Chapter 3 Datenvisualisierung
In diesem Kapitel stelle ich dir den meiner Meinung nach spannendsten Teil in R vor: die Datenvisualisierung. Ich werde dir die grundlegenden Diagrammtypen zeigen und erklären, wie man sie in R erstellt. Dafür stelle ich dir das Framework ggplot2 vor. Dieses ist ein sehr bekanntes und leistungsfähiges Paket und hat sich zum Standardpaket für Datenvisualisierung in R entwickelt.
Das Ziel dieses Kapitels ist es:
- die grundlegenden Diagrammtypen kennenzulernen,
- zu lernen, wie man ansprechende Grafiken für wissenschaftliche Arbeiten und Berichte erstellt,
- und den Umgang mit dem Paket
ggplot2zu verstehen.
pacman::p_load("tidyverse", "babynames", "sf", "ggridges",
"rnaturalearth", "rnaturalearthdata" ,"forcats" ,"tmap")3.1 Einführung in ggplot2
Das tidyverse enthält eines der beliebtesten Pakete zur Datenvisualisierung in R: ggplot2. Durch seine relativ einfache Syntax und seine enorme Flexibilität – und damit meine ich wirklich enorme Flexibilität – ist es zur Standardlösung für Datenvisualisierung geworden.
ggplot2 basiert auf dem Konzept der Grammar of Graphics, das von Leland Wilkinson entwickelt wurde. Auch wenn der Ansatz zunächst komplex erscheinen kann, folgt er einer einfachen Logik:
- Es wird zunächst ein Grundgerüst (Frame) erstellt.
- Anschließend werden Elemente schrittweise hinzugefügt.
Schauen wir uns zuerst die Grundstruktur an und erstellen ein leeres Diagramm. Der zentrale Befehl dafür ist ggplot():

Wie wir sehen können, erhalten wir ein leeres Diagramm. In den folgenden Abschnitten werden wir verschiedene Visualisierungen erstellen, indem wir diesem Rahmen schrittweise neue Elemente hinzufügen.
Das ist allerdings nur ein kleiner Teil dessen, was mit Datenvisualisierung in R möglich ist. Ich empfehle sehr, sich intensiver mit diesem Thema zu beschäftigen. R ist bekannt für besonders schöne und flexible Visualisierungen, was auch ein wichtiger Grund für seine Popularität ist.
3.2 Verteilungen: Histogramme, Dichteplots und Boxplots
Die erste Gruppe von Visualisierungen zeigt Verteilungen von Variablen.
Es ist immer sinnvoll, sich zunächst einen Überblick darüber zu verschaffen, wie Variablen verteilt sind, da dies wichtige Informationen über die Struktur der Daten liefert.
Beispiele:
- Viele statistische Modelle setzen bestimmte Verteilungen voraus.
- Verteilungen helfen dabei zu erkennen, ob diese Annahmen erfüllt sind.
- Außerdem lassen sich Ausreißer oder Verzerrungen leicht erkennen.
3.2.1 Histogramme
3.2.1.1 Einfaches Histogramm
Beginnen wir mit einem normalen Histogramm.
Ein Histogramm ist eine grafische Darstellung der Verteilung einer numerischen Variable. Dabei wird der Wertebereich in sogenannte Bins (Intervalle) unterteilt. Die Höhe der Balken zeigt, wie viele Beobachtungen in einem Intervall liegen.
Bevor wir unser erstes Diagramm erstellen, simulieren wir zunächst einige Daten:
#Setting Seed for reproducibility
set.seed(123)
#Simulating data
data1 <- data.frame(
typ = c(rep("Variable 1", 1000)),
wert = c(rnorm(1000))
)
#Looking at the data
glimpse(data1)## Rows: 1,000
## Columns: 2
## $ typ <chr> "Variable 1", "Variable 1", "Variable 1", "Vari…
## $ wert <dbl> -0.56047565, -0.23017749, 1.55870831, 0.0705083…Wir haben nun einen Datensatz mit einer Zufallsvariable „Variable 1” und 500 Beobachtungen.
Nun möchten wir wissen, wie diese Werte verteilt sind, und erstellen deshalb ein Histogramm.
Für ein Histogramm mit ggplot benötigen wir zunächst den Befehl ggplot(). Danach geben wir unseren Datensatz an – in unserem Fall data. Nach einem Komma folgt die Funktion aes().
In aes() definieren wir:
- die x-Achse
- und optional die y-Achse
Bei einem Histogramm reicht jedoch die x-Achse, da ggplot die Häufigkeit (Count) automatisch berechnet.
Danach schließen wir die Klammern und geben mit einem + an, welche Art von Visualisierung wir hinzufügen möchten: geom_histogram().
## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Damit hast du dein erstes Histogramm erstellt.
Allerdings sieht es noch nicht besonders schön aus. Das liegt daran, dass wir ggplot2 noch genauer sagen müssen, wie das Diagramm aussehen soll.
Ein guter erster Schritt ist es, die Balken sichtbarer zu machen und die Farbe anzupassen.
## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Das sieht schon besser aus. Aber für einen wissenschaftlichen Artikel oder Bericht reicht das noch nicht aus.
Als nächstes sollten wir:
- die Achsenbeschriftungen anpassen
- einen Titel hinzufügen
Dafür verwenden wir die Funktion labs().
Zusätzlich können wir die x-Achse neu skalieren. Dafür nutzen wir scale_x_continuous().
ggplot(data1, aes(x = wert)) +
geom_histogram(color = "white", fill = "#69b3a2") +
labs(
x = "Wert",
y = "Anzahl",
title = "Ein Histogramm") +
scale_x_continuous(breaks = seq(-4, 4, 1),
limits = c(-4, 4))
Ein weiteres Detail: Viele Menschen mögen den grauen Hintergrund von ggplot2 nicht, der standardmäßig angezeigt wird.
Wir können das Theme ändern, z.B. mit theme_minimal().
ggplot(data1, aes(x = wert)) +
geom_histogram(color = "white", fill = "#69b3a2") +
labs(
x = "Wert",
y = "Anzahl",
title = "Ein Histogramm") +
scale_x_continuous(breaks = seq(-4, 4, 1),
limits = c(-4, 4)) +
theme_minimal()## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Jetzt haben wir eine Grafik, die sich problemlos in einem Bericht oder Paper verwenden lässt.
3.2.1.2 Binwidth
Ein wichtiger Parameter ist die Breite der Intervalle (binwidth).
Standardmäßig liegt sie hier bei etwa 0.3. Wir können sie jedoch selbst festlegen.
#histogram bindwidth = 0.1
ggplot(data1, aes(x = wert)) +
geom_histogram(color = "white", fill = "#69b3a2",
binwidth = 0.1) +
labs(
x = "Wert",
y = "Anzahl",
title = "Ein Histogramm mit binwidth = 0.1") +
scale_x_continuous(breaks = seq(-4, 4, 1),
limits = c(-4, 4)) +
theme_minimal()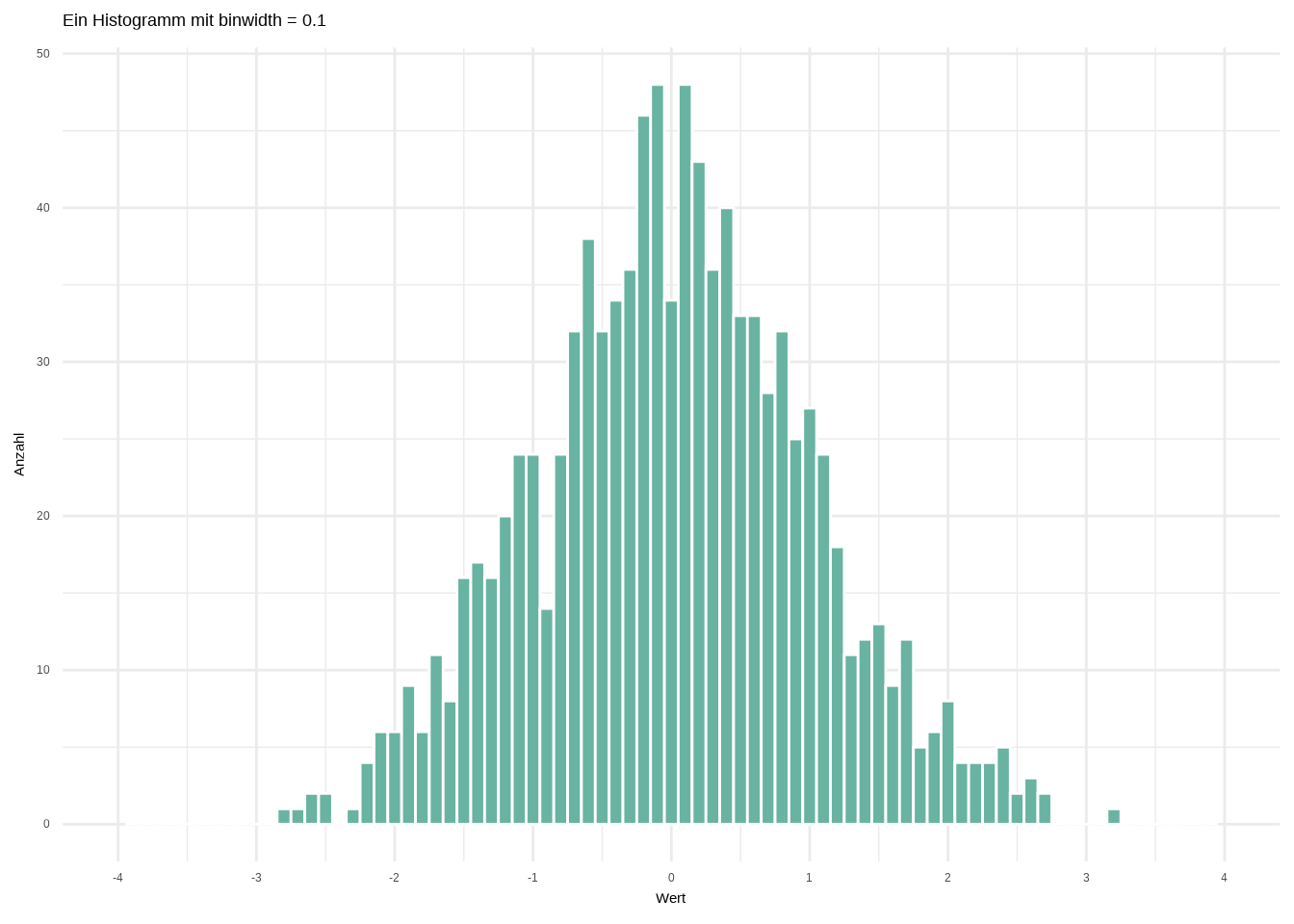
#histogram with bindwidth = 0.6
ggplot(data1, aes(x = wert)) +
geom_histogram(color = "white", fill = "#69b3a2",
binwidth = 0.6) +
labs(
x = "Wert",
y = "Anzahl",
title = "Ein Histogramm mit binwidth = 0.6") +
scale_x_continuous(breaks = seq(-4, 4, 1),
limits = c(-4, 4)) +
theme_minimal()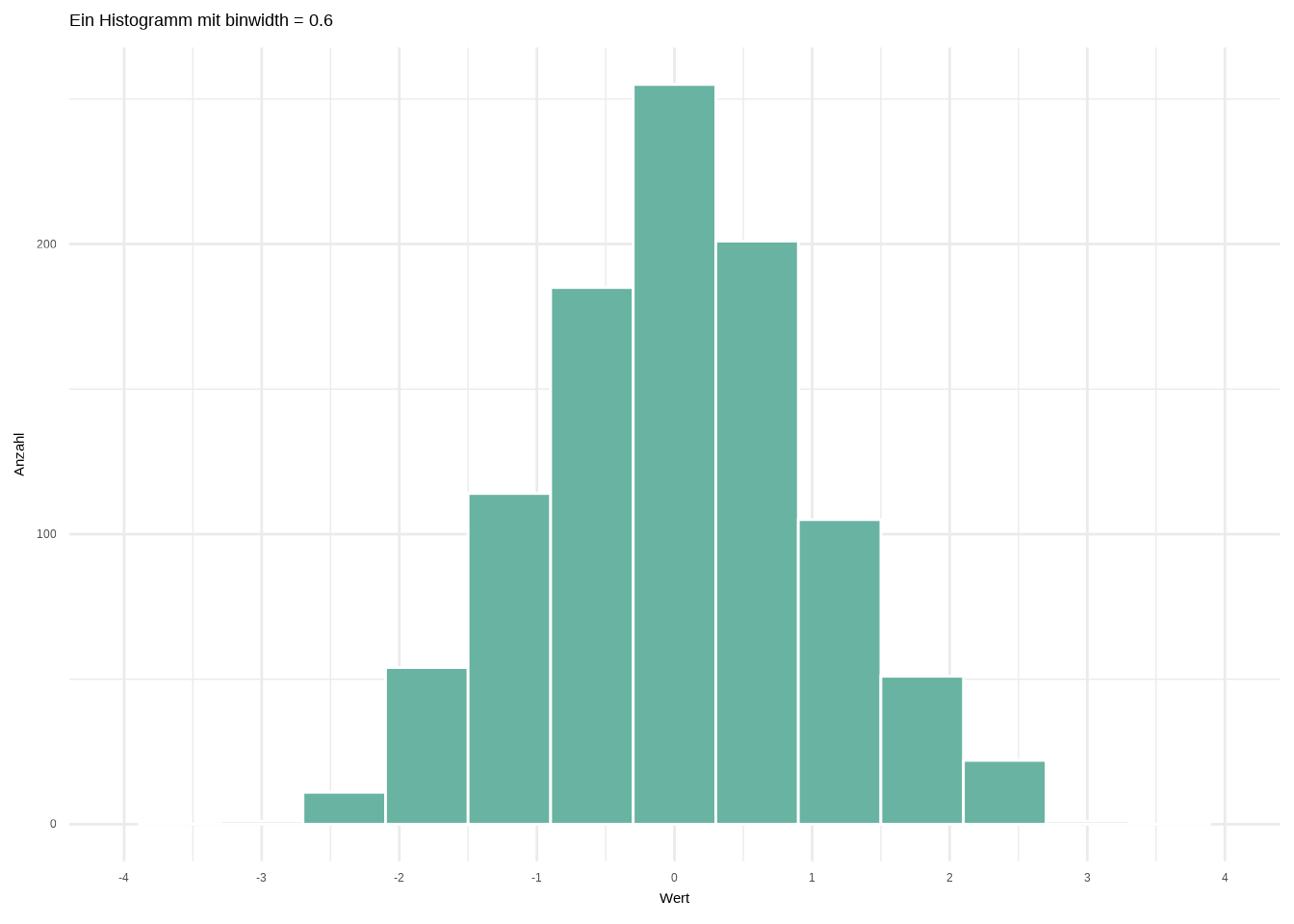
3.2.1.3 Mehrere Histogramme
Nun betrachten wir mehrere Verteilungen gleichzeitig.
Dafür erstellen wir eine zweite Variable:
#Creating data
data2 <- data.frame(
typ = c(rep("Variable 2", 1000)),
wert = c(rnorm(1000, mean = 4))
)
#rowbinding it with data1
data2 <- rbind(data1, data2)Nun müssen wir ggplot2 mitteilen, welche Werte zu welcher Variable gehören.
Das geschieht über das Argument fill innerhalb von aes().
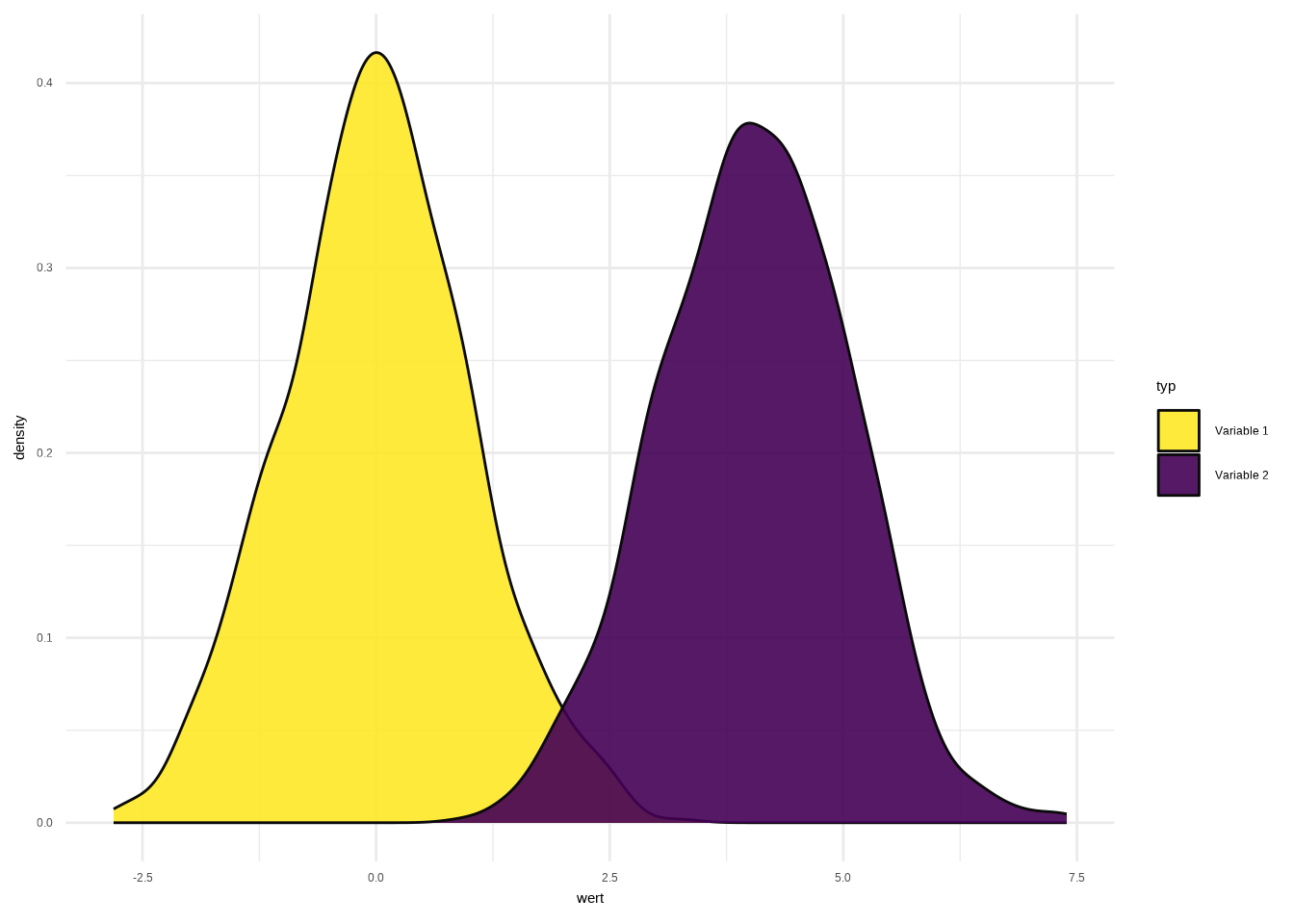
ggplot(data2, aes(x=wert, fill=typ)) +
geom_histogram(color="#e9ecef",
position = "identity") +
theme_bw() ## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.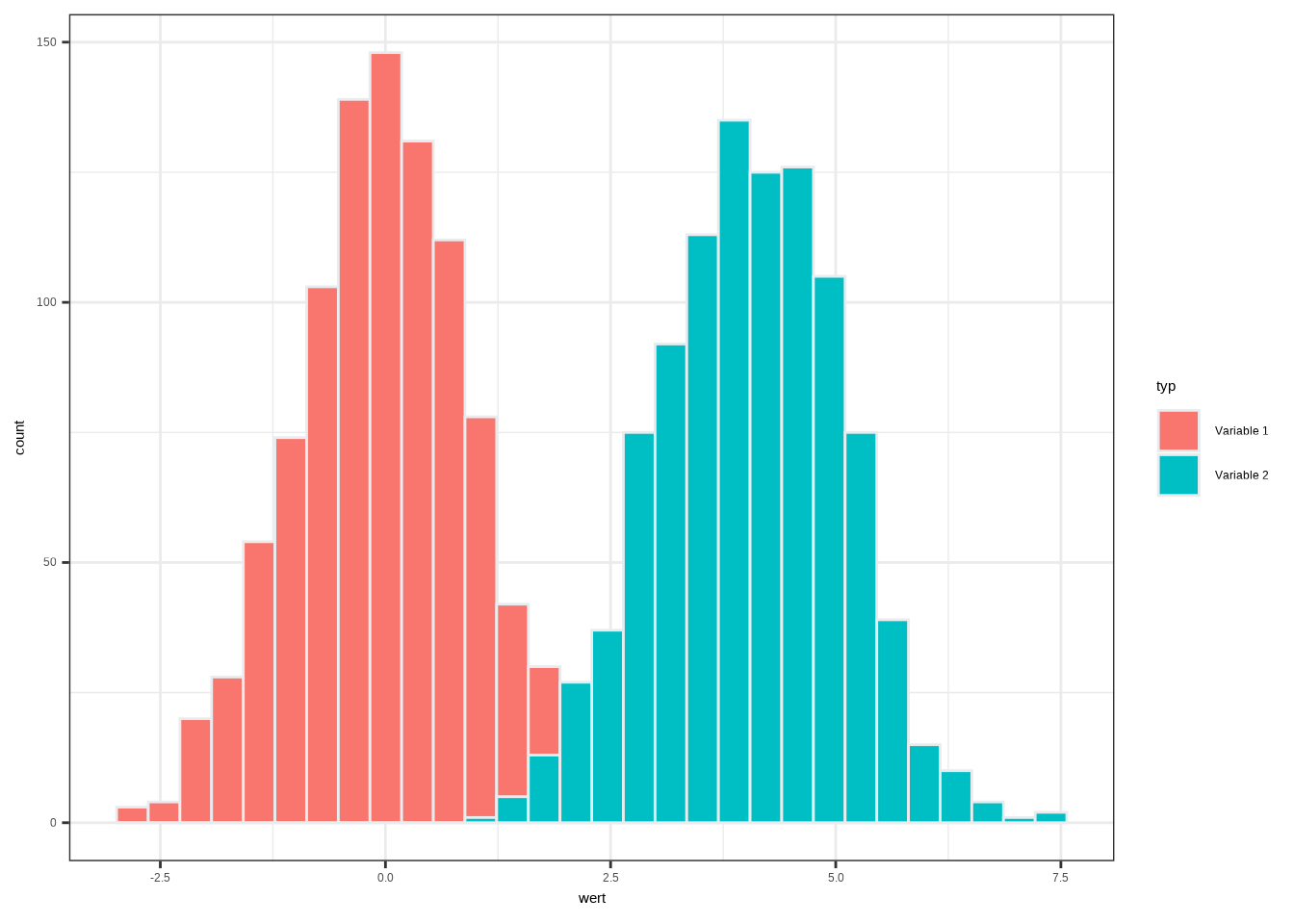
Hier sehen wir zwei Histogramme, die durch unterschiedliche Farben unterschieden werden.
