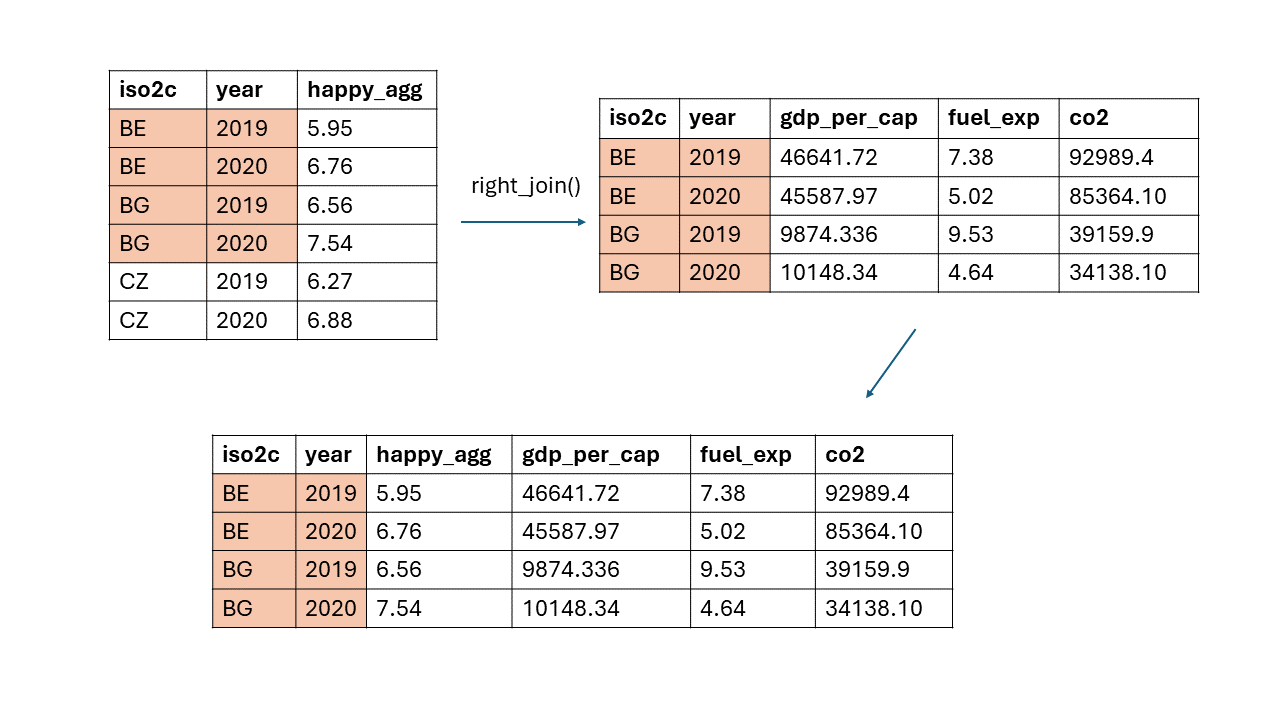
- Dasselbe geht mit
right_join():
## iso2c jahr happy_agg bip_pro_kopf öl_exp co2
## 1 BE 2019 5.95 46641.720 7.38 92989.4
## 2 BE 2020 6.76 45587.970 5.02 85364.1
## 3 BG 2019 6.56 9874.336 9.53 39159.9
## 4 BG 2020 7.54 10148.340 4.64 34138.1Hinweis: Dieses Kapitel hat nur die Grundlagen behandelt. Für das Zusammenführen allein gibt es noch weitere Befehle wie
inner_join(),anti_join(),semi_join()usw. Aber wenn man mit den beiden hier gezeigten Funktionen auf Probleme stößt, wird man ihnen früher oder später begegnen.
2.6 Ausblick
Dieses Kapitel hat euch die grundlegenden Funktionen des dplyr-Pakets vorgestellt. Ihr könnt nun Variablen nach euren Bedürfnissen transformieren, Pipes für effizienten Code nutzen, Daten laden, transformieren und für die Analyse vorbereiten sowie Datensätze zusammenführen. Es gibt viele Techniken, und Data Wrangling ist der aufwändigste Teil – weil jede Analyse individuell ist und eine individuelle Vorbereitung erfordert. Je individueller die Analyse, desto individueller die Vorbereitung.
- Für dieses Kapitel empfehle ich das Standardwerk zur Datenwissenschaft in R, das einen starken Schwerpunkt auf Datenmanipulation legt: „R for Data Science” von Hadley Wickham & Garrett Grolemund.
2.7 Übungsaufgaben
2.7.1 Übung 1: Ran an die Daten!
Du interessierst dich für Diskriminierung und die Wahrnehmung der Justiz. Genauer gesagt möchtest du wissen, ob Menschen, die sich diskriminiert fühlen, Gerichte anders bewerten. In der folgenden Tabelle siehst du alle Variablen, die du in deine Analyse einbeziehen möchtest:
(Tabelle wie im Kapiteltext oben – Variablen idnt, year, cntry, agea, gndr, happy, eisced, netusoft, trstprl, lrscale)
- Bereinige die Daten und weise sie einem Objekt namens
ess2zu. - Wähle die benötigten Variablen aus.
- Filtere nach Österreich, Belgien, Dänemark, Georgien, Island und der Russischen Förderation.
- Schau dir das Codebuch an und kodiere alle irrelevanten Werte als fehlend. Bei binären Variablen rekodiere von 1, 2 zu 0 und 1.
- Erstelle eine Extremismus-Variable: Subtrahiere 5 von der Variable und quadriere das Ergebnis. Nenne sie
extremism. - Benenne die Variablen intuitiver um. Vergiss nicht, binäre Variablen nach der Kategorie zu benennen, die mit 1 kodiert ist.
- Entferne alle fehlenden Werte.
- Schau dir deinen neuen Datensatz an.
2.7.2 Übung 2: Datensätze zusammenführen
Das gapminder-Paket in R lädt automatisch den Gapminder-Datensatz. Das Gapminder-Projekt ist eine unabhängige gemeinnützige Bildungsorganisation, die globale Missverständnisse bekämpft. Weitere Infos auf der Website: https://www.gapminder.org/. Der Gapminder-Datensatz ist bereits geladen.
- Verschaffe dir einen Überblick über den Gapminder-Datensatz. Es gibt verschiedene Möglichkeiten – du kannst selbst wählen.
Lade Weltbank-Daten von 1972 bis 2007 und die Variable „Exporte und Waren (% des BIP)“.
Verbinde die Weltbank-Daten mit den Gapminder-Daten, sodass ein Datensatz mit der Zeilenanzahl der Gapminder-Daten entsteht. Weise den neuen Datensatz dem Objekt
gap_mergedzu.
d. Bereinige die Daten, indem du alle fehlenden Werte entfernst.