Um Überlappungen besser sichtbar zu machen, können wir Transparenz (alpha) verwenden und die Farben manuell festlegen.
ggplot(data2, aes(x=wert, fill=typ)) +
geom_histogram(color="#e9ecef",
alpha = 0.6,
position = "identity") +
scale_fill_manual(values = c("#8AA4D6", "#E89149")) +
theme_bw() ## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.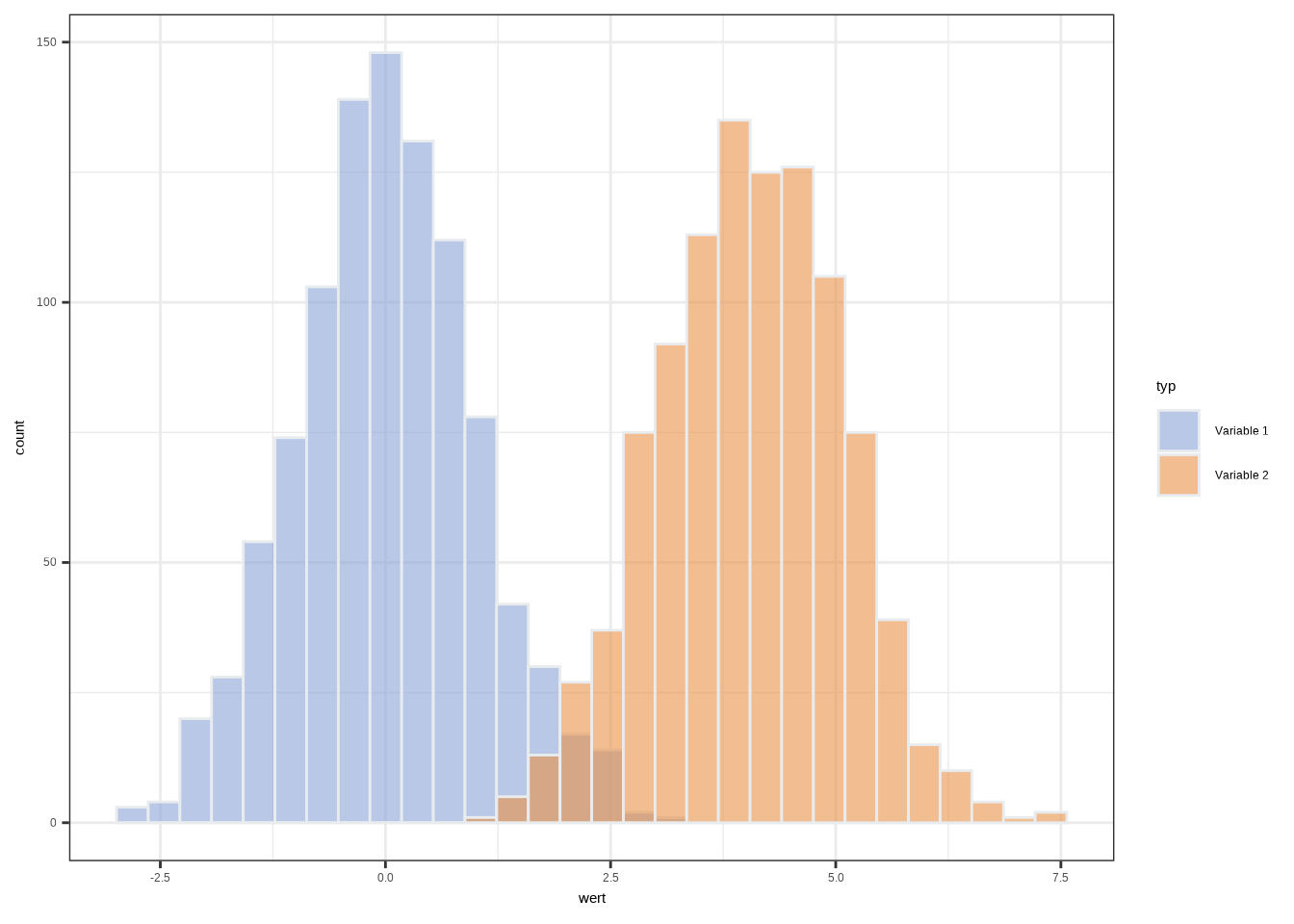
3.2.2 Dichteplots
Ein Density Plot zeigt ebenfalls die Verteilung einer numerischen Variable.
Er basiert auf einer Kernel-Dichteschätzung und kann als geglättete Version eines Histogramms verstanden werden.
Der Code ist nahezu identisch – lediglich geom_histogram() wird durch geom_density() ersetzt.
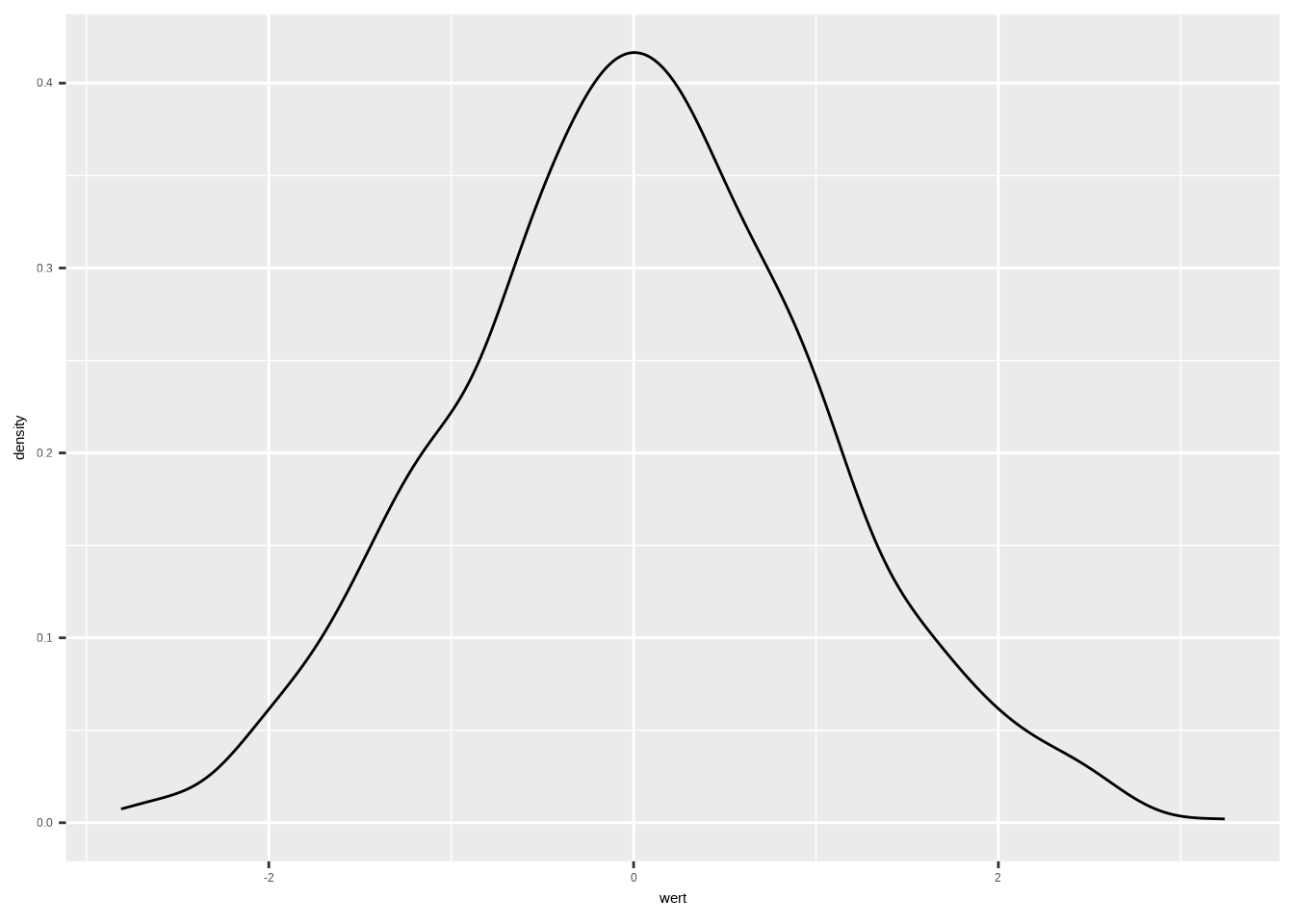
3.2.2.1 Einfacher Dichteplot
Wir können hier wieder:
- Farben anpassen
- Transparenz definieren
- Achsen beschriften
- Themes verändern
ggplot(data1, aes(x = wert)) +
geom_density(color = "white",
fill = "orange",
alpha = 0.6) +
labs(
x = "Wert",
y = "Anzahl",
title = "Ein Dichteplot") +
scale_x_continuous(breaks = seq(-4, 4, 1),
limits = c(-4, 4)) +
theme_minimal()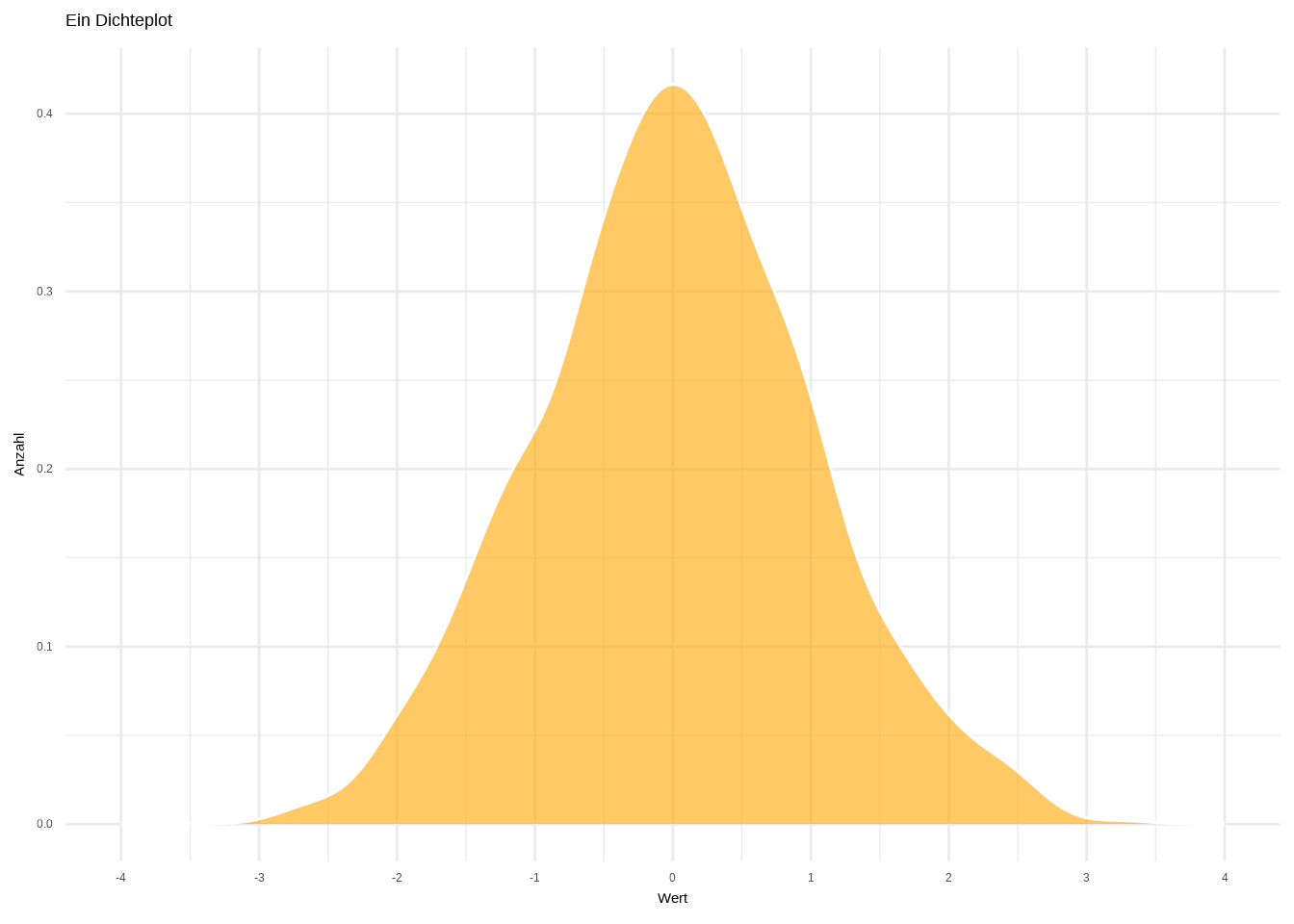
3.2.3 Boxplots
3.2.3.1 Einfache Boxplots
Die letzte Visualisierungsform für Verteilungen sind Boxplots.
Boxplots sind besonders informativ, da sie mehrere statistische Kennwerte gleichzeitig darstellen.
Schauen wir uns zunächst die Anatomie eines Boxplots an:
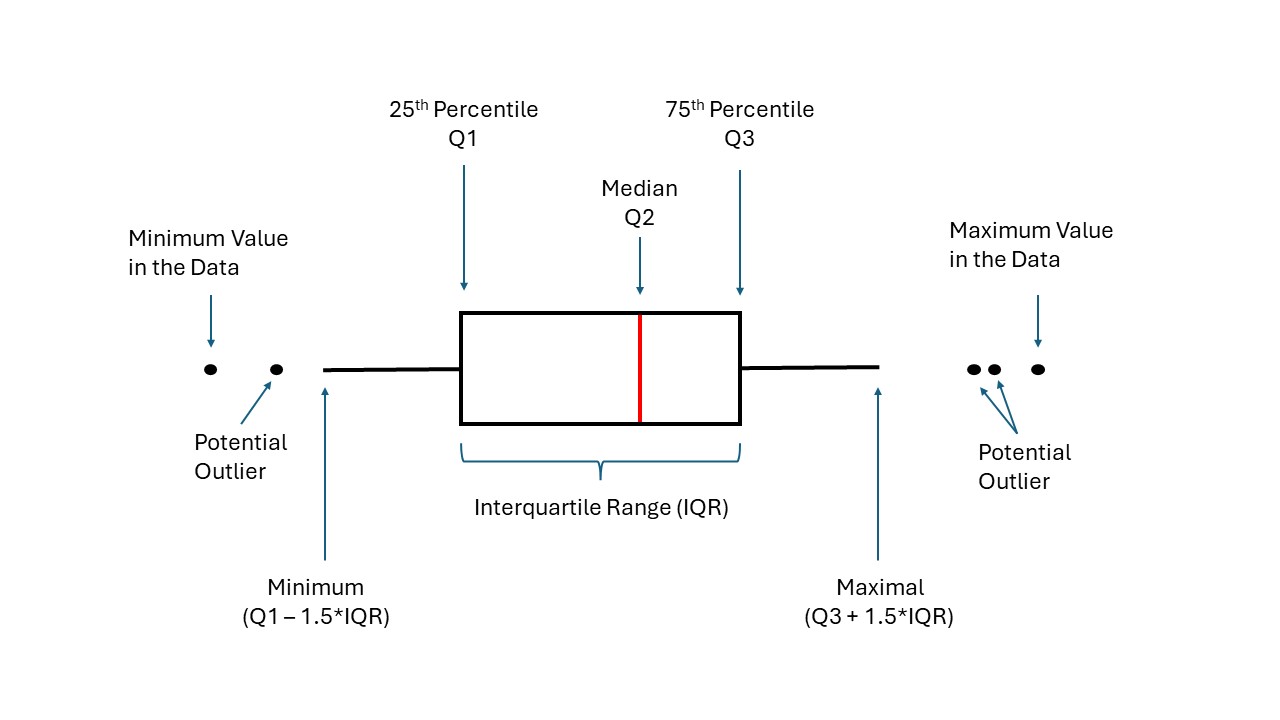
Das schwarze Rechteck repräsentiert den Interquartilsabstand (IQR), also die Differenz zwischen dem 25. und 75. Perzentil der Daten.
Die rote Linie im schwarzen Rechteck stellt den Median der Daten dar.
Die Enden der Linien zeigen den Wert beim 0. bzw. 100. Perzentil, also das Minimum und das Maximum des IQR, nicht der gesamten Daten.
Die Punkte außerhalb der schwarzen Linien sind potenzielle Ausreißer, und die Punkte an den Enden sind der minimale bzw. maximale Wert der Daten. Wir sollten auf sie achten, denn wenn wir sie ignorieren, könnten sie unsere statistischen Modelle verzerren – mehr dazu in Kapitel 6.
Implementieren wir nun einen Boxplot in R. Wieder ändert sich nur eine Kleinigkeit: Wir verwenden die Standardfunktion ggplot() und fügen anschließend die Funktion geom_boxplot() hinzu:
Auch diesen Graphen können wir mit den gleichen Techniken wie zuvor optisch verbessern:
ggplot(data1, aes(x = wert)) +
geom_boxplot() +
labs(
x = "Wert",
y = "Häufigkeit",
title = "Ein Boxplot") +
scale_x_continuous(breaks = seq(-4, 4, 1),
limits = c(-4, 4)) +
theme_classic()
3.2.3.2 Mehrere Boxplots
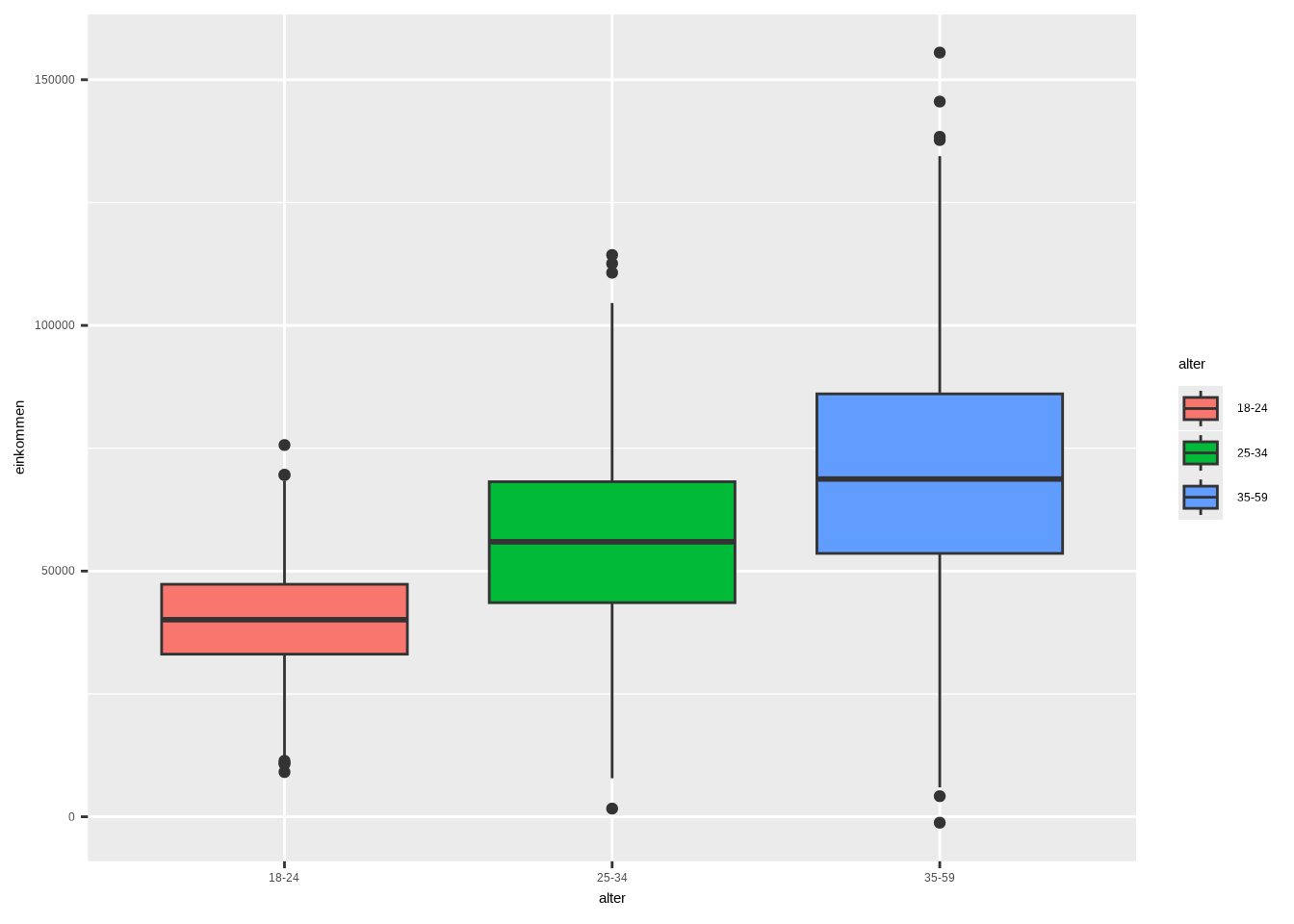
Ein großer Vorteil von Boxplots ist, dass sie eine einfache Möglichkeit bieten, die Struktur von Verteilungen verschiedener Gruppen zu vergleichen. Betrachten wir folgendes Beispiel: Wir möchten das Einkommen von Menschen mit Migrationshintergrund und Menschen ohne Migrationshintergrund vergleichen. Angenommen, wir haben eine Stichprobe von 2000 Personen erhoben, davon 1000 mit und 1000 ohne Migrationshintergrund. Außerdem haben wir das Einkommen jeder befragten Person erfasst. Beachte, dass wir nun die y-Achse mit dem Einkommen definieren müssen, da wir nicht mehr die Häufigkeit der Verteilung betrachten, sondern die Verteilung über eine andere Variable (hier: Einkommen). Schauen wir uns zunächst den Plot an:
# Reproduzierbarkeit sicherstellen
set.seed(123)
# Einkommensdaten simulieren
einkommen_18_24 <- rnorm(1000, mean = 40000, sd = 11000)
einkommen_25_34 <- rnorm(1000, mean = 55000, sd = 17500)
einkommen_35_59 <- rnorm(1000, mean = 70000, sd = 25000)
# Zu einem Dataframe zusammenfügen
data3 <- data.frame(
einkommen = c(einkommen_18_24, einkommen_25_34,
einkommen_35_59),
alter = factor(rep(c("18-24", "25-34", "35-59"),
each = 1000))
)
Bevor wir den Plot interpretieren, machen wir ihn zunächst etwas ansprechender: Wir ändern die Beschriftungen der x- und y-Achse und geben dem Plot einen Titel mit der Funktion labs(). Die Farben gefallen mir nicht besonders, deshalb ändern wir sie mit scale_fill_manual(). Außerdem setzen wir wieder alpha = 0.5 und definieren width = 0.5 für die Boxen in geom_boxplot(). Ich denke außerdem, dass wir keine Legende benötigen, daher entfernen wir sie mit der Funktion theme(). Diese Funktion ist sehr mächtig, da ihre Spezifikation uns viele Möglichkeiten bietet, den Plot nach unseren Wünschen zu gestalten. Wir legen in der theme()-Funktion fest, dass legend.position = "none" sein soll, was bedeutet, dass keine Legende angezeigt wird:
# Boxplot erstellen
ggplot(data3, aes(x = alter, y = einkommen, fill = alter)) +
geom_boxplot(alpha = 0.5, width = 0.5) +
scale_fill_manual(values = c("#acf6c8", "#ecec53" ,"#D1BC8A")) +
labs(
title = "Vergleich der Einkommensverteilung nach Altersgruppe",
x = "Alter",
y = "Einkommen"
) +
theme_minimal() +
theme(legend.position = "none")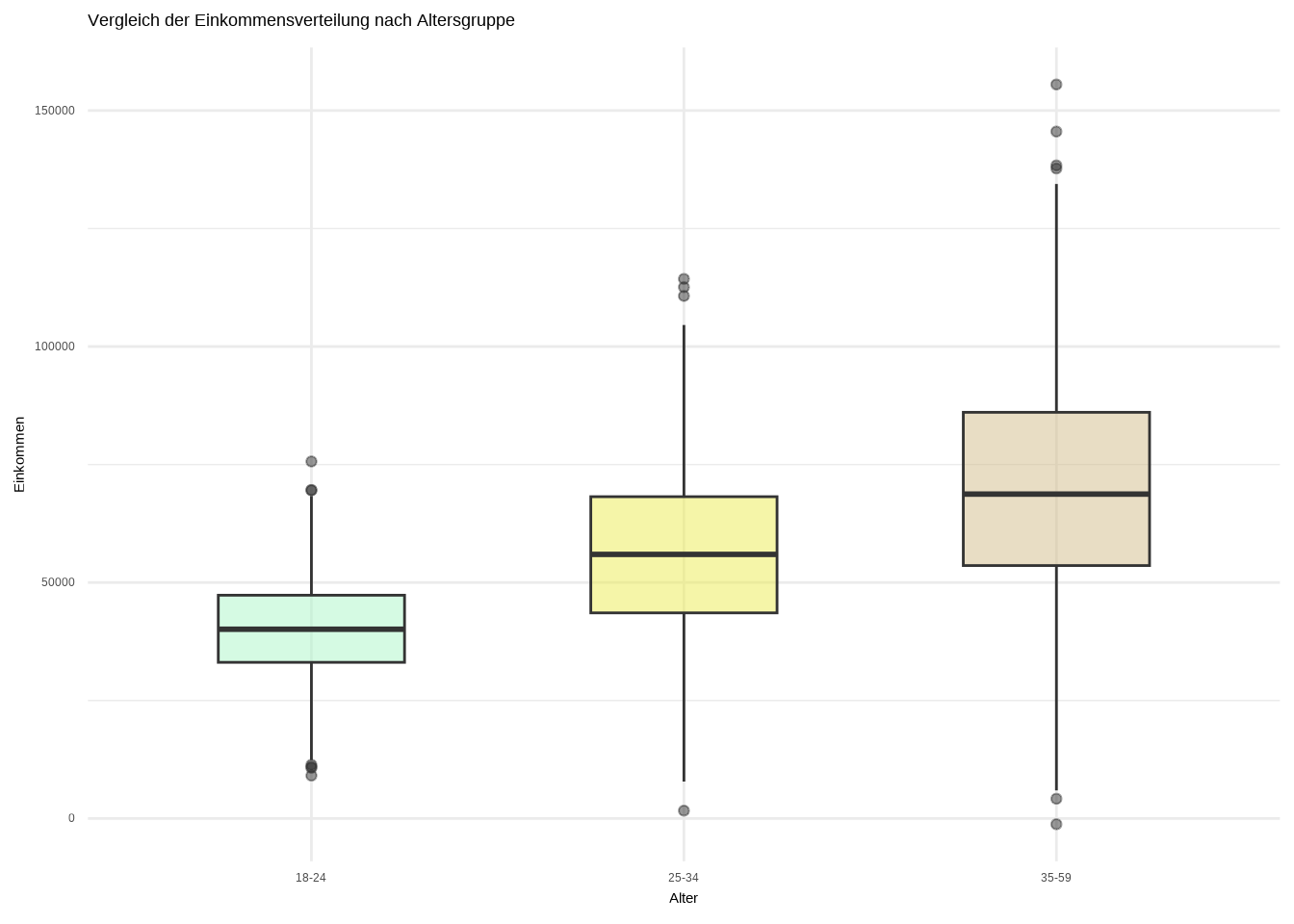
Hier erhalten wir eine Menge Informationen. Zunächst sehen wir klar, dass der Median des Einkommens von Menschen mit Migrationshintergrund niedriger ist als der Median des Einkommens von Menschen ohne Migrationshintergrund. Außerdem sehen wir, dass die Einkommensverteilung der Befragten ohne Migrationshintergrund stärker über einen größeren Bereich gestreut ist. Das erkennen wir an den längeren Linien im Boxplot der Befragten ohne Migrationshintergrund. Auch der IQR-Bereich beider Variablen unterscheidet sich. Die Box der Personen ohne Migrationshintergrund ist kleiner, was ebenfalls ein Hinweis darauf ist, dass die Werte stärker gestreut sind. Im Vergleich sehen wir, dass Befragte mit Migrationshintergrund im Bereich zwischen dem 50. und 75. Perzentil etwa so viel verdienen wie Befragte ohne Migrationshintergrund im Bereich zwischen dem 25. und 50. Perzentil.
Ich könnte den ganzen Tag so weitermachen – Boxplots sind sehr informativ und ein nützliches Werkzeug, um Verteilungsstrukturen zu untersuchen und zu vergleichen.
Hinweis: Ich habe simulierte Daten verwendet, daher sind diese Daten fiktiv.
3.3 Rangfolge: Barplot
3.3.1 Einfacher Barplot
Die bekannteste und einfachste Möglichkeit, Werte verschiedener Gruppen darzustellen, ist der Barplot. Ein Barplot (oder Balkendiagramm) ist eine der häufigsten Arten von Grafiken. Er zeigt die Beziehung zwischen einer numerischen und einer kategorialen Variable. Jede Kategorie der kategorialen Variable wird als Balken dargestellt. Die Höhe des Balkens entspricht ihrem numerischen Wert.
- In ggplot müssen wir lediglich die x-Achse und die y-Achse innerhalb der
ggplot()-Funktion definieren und anschließend die Funktiongeom_bar()hinzufügen. Innerhalb vongeom_bar()müssen wirstat = "identity"hinzufügen, aus dem einfachen Grund, dass wir ggplot2 mitteilen müssen, die Zahlen aus der Spaltestärkeanzuzeigen – andernfalls erhalten wir einen Fehler.
# Daten erstellen
data4 <- data.frame(
name=c("King Kong","Godzilla","Superman",
"Odin","Darth Vader") ,
stärke=c(10,15,45,61,22)
)
# Plotten
ggplot(data4, aes(x = name, y = stärke)) +
geom_bar(stat = "identity")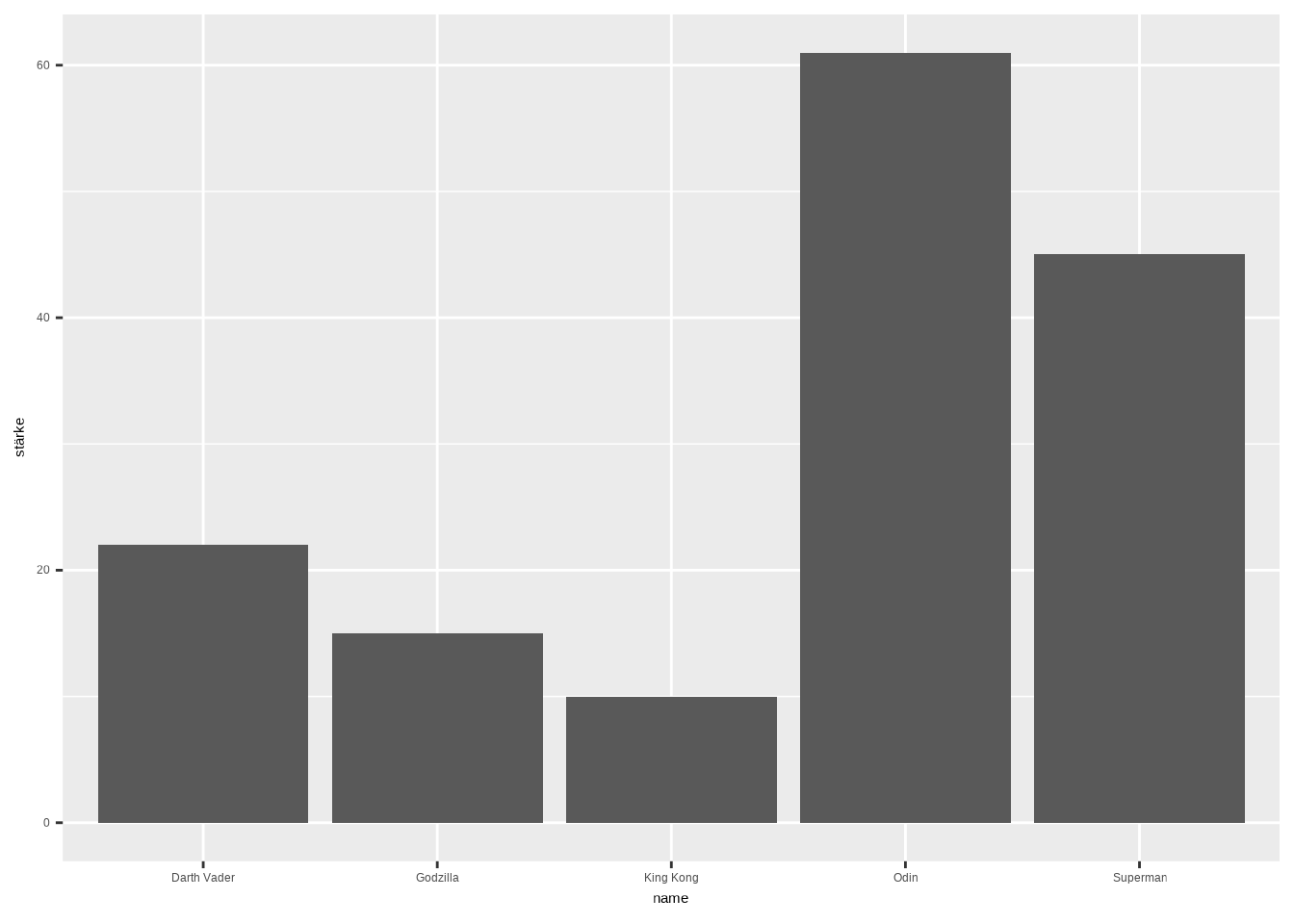
Auch hier können wir das Erscheinungsbild unseres Plots verändern. Wir beginnen damit, die Farbe zu ändern, indem wir sie innerhalb der Funktion geom_bar() festlegen. Danach setzen wir ein Theme – diesmal verwenden wir theme_test() – und ändern die Namen der Achsen mit der Funktion labs().
Hinweis: Ich kann die Beschriftung der x-Achse deaktivieren, indem ich einfach leere Anführungszeichen in der labs()-Funktion angebe.
ggplot(data4, aes(x = name, y = stärke)) +
geom_bar(stat = "identity", fill = "#AE388B") +
labs(
x = "",
y = "Stärke",
title = "Stärke fiktiver Charaktere"
) +
theme_test()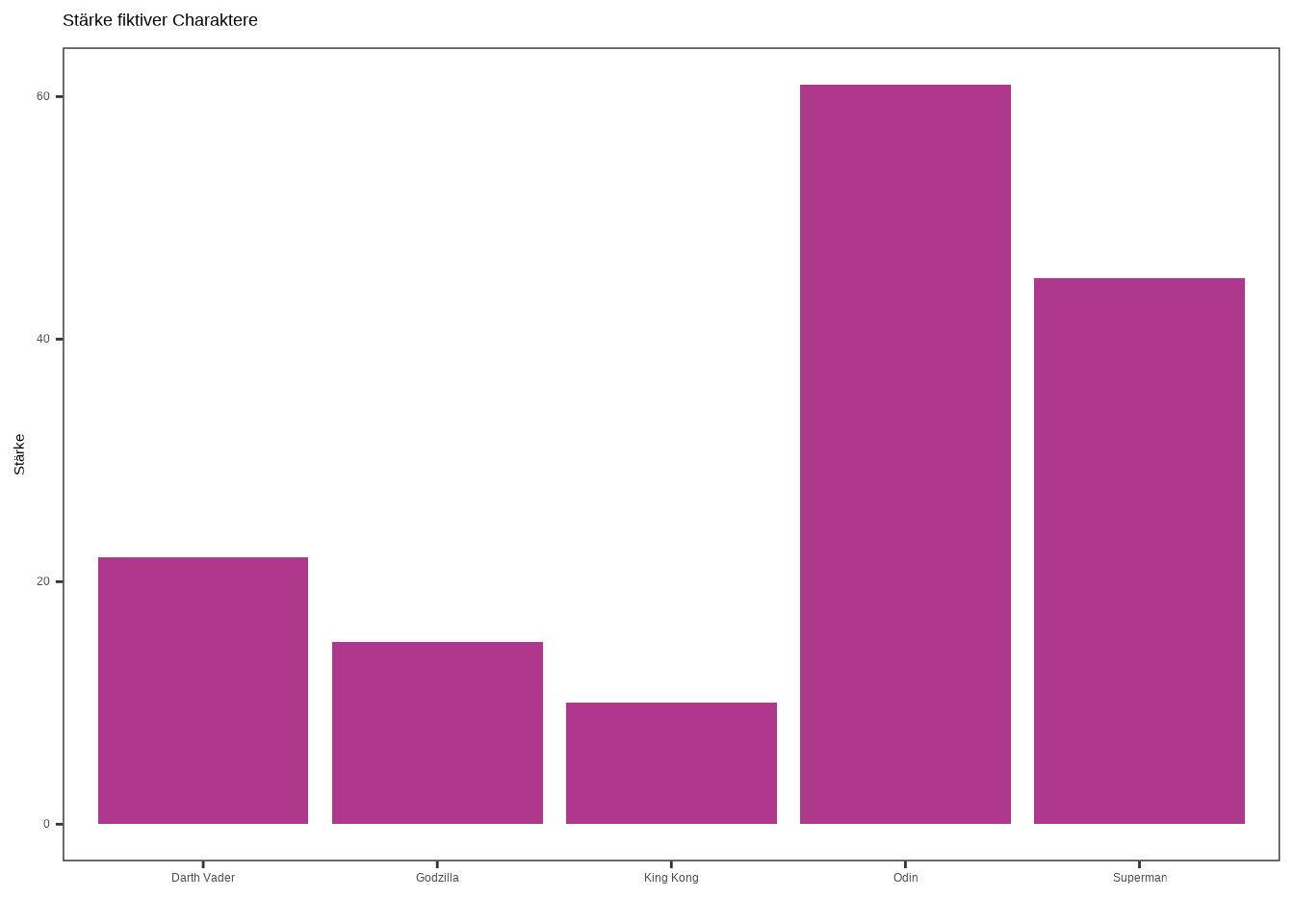
Es gibt noch eine weitere Möglichkeit, Barplots einzusetzen: Wir können sie nutzen, um Kategorien zu zählen. Ähnlich wie bei einem Histogramm, allerdings mit dem Unterschied, dass wir hier keine Zahlenbereiche zählen. Stattdessen haben wir Gruppen und möchten zählen, wie oft diese Gruppen in unserem Datensatz vorkommen. Nehmen wir an, wir haben 20 Kinder gefragt, welcher fiktive Charakter ihr Lieblingscharakter ist: Superman, King Kong oder Godzilla.
data5 <- data.frame(
held = c(rep("Superman", 10),
rep("King Kong", 3),
rep("Godzilla", 7)),
id = c(seq(1:20)),
weiblich = c(rep("weiblich", 7),
rep("männlich", 5),
rep("weiblich", 1),
rep("weiblich", 3),
rep("männlich", 4))
) ggplot(data5, aes(x = held)) +
geom_bar(fill = "#AE388B") +
labs(
x = "",
y = "Häufigkeit",
title = "Wer ist dein Lieblingscharakter?"
) +
scale_y_continuous(breaks = seq(0,10,1)) +
theme_test()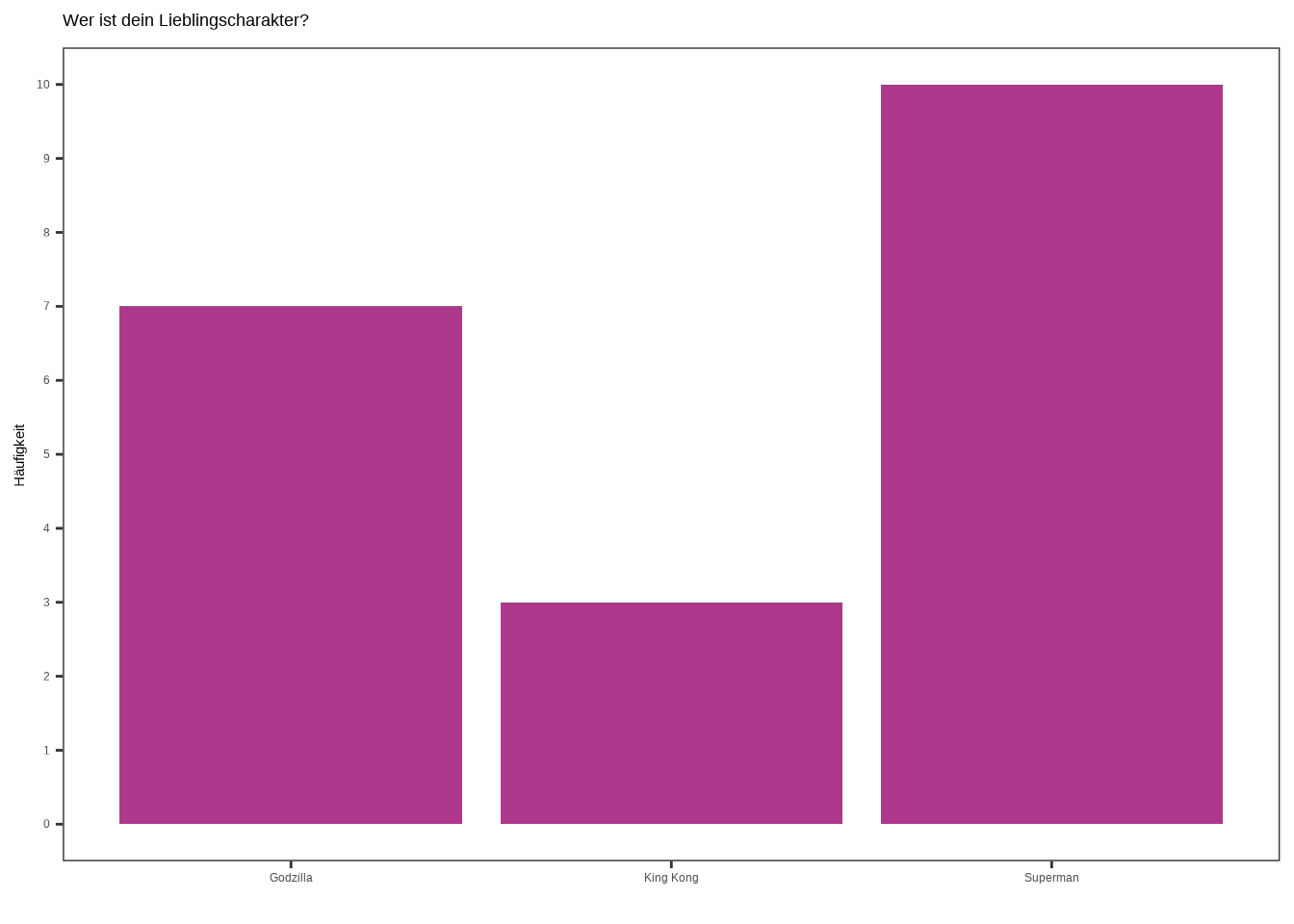
Wir könnten beide Barplots auch drehen, sodass ein horizontaler Barplot entsteht. Das ist ganz einfach: Wir müssen lediglich die Funktion coord_flip() hinzufügen. Diese Funktion tauscht die x-Achse und die y-Achse.
Schauen wir uns die Plots an:
# Plot 1
ggplot(data4, aes(x = name, y = stärke)) +
geom_bar(stat = "identity", fill = "#AE388B") +
labs(
x = "",
y = "Stärke",
title = "Stärke fiktiver Charaktere"
) +
theme_test() +
coord_flip()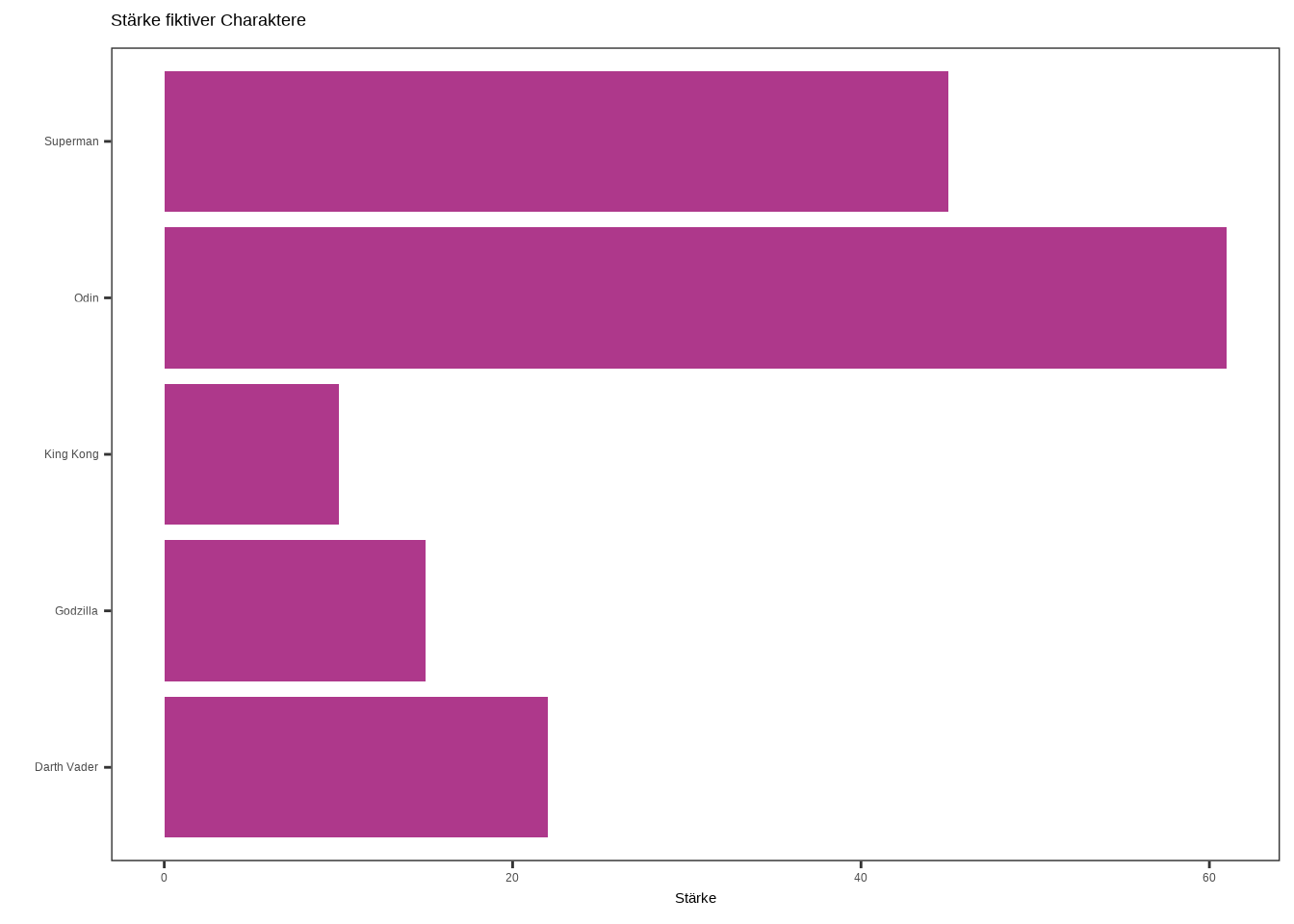
# Plot 2
ggplot(data5, aes(x = held)) +
geom_bar(fill = "#AE388B") +
labs(
x = "",
y = "Häufigkeit",
title = "Wer ist dein Lieblingscharakter?"
) +
scale_y_continuous(breaks = seq(0,10,1)) +
theme_test() +
coord_flip()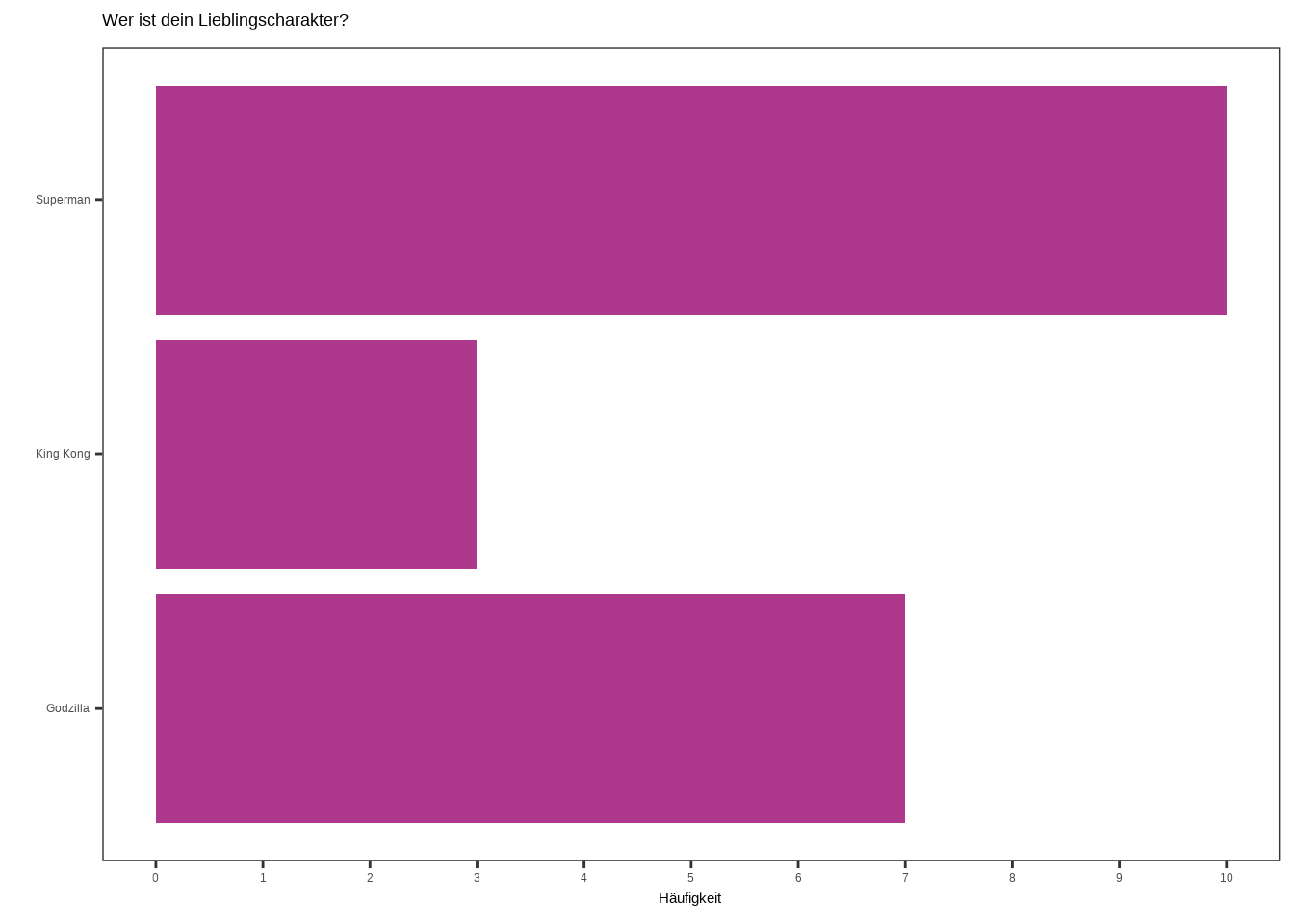
3.3.2 Sortierung
Um einen Barplot intuitiver zu gestalten, können wir ihn so sortieren, dass der Balken mit dem höchsten Wert am Anfang steht und dann abnimmt – oder umgekehrt.
Dazu verwenden wir das
forcats-Paket.Wir nehmen den Code von oben und umschließen den x-Wert mit dem Befehl
fct_reorder(). Dabei geben wir an, nach welchem Wert sortiert werden soll – in unserem Fall ist der x-Wert der Name des fiktiven Charakters und der Sortierwert ist die Stärke bzw. die Häufigkeit.
Hinweis: Die absteigende Sortierung ist ebenfalls möglich, indem man den Sortierwert mit desc() umschließt, also z. B.: fct_reorder(name, desc(stärke)).
# Plot 1
ggplot(data4, aes(x = fct_reorder(name, stärke), y = stärke)) +
geom_bar(stat = "identity", fill = "#AE388B") +
labs(
x = "",
y = "Stärke",
title = "Stärke fiktiver Charaktere"
) +
theme_test()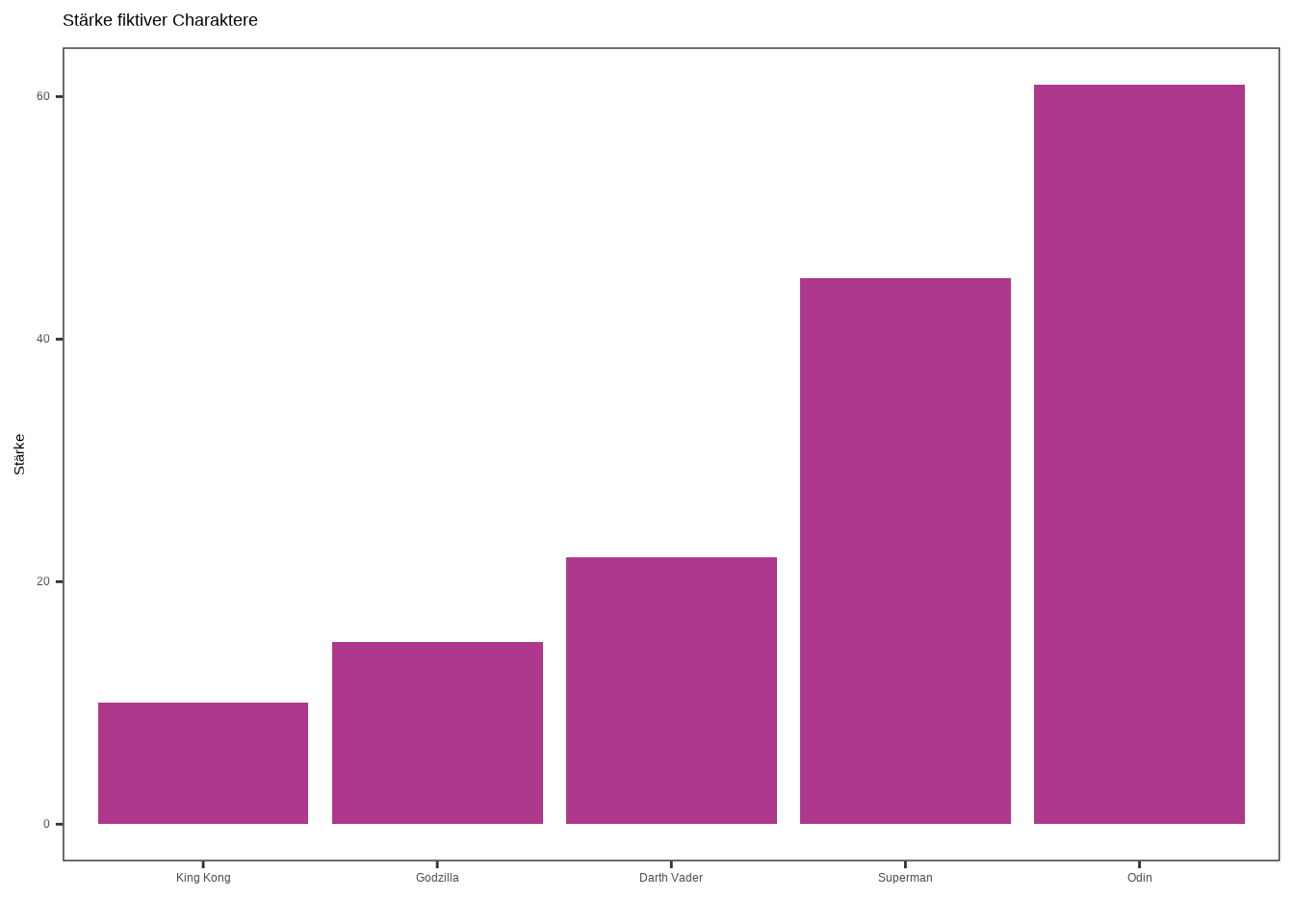
# Plot 2
ggplot(data4, aes(x = fct_reorder(name, stärke), y = stärke)) +
geom_bar(stat = "identity", fill = "#AE388B") +
labs(
x = "",
y = "Stärke",
title = "Stärke fiktiver Charaktere"
) +
theme_test() +
coord_flip()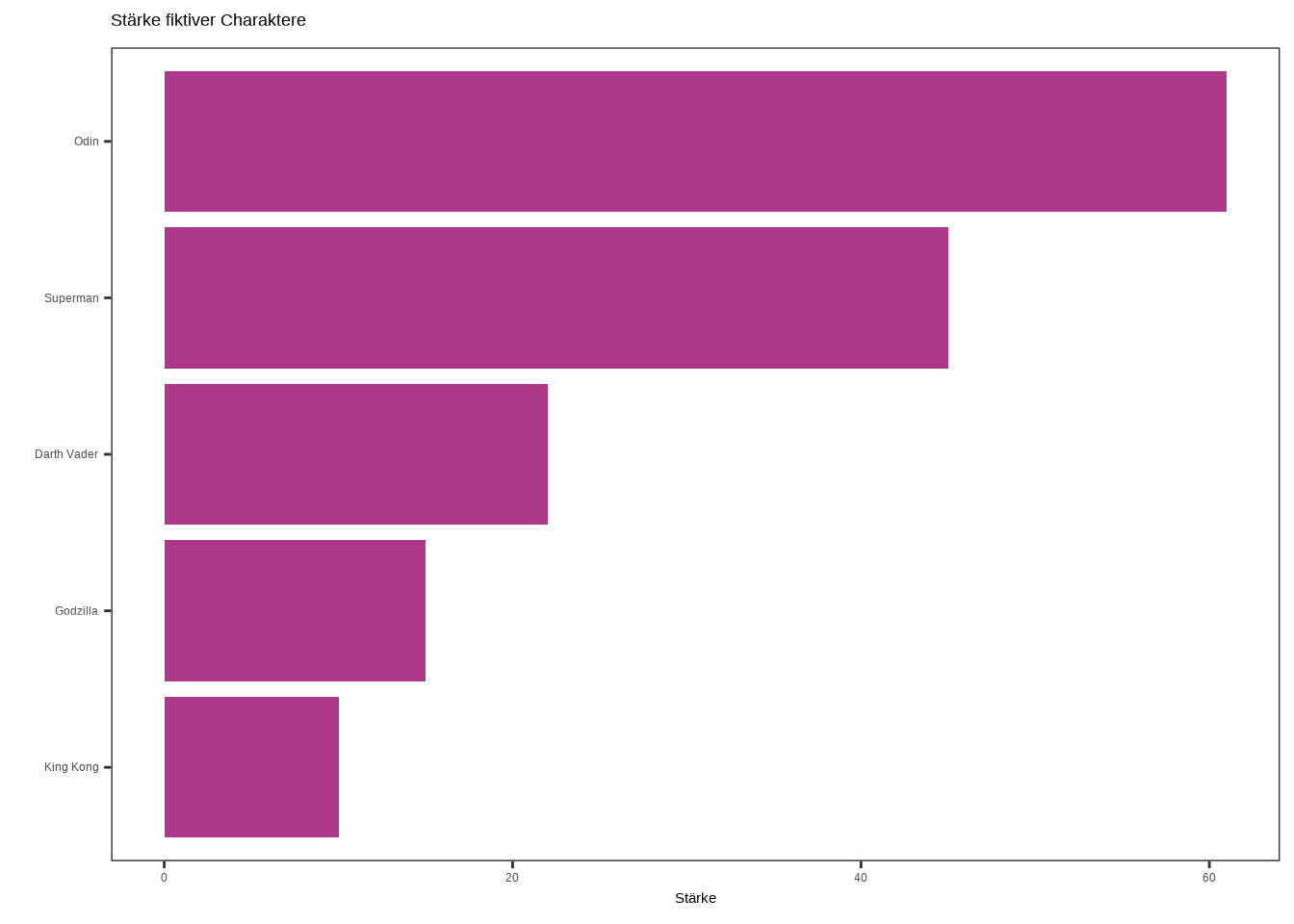
3.3.3 Gruppierte und gestapelte Barplots
Wir können Barplots noch einen Schritt weiterdenken und sie gruppieren. Nehmen wir an, wir haben Befragte gebeten, uns auf einer Skala von 0 bis 10 anzugeben, wie gesund sie sich fühlen. Dabei möchten wir Befragte über 40 und unter 40 Jahren trennen und zusätzlich nach Geschlecht unterscheiden. Wir betrachten also den Durchschnittswert von 4 Gruppen: Weiblich über 40, Männlich über 40, Weiblich unter 40 und Männlich unter 40 – um zu sehen, ob es geschlechtsspezifische Unterschiede innerhalb der Altersgruppen gibt. Hier sind die Daten:
data6 <- data.frame(
weiblich = c("Weiblich", "Männlich", "Weiblich", "Männlich"),
alter = c("Alt", "Alt", "Jung", "Jung"),
wert = c(5, 2, 8, 7)
)Nun haben wir die Daten. Wir müssen innerhalb von aes() drei Parameter definieren: Die x-Achse bildet die Altersgruppen ab, die y-Achse den Durchschnittswert, und wir müssen fill = weiblich definieren, da dies die Gruppe ist, die wir innerhalb der Altersgruppen untersuchen möchten. Innerhalb von geom_bar() benötigen wir zwei Argumente: stat = "identity" und position = "dodge". Et voilà – so erhalten wir unseren ersten gruppierten Barplot.
ggplot(data6, aes(x = alter, y = wert, fill = weiblich)) +
geom_bar(position = "dodge", stat="identity") 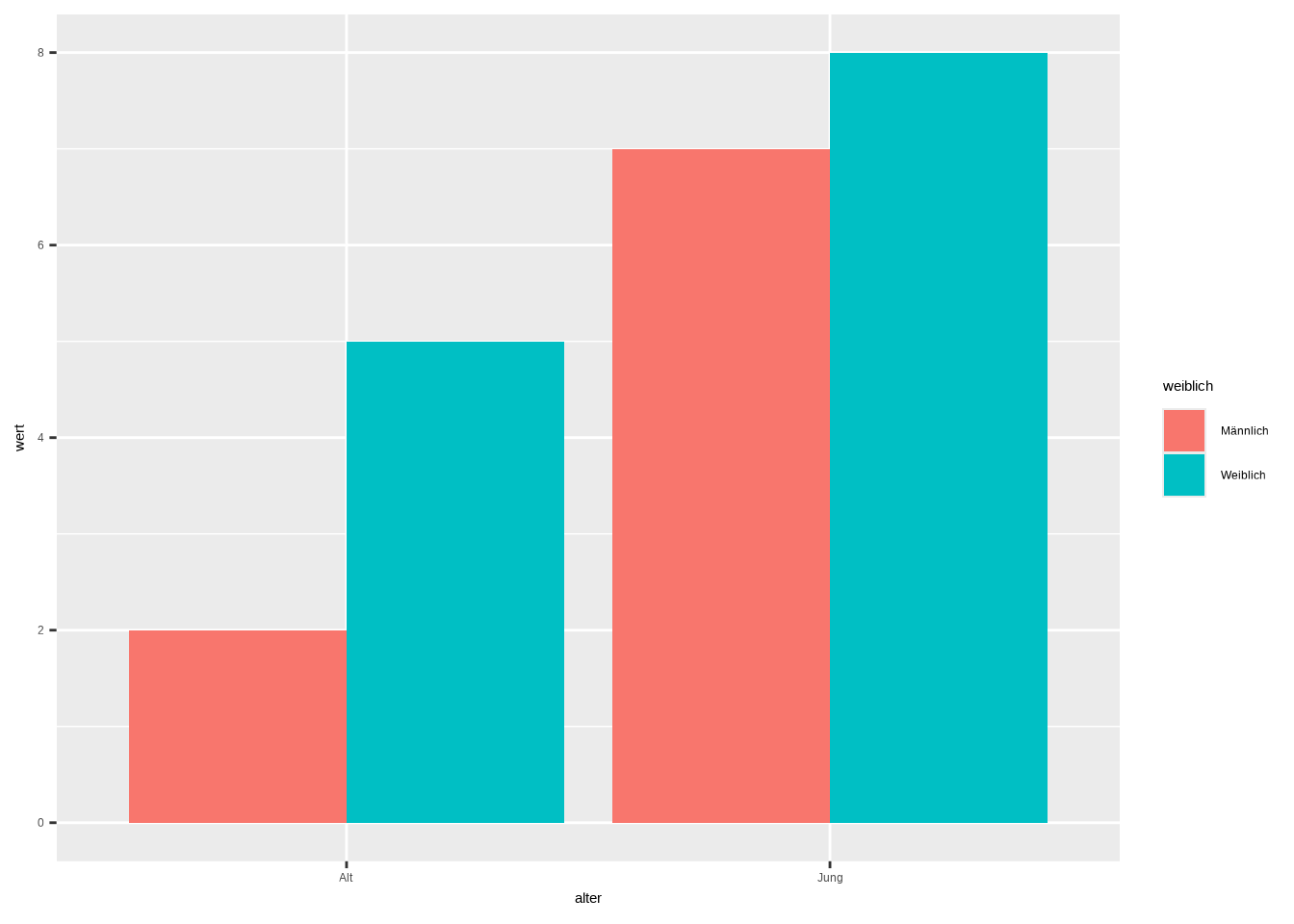
Alternativ können wir einen gestapelten Barplot verwenden. Der Unterschied besteht darin, dass wir einen Balken für unsere x-Achsen-Gruppe haben – in unserem Beispiel die Altersgruppe – und die Anteile der zweiten Gruppe, das Geschlecht, werden übereinander gestapelt. Man kann das auch als normalen Barplot betrachten, bei dem der Balken je nach prozentualer Verteilung der anderen Gruppe eingefärbt ist. Im Code ändert sich lediglich, dass wir das Argument position in geom_bar() auf position = "stack" setzen:
ggplot(data6, aes(x = alter, y = wert, fill = weiblich)) +
geom_bar(position = "stack", stat="identity") 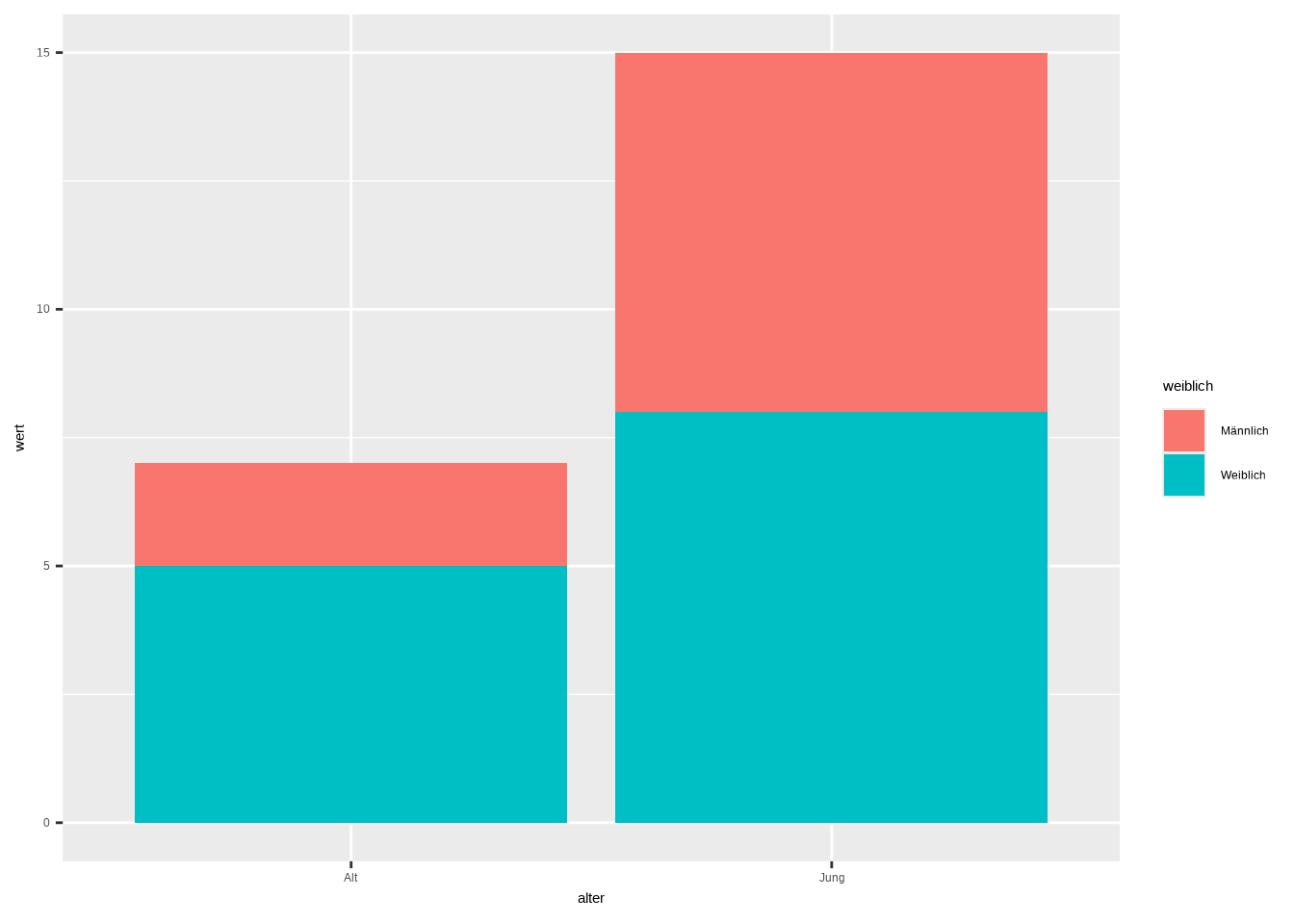
Nun gestalten wir die Plots mit unseren bekannten Techniken ansprechender. Dabei werden zwei neue Dinge eingeführt:
Das Argument
width = 0.35wird ingeom_bar()eingefügt, um die Breite der Balken festzulegen.Ich stelle euch sogenannte Farbpaletten vor. Anstatt die Farben manuell zu skalieren, könnt ihr vordefinierte Farbpaletten für verschiedene Plottypen verwenden. Für Barplots kann man
scale_fill_brewer()nutzen, das verschiedene Paletten und Farben enthält, die automatisch angezeigt werden. Eine Übersicht der verfügbaren Paletten findet ihr hier. Das ist besonders hilfreich, wenn man viele Gruppen hat und sich nicht selbst um aufeinander abgestimmte Farben kümmern möchte.
# Plot 1
ggplot(data6, aes(x = alter, y = wert, fill = weiblich)) +
geom_bar(position = "dodge", stat="identity",
width = 0.35) +
scale_fill_brewer(palette = "Accent") +
scale_y_continuous(breaks = seq(0, 15, 1)) +
labs(
x = "Altersgruppe",
y = "Durchschnittlicher Wohlbefindenswert",
title = "Einfluss des Alters auf das Wohlbefinden
nach Geschlecht"
) +
theme_minimal() +
theme(legend.title=element_blank())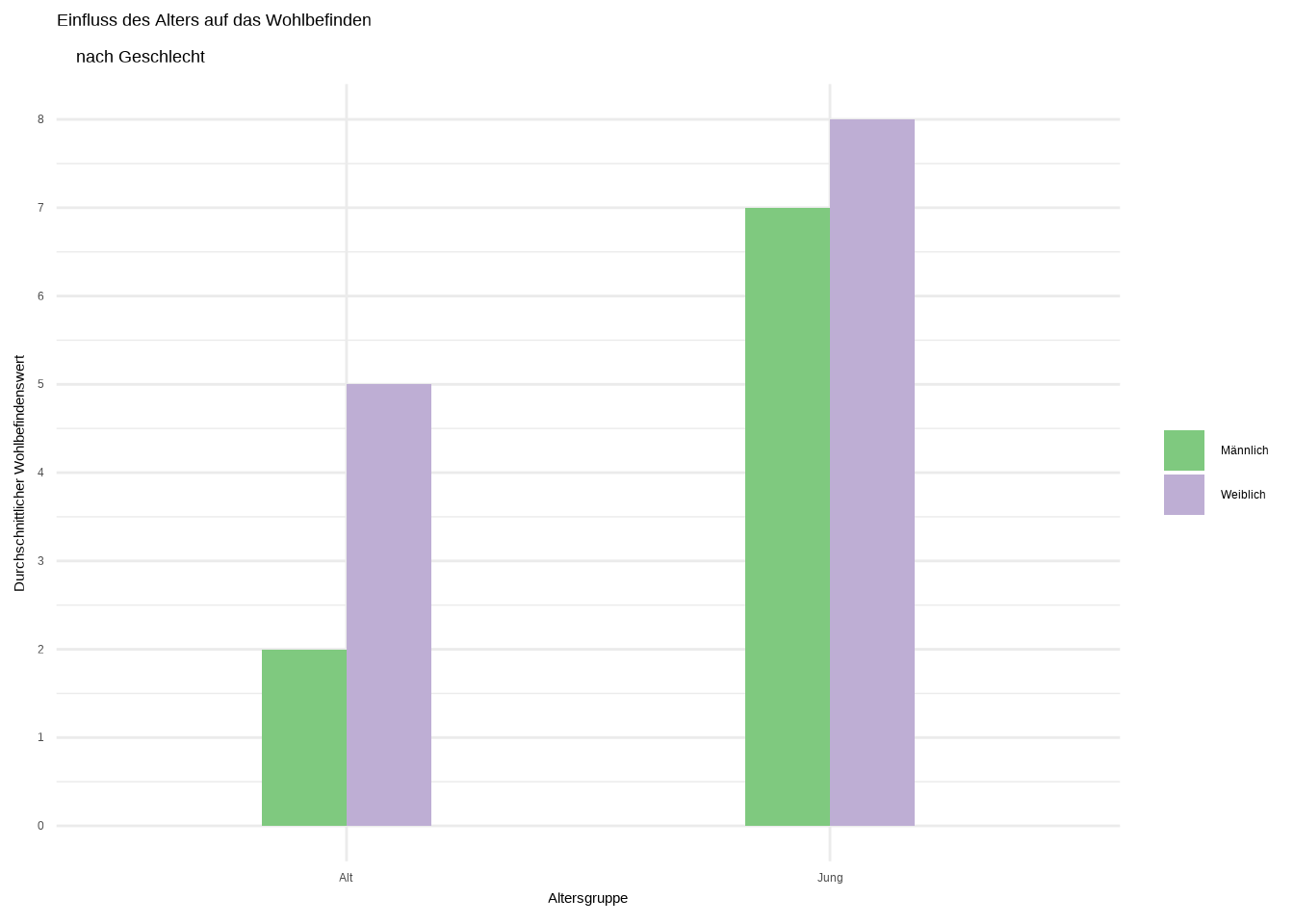
# Plot 2
ggplot(data6, aes(x = alter, y = wert, fill = weiblich)) +
geom_bar(position = "stack", stat="identity",
width = 0.35) +
scale_fill_brewer(palette = "Accent") +
scale_y_continuous(breaks = seq(0, 15, 2)) +
labs(
x = "Altersgruppe",
y = "Durchschnittlicher Wohlbefindenswert",
title = "Einfluss des Alters auf das Wohlbefinden nach Geschlecht"
) +
theme_minimal() +
theme(legend.title=element_blank())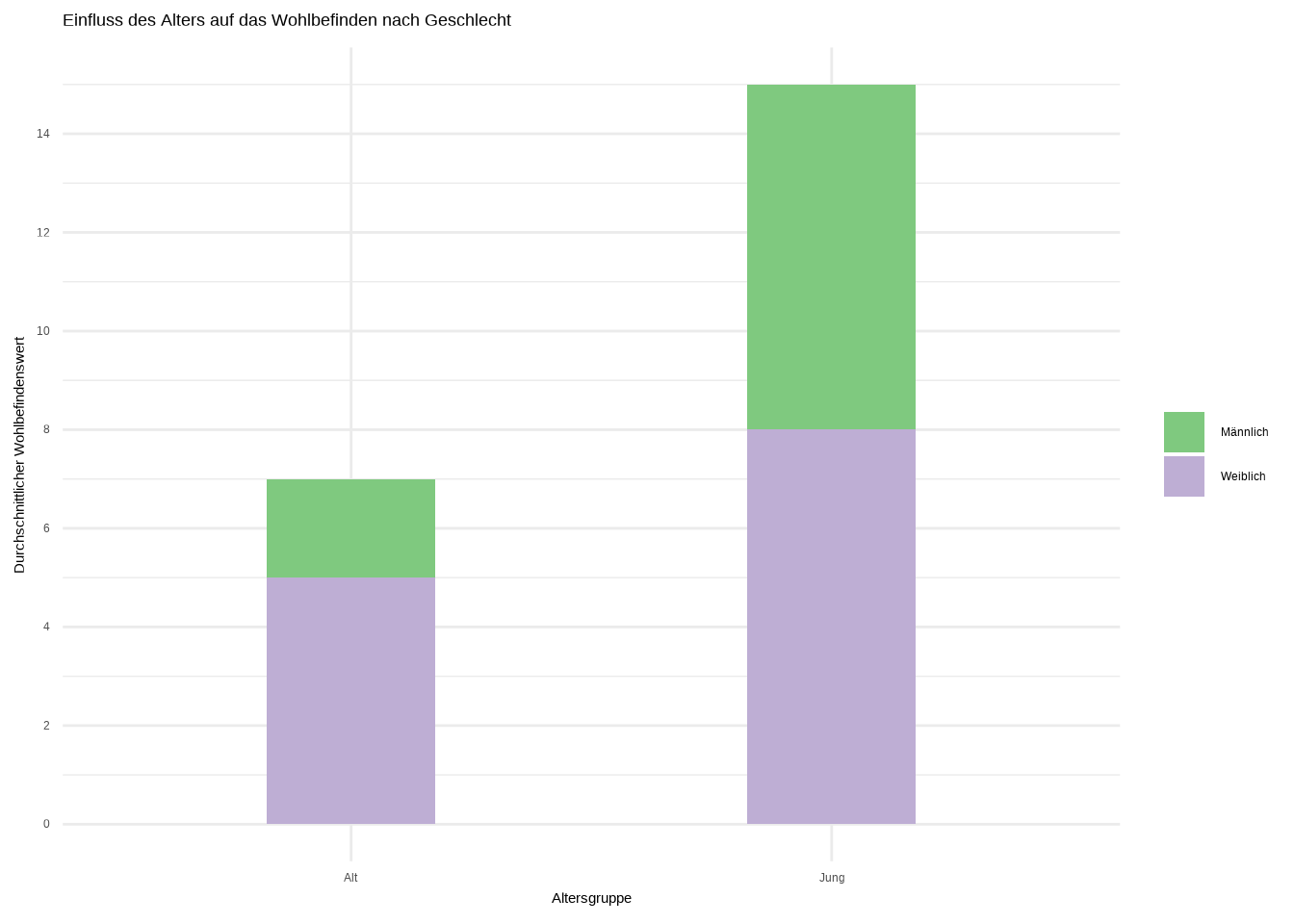
3.4 Entwicklung: Liniendiagramm
Ein sehr bekannter Plottyp ist das Liniendiagramm. Es ist eine weit verbreitete Methode, um die Entwicklung einer Variable über eine andere Variable auf der x-Achse darzustellen. Wir kennen Liniendiagramme vor allem aus Zeitreihenanalysen, bei denen ein bestimmter Zeitraum auf der x-Achse abgebildet wird. Da solche Liniendiagramme mit Datumsangaben weit verbreitet sind, werde ich diese als Beispiel verwenden. Ein Liniendiagramm zeigt die Entwicklung einer oder mehrerer numerischer Variablen. Datenpunkte werden durch gerade Liniensegmente verbunden, wobei die Messpunkte geordnet sind (typischerweise nach ihrem x-Achsen-Wert) und mit geraden Linien verbunden werden.
3.4.1 Einfaches Liniendiagramm
In ggplot verwenden wir wie gewohnt die ggplot()-Funktion, definieren unsere x- und y-Achse und fügen die Funktion geom_line() hinzu.
# Seed setzen
set.seed(500)
# Daten erstellen
datum <- 2000:2024
y <- cumsum(rnorm(25))
y2 <- cumsum(rnorm(25))
data7 <- data.frame(datum, y, y2)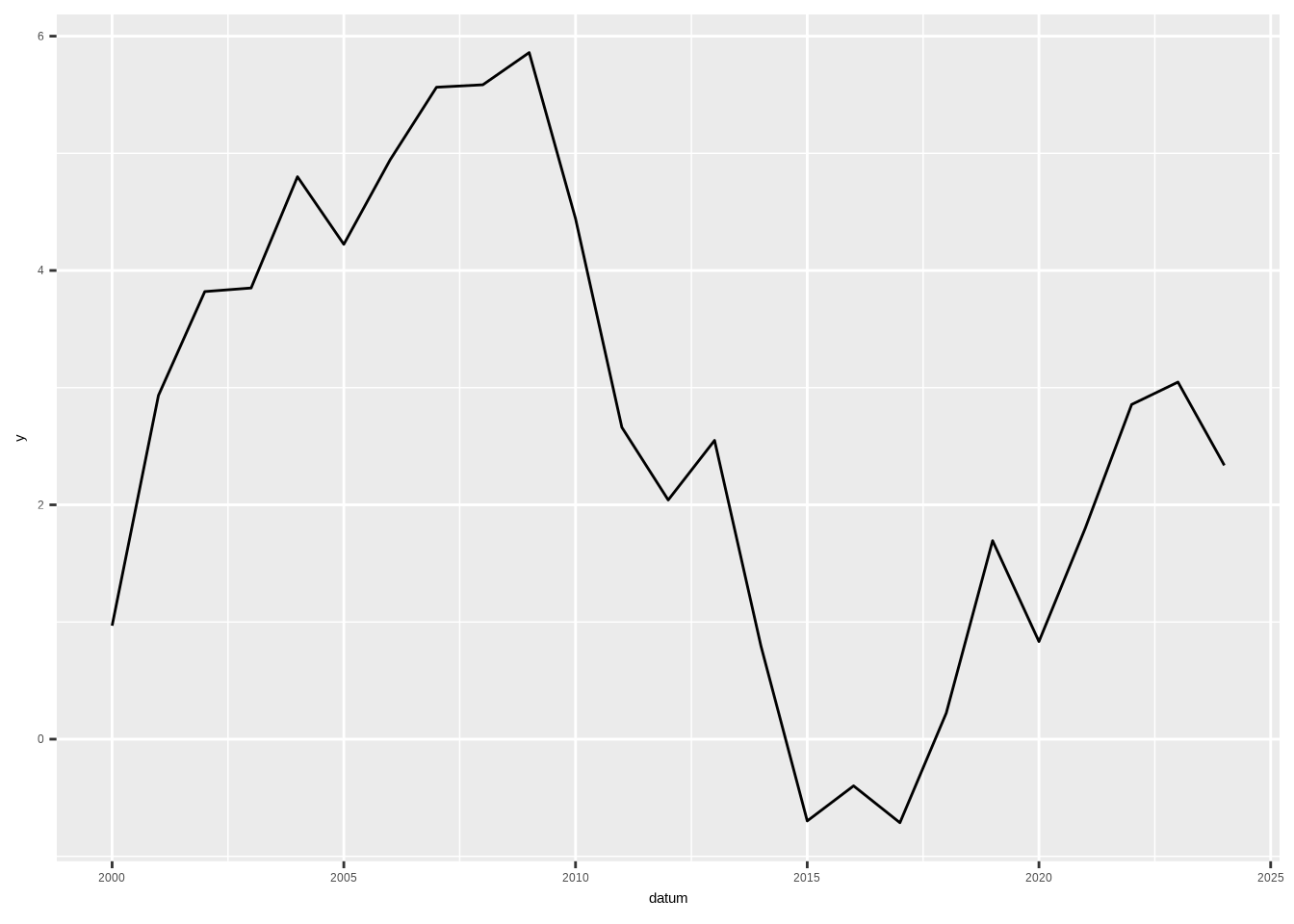
Normalerweise würden wir den Plot nun verschönern. Aber zunächst gibt es einige zusätzliche Gestaltungsmöglichkeiten für Liniendiagramme:
Erstens können wir den Linientyp ändern. Der Linientyp kann wie in der Standardeinstellung durchgezogen sein, aber ich werde ihn im
geom_line()-Befehl auflinetype = "dashed"setzen. Eine Übersicht aller Linientypen findet ihr hier.Zweitens ändere ich die Linienstärke mit
size = 1imgeom_line()-Befehl.Die übrigen Gestaltungselemente bleiben gleich: Achsen neu skalieren, Farben anpassen und Themes setzen.
ggplot(data7, aes(x = datum, y = y)) +
geom_line(color = "#0F52BA", linetype = "dashed",
linewidth = 1) +
scale_y_continuous(breaks = seq(-1, 6, 1),
limits = c(-1, 6)) +
scale_x_continuous(breaks = seq(2000, 2024, 2)) +
labs(
y = "",
x = "Jahr",
title = "Ein Liniendiagramm"
) +
theme_bw()
3.4.2 Mehrere Linien
Im nächsten Schritt möchten wir mehrere Linien in einem Plot darstellen. Das ist hilfreich, wenn wir die Entwicklung von Variablen – beispielsweise über die Zeit – vergleichen möchten. In ggplot2 müssen wir lediglich eine weitere Ebene mit einem Plus-Zeichen hinzufügen und einen weiteren geom_line()-Befehl einfügen. Dabei gibt es jedoch einige Besonderheiten zu beachten:
Im
ggplot()-Befehl geben wir nur unseren Datensatz an – nichts weiter.Im ersten
geom_line()-Befehl fügen wir dieaes()-Funktion hinzu und definieren x und y. Bisher haben wir dieaes()-Funktion immer innerhalb derggplot()-Funktion geschrieben – nun müssen wir sie in dergeom_line()-Funktion angeben, da wir eine weiteregeom_line()-Ebene hinzufügen.Im zweiten
geom_line()-Befehl definieren wir unsere nächste Ebene. Die x-Achse bleibt logischerweise gleich, aber wir ändern y und setzen es auf die zweite Variable, die wir darstellen möchten.
Wie immer gestalten wir den Plot im nächsten Schritt ansprechender. Ich verwende denselben Code wie oben. Bezüglich der Linien selbst können wir die Gestaltung für jede Ebene separat festlegen:
- Wir können Linientyp, Farbe und Stärke für jede Ebene unterschiedlich definieren. Wir müssen dies lediglich im jeweiligen
geom_line()-Befehl der entsprechenden Ebene angeben.
ggplot(data7) +
geom_line(aes(x = datum, y = y),
linetype = "twodash",
size = 1,
color = "#365E32") +
geom_line(aes(x = datum, y = y2),
linetype = "longdash",
size = 1,
color = "#FD9B63") +
scale_y_continuous(breaks = seq(-5, 6, 1),
limits = c(-5, 6)) +
scale_x_continuous(breaks = seq(2000, 2024, 2)) +
labs(
y = "",
x = "Jahr",
title = "Ein Liniendiagramm"
) +
theme_bw()
3.4.3 Gruppierte Liniendiagramme
Eine weitere Möglichkeit, Liniendiagramme einzusetzen, ist die getrennte Darstellung der Entwicklung verschiedener Gruppen. Ich stelle euch den babynames-Datensatz vor – ein R-Paket, das automatisch Daten zu den beliebtesten Babynamen in den USA von 1880 bis 2017 lädt. Schauen wir uns den Datensatz an:
## # A tibble: 6 × 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 F Mary 7065 0.0724
## 2 1880 F Anna 2604 0.0267
## 3 1880 F Emma 2003 0.0205
## 4 1880 F Elizabeth 1939 0.0199
## 5 1880 F Minnie 1746 0.0179
## 6 1880 F Margaret 1578 0.0162Nehmen wir an, wir interessieren uns für die Popularität der Namen Emma, Kimberly und Ruth. Wir reduzieren den Datensatz mit der filter()-Funktion, die ihr im vorherigen Kapitel kennengelernt habt, auf diese drei Namen:
babynames_cut <- babynames %>%
filter(name %in% c("Emma", "Kimberly", "Ruth")) %>%
filter(sex == "F")Im nächsten Schritt stellen wir die Popularität dieser drei Namen über die Zeit dar.
- Wir definieren die x- und y-Achse und fügen eine
geom_line()-Ebene hinzu – soweit wie gewohnt. Als Nächstes teilen wir ggplot2 mit, dass wir Gruppen darstellen möchten, indem wir in derggplot()-Funktiongroup = namesetzen. Außerdem sollten wircolor = namesetzen, da sonst alle Linien schwarz sind und wir nicht erkennen können, welche Linie zu welcher Gruppe gehört.
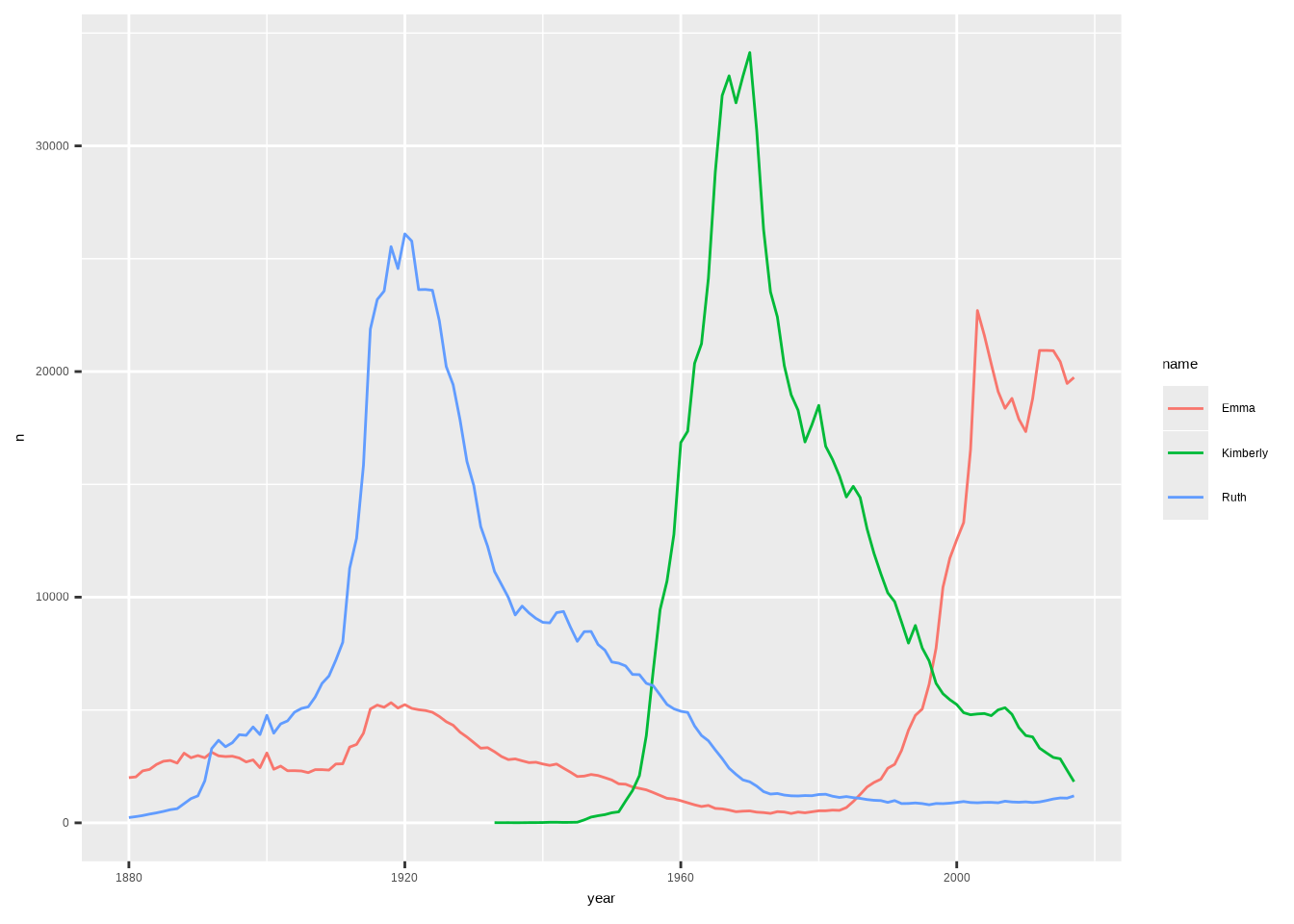
Das sieht gut aus – wir können erkennen, dass Ruth in den 1920er Jahren seinen Höhepunkt hatte, Kimberly in den 1960er Jahren und Emma aktuell im Aufstieg ist. Nun gestalten wir den Plot mit einem Theme, entfernen den Legendentitel, vergeben aussagekräftige Achsenbeschriftungen und fügen eine Farbpalette mit scale_color_brewer() hinzu.
- Bezüglich der Beschriftungen zeige ich euch, wie man die Legende umbenennt: Einfach
color = "Neuer Name"in derlabs()-Funktion angeben.
ggplot(babynames_cut, aes(x = year, y = n,
group = name,
color = name)) +
geom_line(size = 1) +
scale_color_brewer(palette = "Set1") +
labs(
x = "Jahr",
y = "Anzahl der Babys mit diesem Namen",
title = "Popularität von Babynamen über die Zeit",
color = "Name"
) +
theme_minimal() 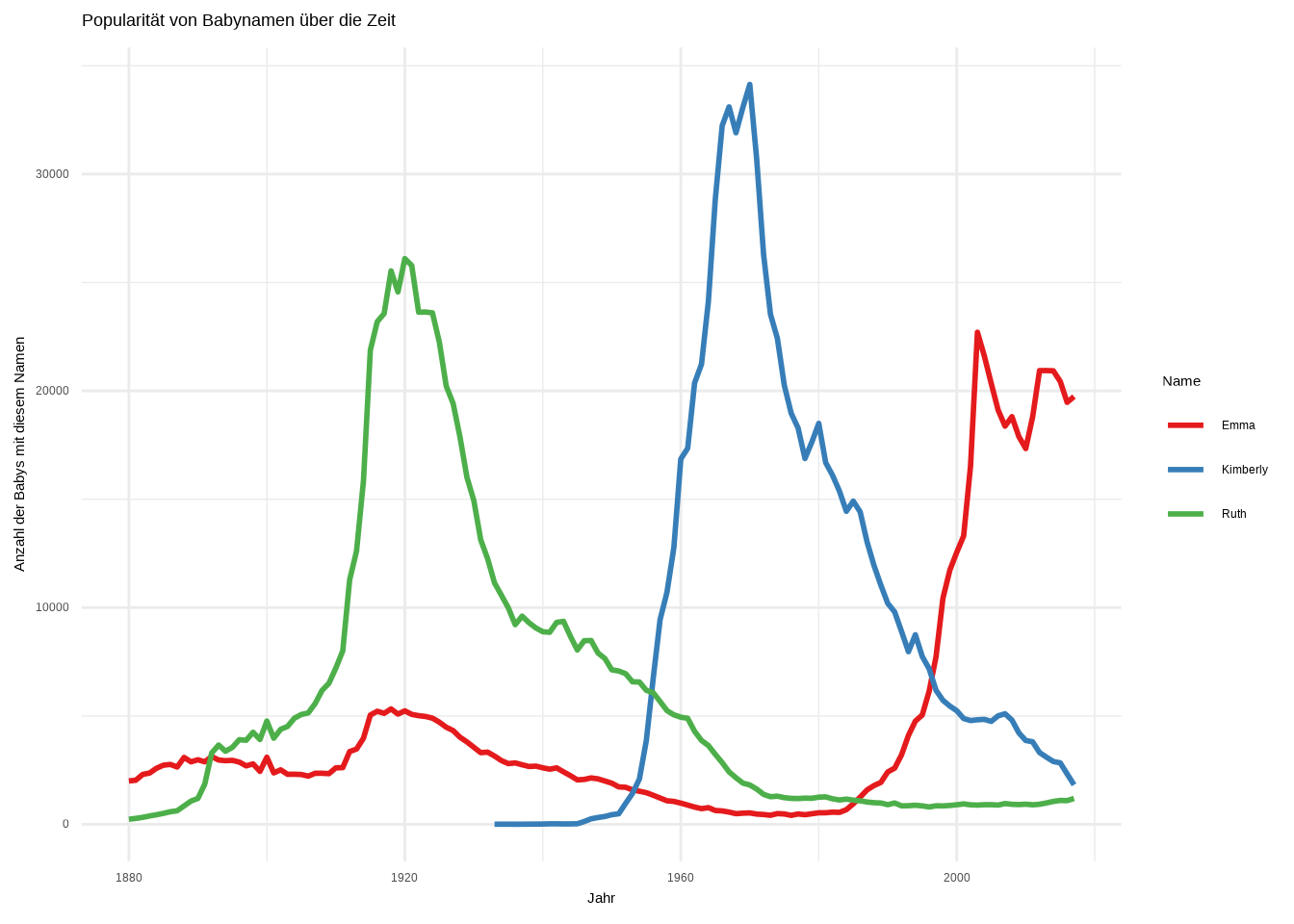
3.5 Korrelation: Streudiagramme
Der letzte Visualisierungstyp sind Streudiagramme (Scatterplots). Ein Streudiagramm zeigt die Beziehung zwischen zwei numerischen Variablen. Jeder Punkt repräsentiert eine Beobachtung. Die Position auf der X-Achse (horizontal) und der Y-Achse (vertikal) entspricht den Werten der beiden Variablen. Es ist eine weit verbreitete Methode in wissenschaftlichen Artikeln, um die Beziehung zwischen zwei Variablen zu untersuchen.
3.5.1 Einfaches Streudiagramm
Wir möchten die Beziehung zwischen zwei Variablen untersuchen. Nehmen wir an, wir sind der Inhaber eines großen Schokoladenunternehmens und möchten herausfinden, wie sich unsere Marketingausgaben auf den Verkauf unserer Schokolade auswirken. Wir verfügen über Daten für jedes Quartal eines Jahres über mehrere Jahre hinweg:
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Daten simulieren
n <- 100
marketing_budget <- runif(n, min = 1000, max = 10000)
sales <- 2000 + 0.65 * marketing_budget +
rnorm(n, mean = 1400, sd = 750)
quartale <- rep(c("Q1", "Q2", "Q3", "Q4"), 25)
# Dataframe erstellen
data_streu <- data.frame(marketing_budget, sales,
quartale)
# Namen vergeben
data_streu$name <- "Vollmilchschokolade"Ein Streudiagramm in R wird nach derselben Logik wie immer erstellt:
Zunächst definieren wir die x- und y-Achse im
ggplot()-Befehl.Dann fügen wir die Funktion
geom_point()hinzu.
Nun gestalten wir den Plot ansprechender: Wir definieren eine Farbe für die Punkte in der Ebene, also in der geom_point()-Funktion, skalieren die Achsen neu (in diesem Fall nur die x-Achse), benennen die Achsen um, vergeben einen Titel und definieren ein Theme.
ggplot(data_streu, aes(x = marketing_budget,
y = sales)) +
geom_point(color = "#99582a") +
scale_x_continuous(breaks = seq(0, 10000, 2000)) +
labs(
x = "Marketingbudget",
y = "Verkäufe pro Einheit",
title = "Vollmilchschokolade: Verkäufe und Marketing"
) +
theme_classic() 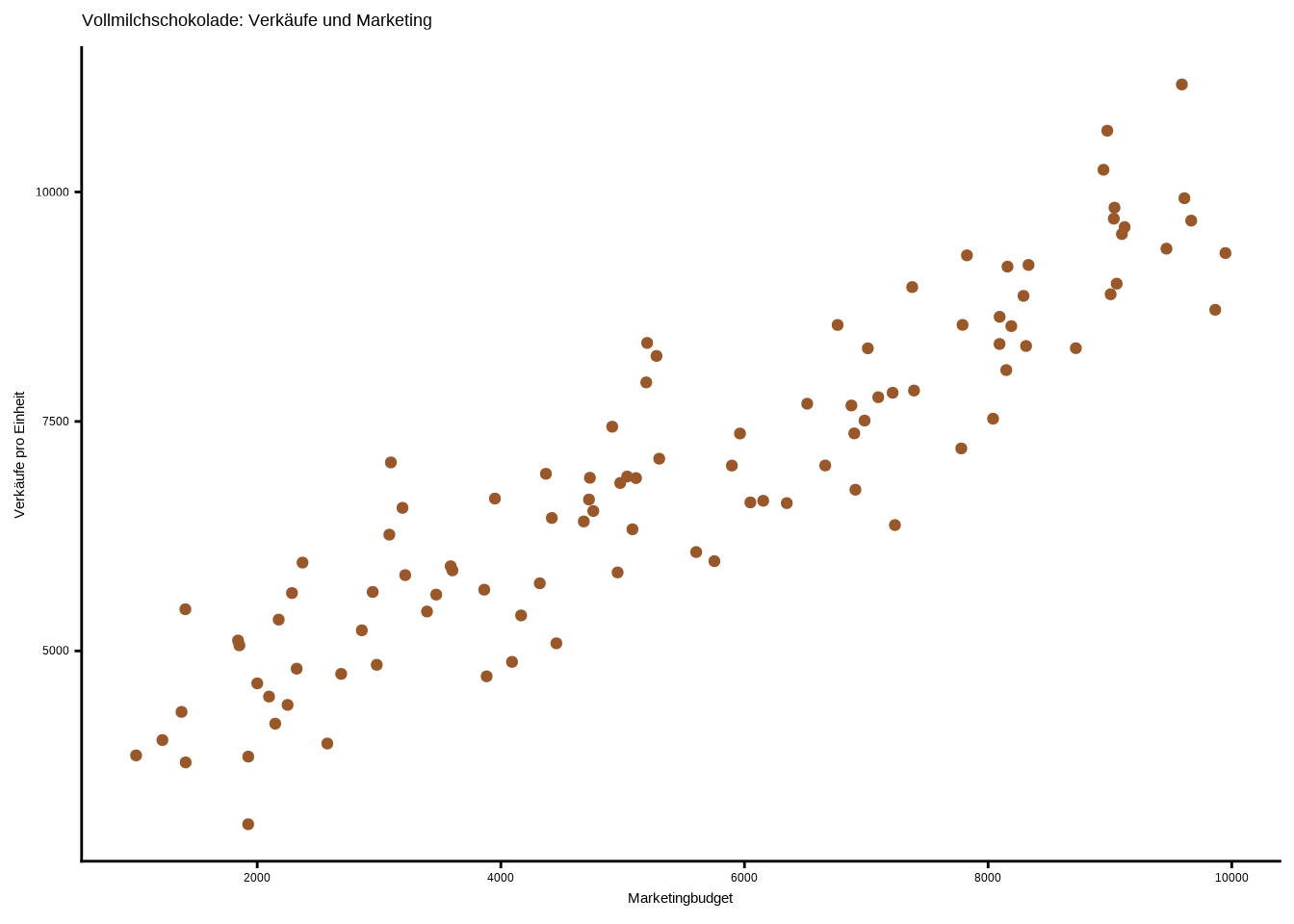
3.5.2 Streudiagramme mit mehreren Gruppen
Weiter mit unserem Beispiel: Wir verkaufen nicht nur eine Schokoladensorte, sondern zwei – Vollmilchschokolade und dunkle Schokolade. Holen wir uns auch die Daten für die dunkle Schokolade:
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Daten simulieren
n <- 100
marketing_budget <- runif(n, min = 1000, max = 10000)
sales <- 1500 + 0.3 * marketing_budget + rnorm(n, mean = 1400, sd = 750)
quartale <- rep(c("Q1", "Q2", "Q3", "Q4"), 25)
# Dataframe erstellen
df_zartbitter <- data.frame(marketing_budget, sales, quartale)
# Namen vergeben
df_zartbitter$name <- "Dunkle Schokolade"
# Mit dem anderen Datensatz zusammenfügen
data8 <- rbind(data_streu, df_zartbitter)Wir könnten denselben Code wie oben verwenden, wären dann jedoch nicht in der Lage zu erkennen, welche Punkte zu welcher Schokoladensorte gehören.
Deshalb müssen wir in der
aes()-Funktion das Argumentcolor = nameangeben. Dadurch werden die Punkte entsprechend ihrer Gruppe eingefärbt.Ich werde die Farben manuell festlegen, da ich in diesem Beispiel Brauntöne verwenden möchte.
ggplot(data8, aes(x = marketing_budget,
y = sales,
color = name)) +
geom_point() +
scale_color_manual(values = c("#e71d36",
"#260701"))+
scale_x_continuous(breaks = seq(0, 10000, 2000)) +
labs(
x = "Marketingbudget",
y = "Verkäufe pro Einheit",
title = "Schokolade: Verkäufe und Marketing",
color = "Produkt"
) +
theme_classic() 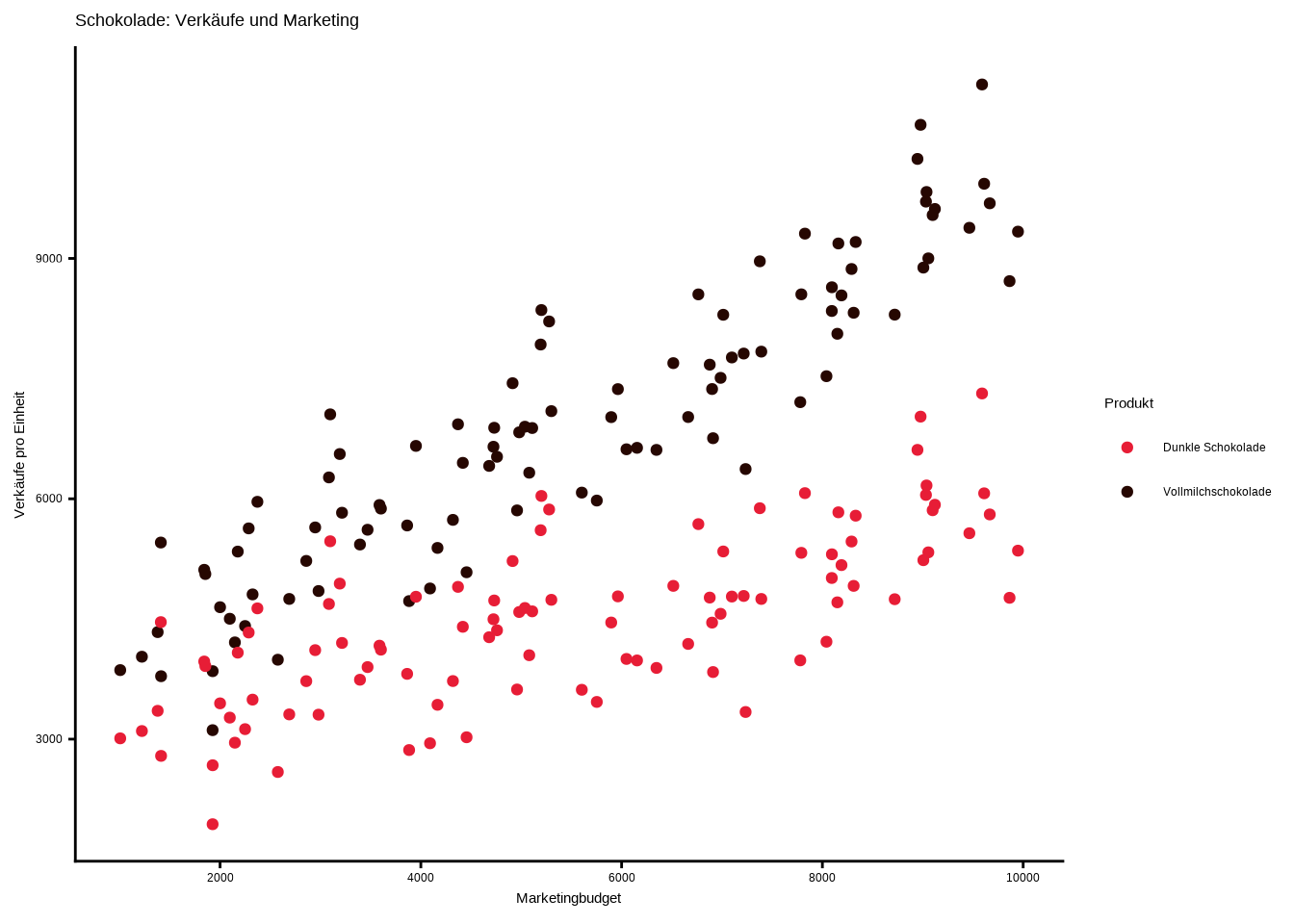
Wir sehen, dass Marketing generell zu höheren Schokoladenverkäufen führt. Außerdem erkennen wir, dass Marketing einen stärkeren Effekt auf Vollmilchschokolade als auf dunkle Schokolade hat.
Die Verwendung von Farben ist eine Möglichkeit, Gruppen in Streudiagrammen zu unterscheiden.
Eine weitere Möglichkeit ist die Verwendung unterschiedlicher Formen. Dazu müssen wir lediglich das
color-Argument durch dasshape-Argument ersetzen.Außerdem möchte ich die Größe anpassen, damit die Formen besser sichtbar sind. Da dies das Design der Punkte verändert, setzen wir das Argument
size = 2.5innerhalb dergeom_point()-Funktion.In der
labs()-Funktion ändern wir das Argumentcolor = "Produkt"zushape = "Produkt", da wir nun die Legende der Form-Ebene benennen und nicht mehr die der Farb-Ebene.
Schauen wir uns das Ergebnis an:
ggplot(data8, aes(x = marketing_budget,
y = sales,
shape = name)) +
geom_point(size = 2.5) +
scale_x_continuous(breaks = seq(0, 10000, 2000)) +
labs(
x = "Marketingbudget",
y = "Verkäufe pro Einheit",
title = "Schokolade: Verkäufe und Marketing",
shape = "Produkt"
) +
theme_classic() 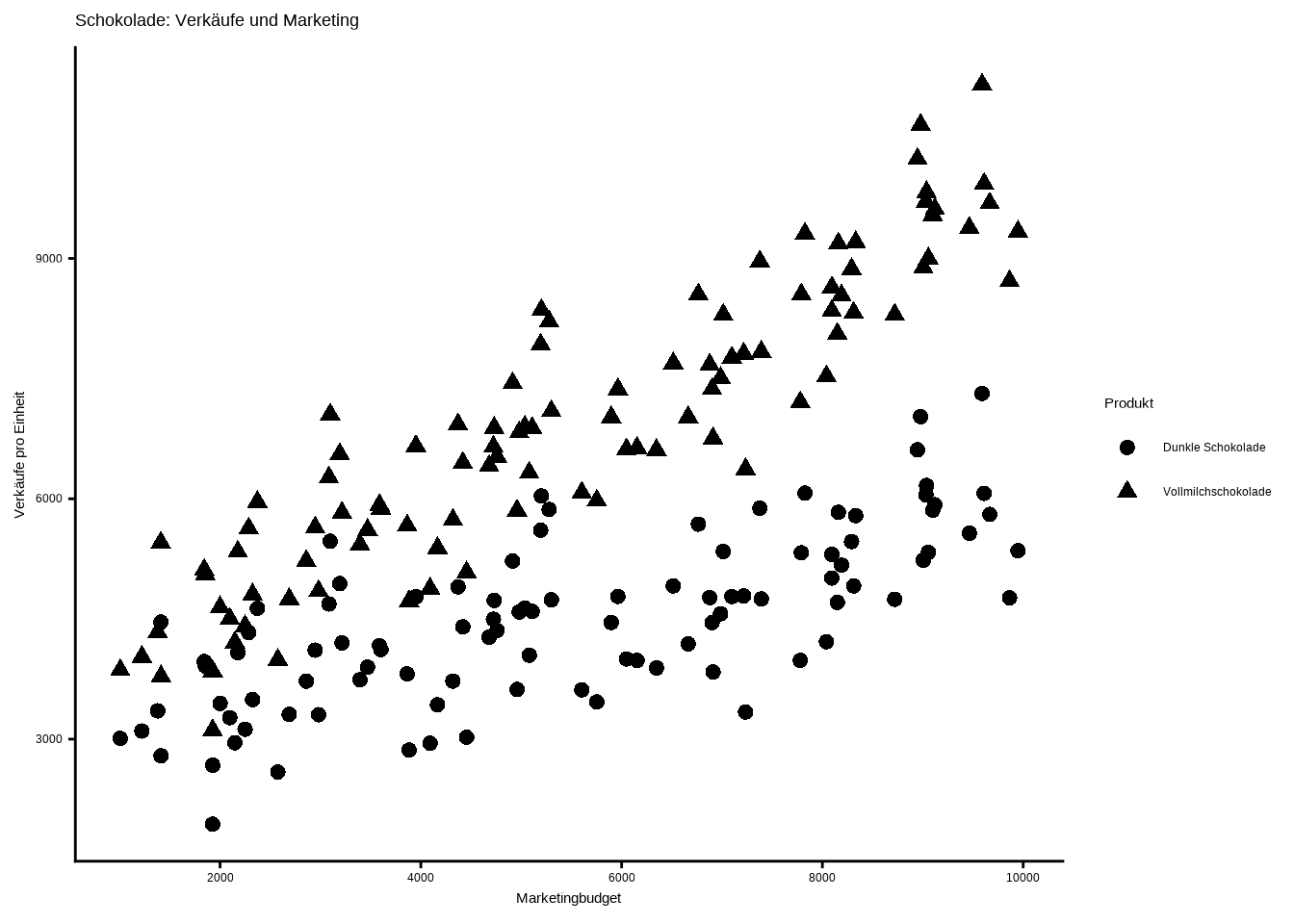
Es gibt verschiedene Formtypen, die wir manuell über Zahlen festlegen können.
Dazu können wir
scale_shape_manual()verwenden und das Argumentvaluesauf die entsprechende Formnummer setzen. Eine Übersicht der verfügbaren Formen findet ihr hier.Wir können auch verschiedene Farben mit verschiedenen Formen kombinieren, indem wir das Argument
color = namein derggplot()-Funktion belassen.In der
labs()-Funktion setzen wir danncolor = ""undshape = "", sodass die Legende die eingefärbten Formen anzeigt.
ggplot(data8, aes(x = marketing_budget,
y = sales,
shape = name,
color = name)) +
geom_point(size = 2.5) +
scale_color_manual(values = c("#e71d36",
"#260701")) +
scale_x_continuous(breaks = seq(0, 10000, 2000)) +
labs(
x = "Marketingbudget",
y = "Verkäufe pro Einheit",
title = "Schokolade: Verkäufe und Marketing",
shape = "",
color = ""
) +
theme_classic() 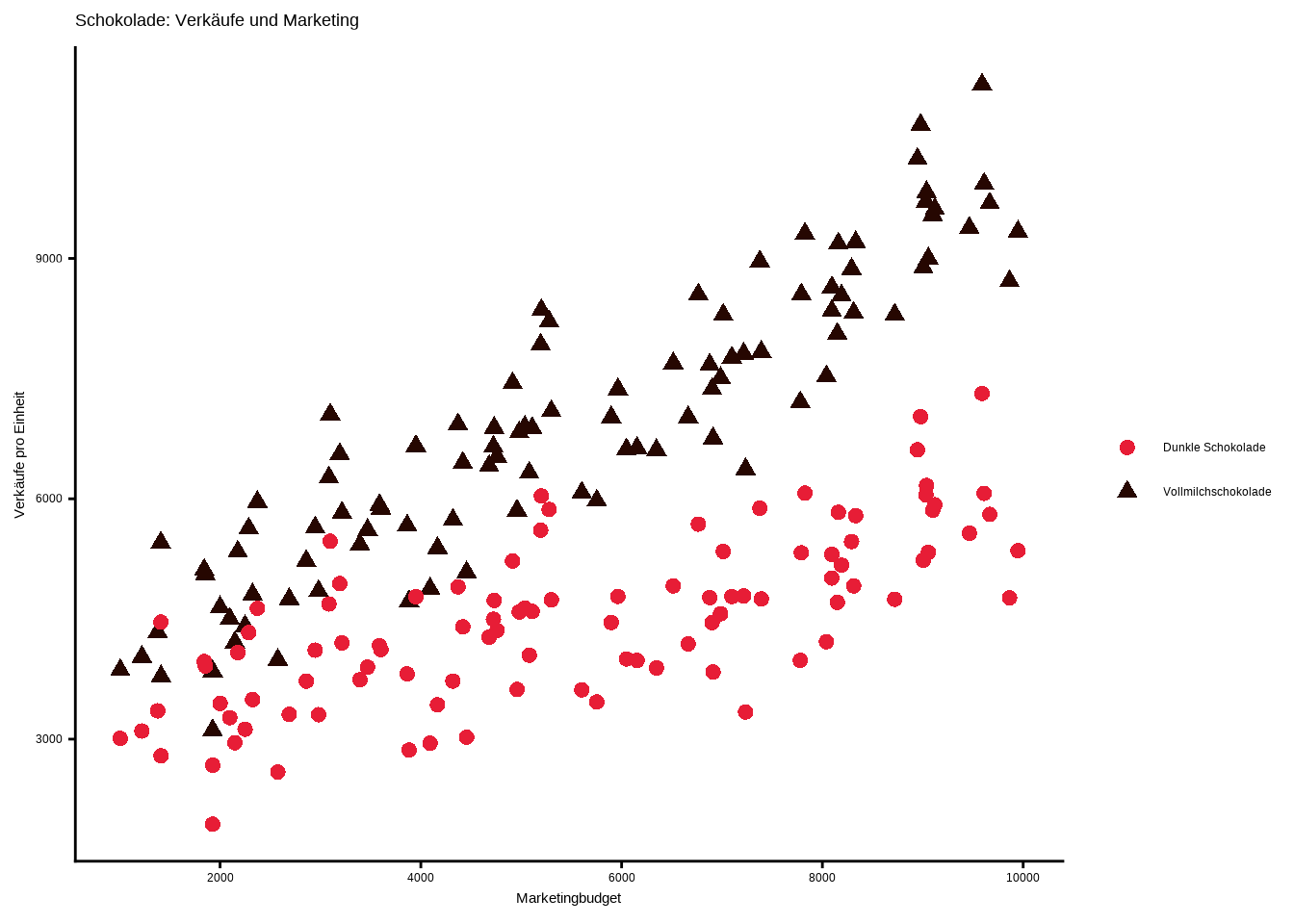
3.6 Plots mit facet_wrap() und facet_grid()
Manchmal möchten wir nicht die Elemente innerhalb eines Plots vergleichen (z. B. Punkte oder Linien), sondern den Plot selbst mit anderen Plots aus demselben Datensatz. Das kann ein sehr wirkungsvolles Mittel sein, um eine Geschichte mit Daten zu erzählen. Außerdem können wir durch das Aufteilen der Daten in mehrere Graphen viele Informationen auf einmal gewinnen und diese direkt miteinander vergleichen.
3.6.1 Die facet_wrap()-Funktion
Das klingt noch etwas abstrakt – bleiben wir bei unserem Schokoladenunternehmen. Wir möchten den Effekt unseres Marketingbudgets auf die Verkäufe für verschiedene Quartale vergleichen und denselben Scatterplot wie zuvor darstellen, diesmal jedoch für jedes Quartal separat. Natürlich könnten wir den Datensatz nach Quartal aufteilen und 4 einzelne Plots erstellen – aber das ist nicht effizient. Kopieren wir stattdessen den Code von oben und fügen die facet_wrap()-Funktion hinzu. Innerhalb dieser Funktion verwenden wir das Tilde-Symbol ~ gefolgt von der Variable, nach der wir aufteilen möchten – in unserem Fall die Quartale.
# Einfache facet_wrap()-Funktion
ggplot(data8, aes(x = marketing_budget,
y = sales)) +
geom_point() +
facet_wrap(~ quartale)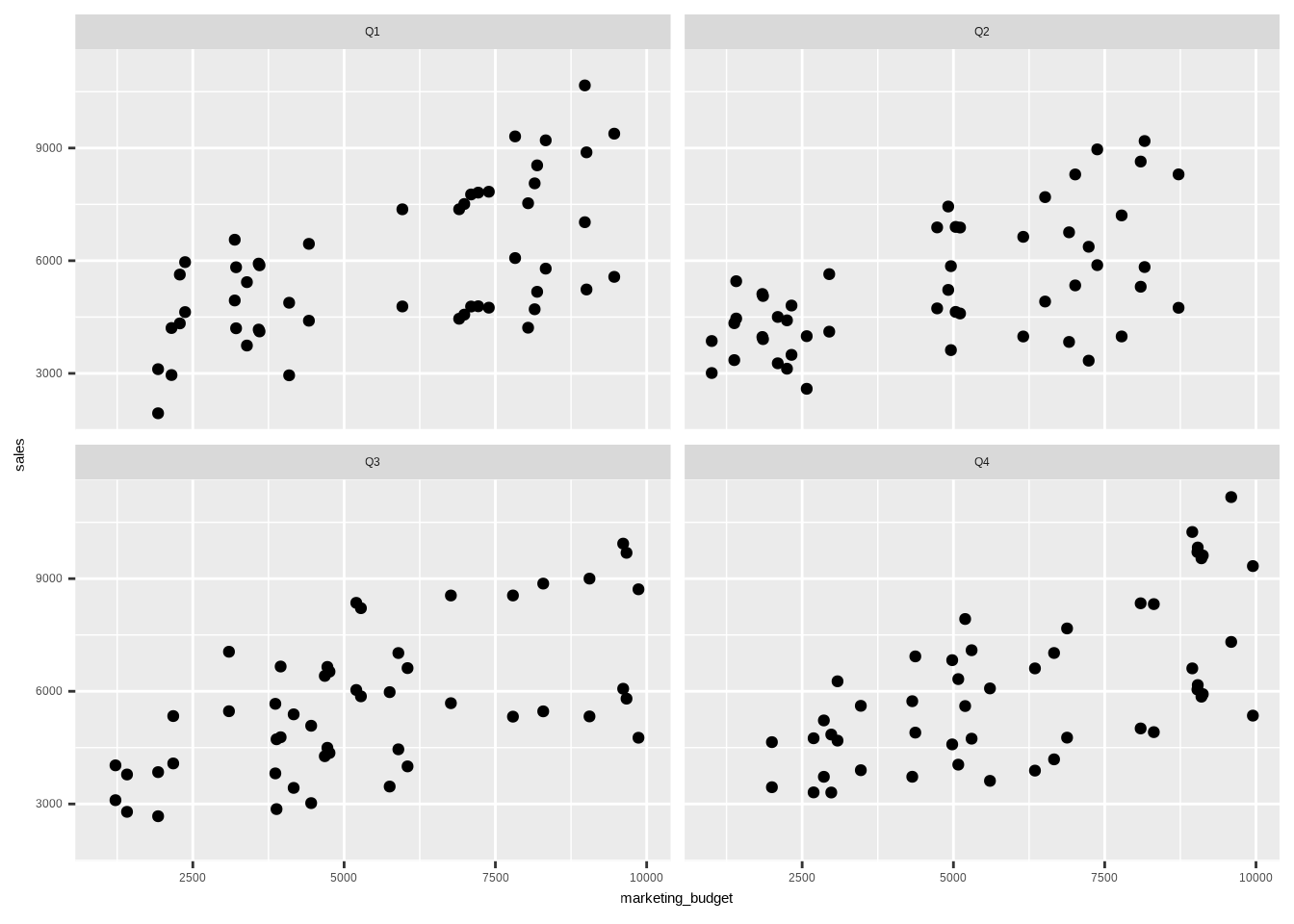
Wie wir sehen, erstellt ggplot2 automatisch 4 Graphen – einen für jedes Quartal. Anstatt 4 Graphen manuell zu erstellen und unnötig langen Code zu schreiben, können wir die praktische facet_wrap()-Funktion nutzen. Um die Graphen ansprechend zu gestalten, gehen wir genauso vor wie bei einem einzelnen Plot – wir können einfach den Code von oben übernehmen und ergänzen:
ggplot(data8, aes(x = marketing_budget,
y = sales)) +
geom_point(color = "#99582a") +
scale_x_continuous(breaks = seq(0, 10000, 2000)) +
labs(
x = "Marketingbudget",
y = "Verkäufe pro Einheit",
title = "Schokolade: Verkäufe und Marketing"
) +
theme_classic() +
facet_wrap(~ quartale)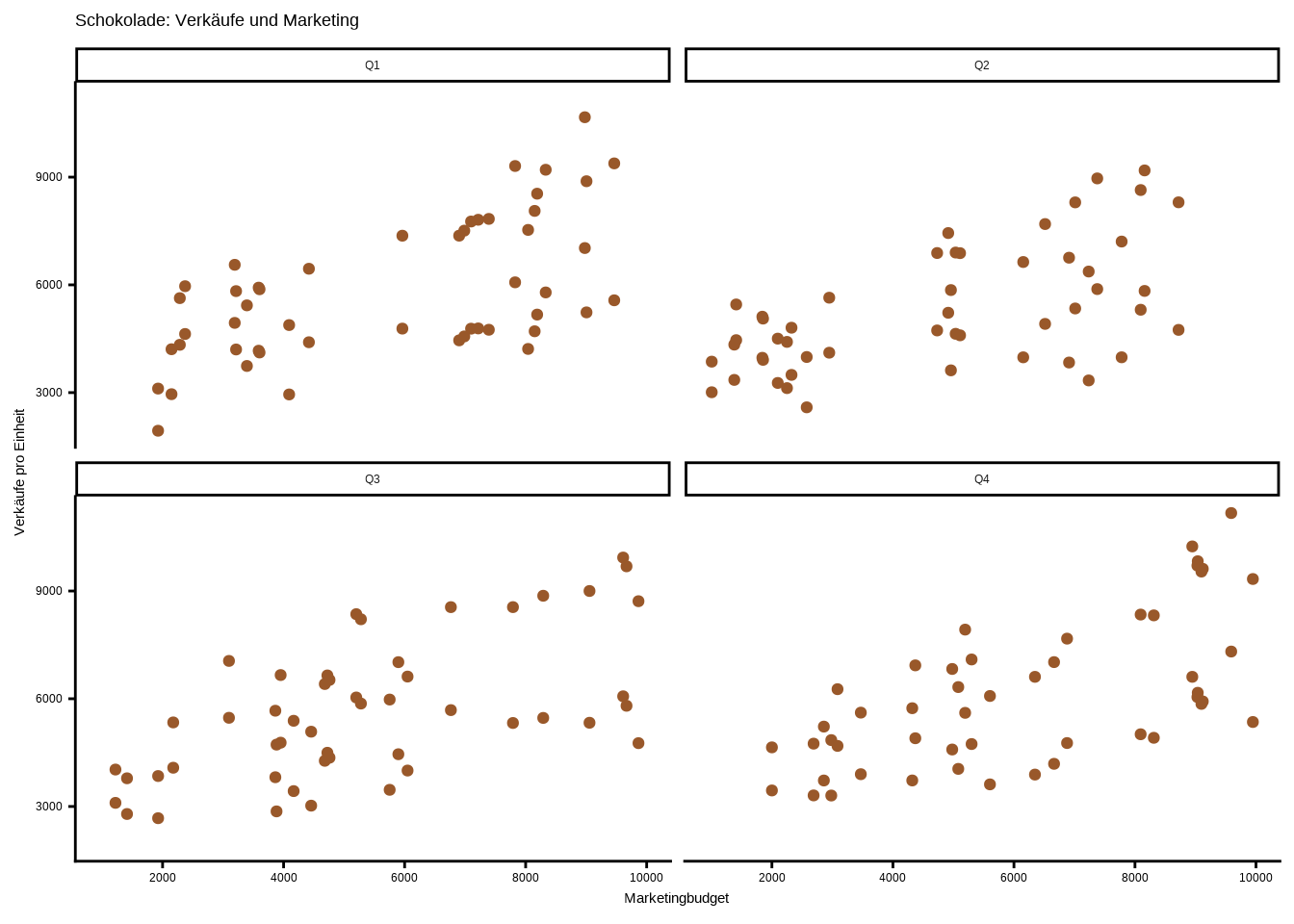
Wir können die facet_wrap()-Funktion auch auf unseren Plot mit verschiedenen Formen und Farben für Vollmilch- und dunkle Schokolade anwenden:
ggplot(data8, aes(x = marketing_budget,
y = sales,
shape = name,
color = name)) +
geom_point(size = 2.5) +
scale_color_manual(values = c("#e71d36",
"#260701")) +
scale_x_continuous(breaks = seq(0, 10000, 2000)) +
labs(
x = "Marketingbudget",
y = "Verkäufe pro Einheit",
title = "Schokolade: Verkäufe und Marketing",
shape = "",
color = ""
) +
theme_classic() +
facet_wrap(~ quartale)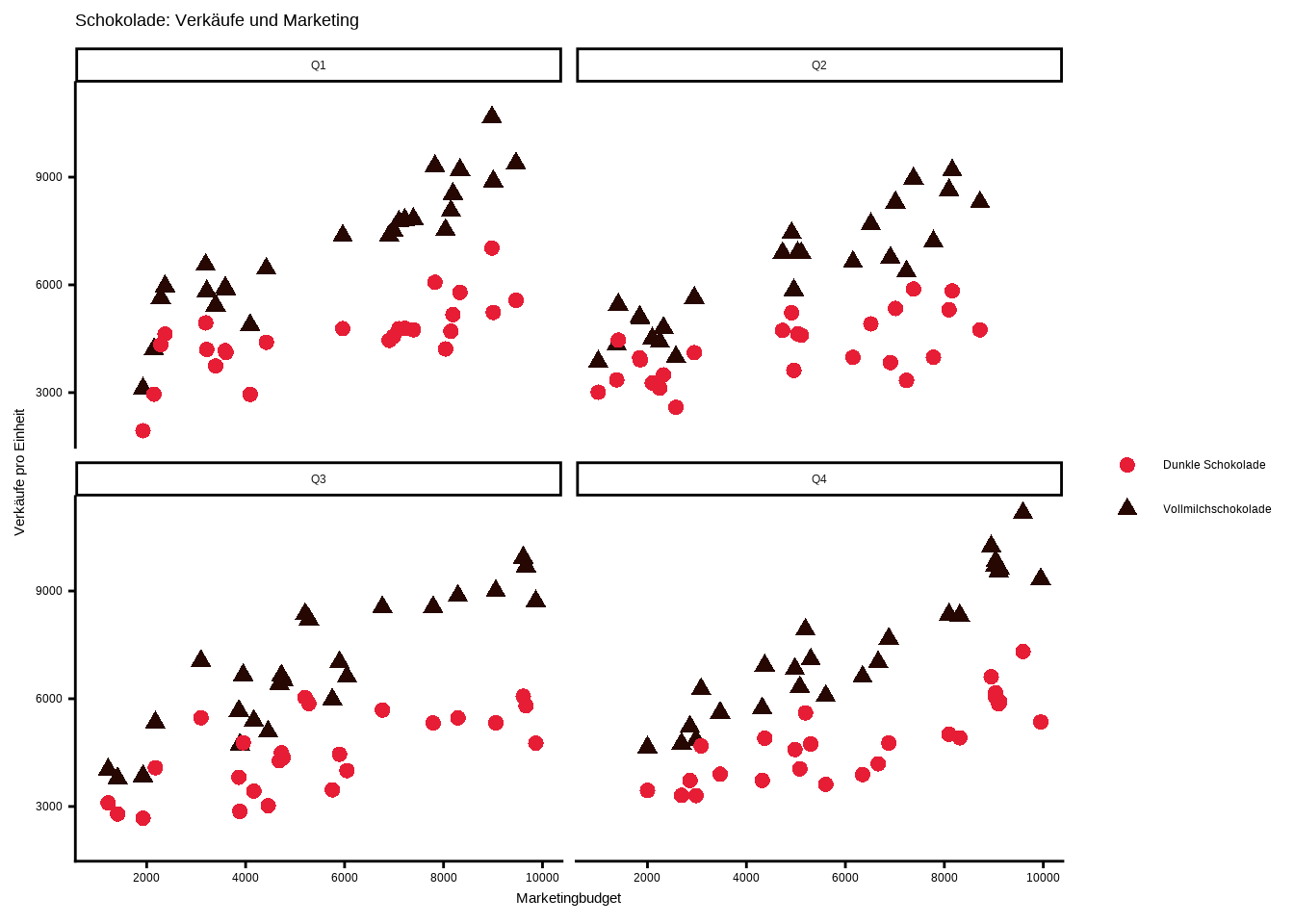
3.6.2 Die facet_grid()-Funktion
Die facet_grid()-Funktion funktioniert ähnlich wie facet_wrap(), ermöglicht jedoch eine zweite Dimension. Stellen wir uns vor, wir möchten die Temperaturentwicklung in den ersten vier Monaten der Jahre 2018, 2019 und 2020 für die Städte London, Paris und Berlin vergleichen. Diesmal entscheiden wir uns für ein Liniendiagramm. Manuell müssten wir neun Plots erstellen – einen pro Stadt und Jahr. Oder wir nutzen einfach die facet_grid()-Funktion:
Da wir zwei Dimensionen haben, müssen wir beide definieren. Wir legen zunächst die Zeile und dann die Spalte fest, getrennt durch das Tilde-Symbol
~:facet_grid(Zeile ~ Spalte).Wir verwenden die
geom_line()-Funktion und gestalten den Plot ansprechend: aussagekräftige Achsenbeschriftungen, eindeutige Farben für jedes Jahr, ein Titel, ein Theme und keine Legende, da diese ohnehin nur zeigen würde, dass die Jahre unterschiedliche Farben haben.
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Städte, Jahre und Monate definieren
städte <- c("London", "Paris", "Berlin")
jahre <- 2018:2020
monate <- 1:4 # Nur die ersten vier Monate
# Dataframe mit allen Kombinationen aus Stadt, Jahr und Monat erstellen
data9 <- expand.grid(Stadt = städte, Jahr = jahre, Monate = monate)
# Temperaturdaten mit städtespezifischer Variation simulieren
data9$Temperatur <- round(rnorm(nrow(data9), mean = 15, sd = 10), 1) +
with(data9, ifelse(Stadt == "London", 0, ifelse(Stadt == "Paris", 5, -5)))
# Erste Zeilen des Datensatzes prüfen
head(data9)## Stadt Jahr Monate Temperatur
## 1 London 2018 1 9.4
## 2 Paris 2018 1 17.7
## 3 Berlin 2018 1 25.6
## 4 London 2019 1 15.7
## 5 Paris 2019 1 21.3
## 6 Berlin 2019 1 27.2# Monat als Faktor für bessere Achsenbeschriftung umwandeln
data9$Monate <- factor(data9$Monate, levels = 1:4, labels = month.abb[1:4])
# ggplot-Objekt erstellen
p <- ggplot(data9, aes(x = Monate, y = Temperatur, group = Jahr, color = factor(Jahr))) +
geom_line() +
labs(title = "Durchschnittliche Monatstemperatur (Jan–Apr, 2018–2020)",
x = "Monat",
y = "Temperatur (°C)",
color = "Jahr") +
theme_bw() +
theme(legend.position = "none") +
facet_grid(Jahr ~ Stadt)
# Plot ausgeben
p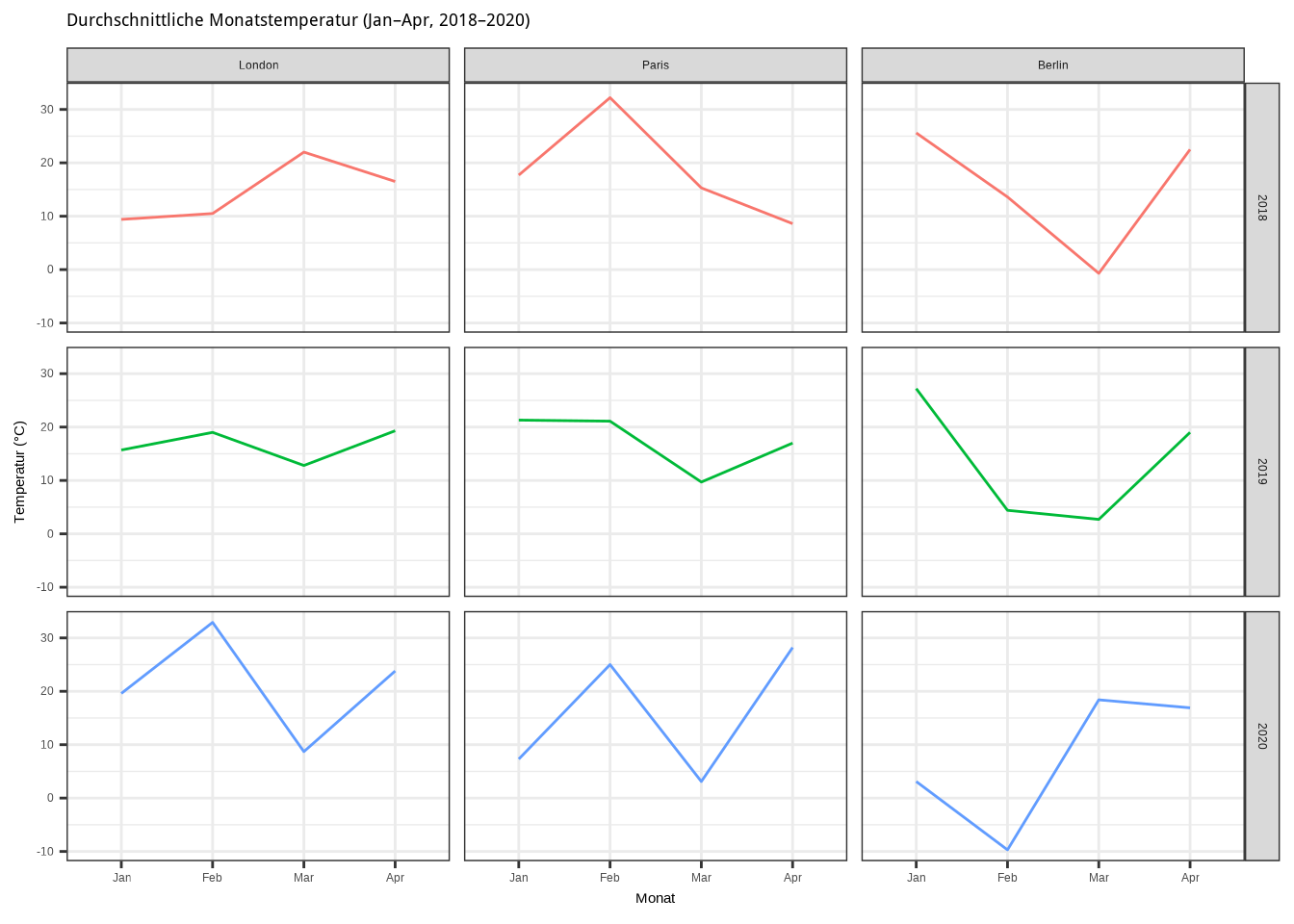
3.7 Zusammenfassung
Das war eine kurze Einführung in die Datenvisualisierung in R und die grundlegenden Visualisierungen, die in der Datenanalyse verwendet werden. Die meisten Visualisierungen beginnen mit diesen Grundplots, und wie ihr gesehen habt, ist der Arbeitsablauf immer gleich: Zunächst erstellt man den Grundplot, dann fügt man die gewünschten Ebenen hinzu. ggplot2 wirkt am Anfang kompliziert, aber da Datenvisualisierung eine zentrale Aufgabe in der Datenwissenschaft und Forschung ist, werdet ihr sehr schnell sehr routiniert damit umgehen.
Ich kann euch nur ermutigen, die Welt der Datenvisualisierung in R mit ggplot2 weiter zu erkunden. In diesem Abschnitt möchte ich einen kurzen Einblick geben, was an weiterführenden Grafiken möglich ist:
3.7.1 Verschiedene Graphentypen kombinieren
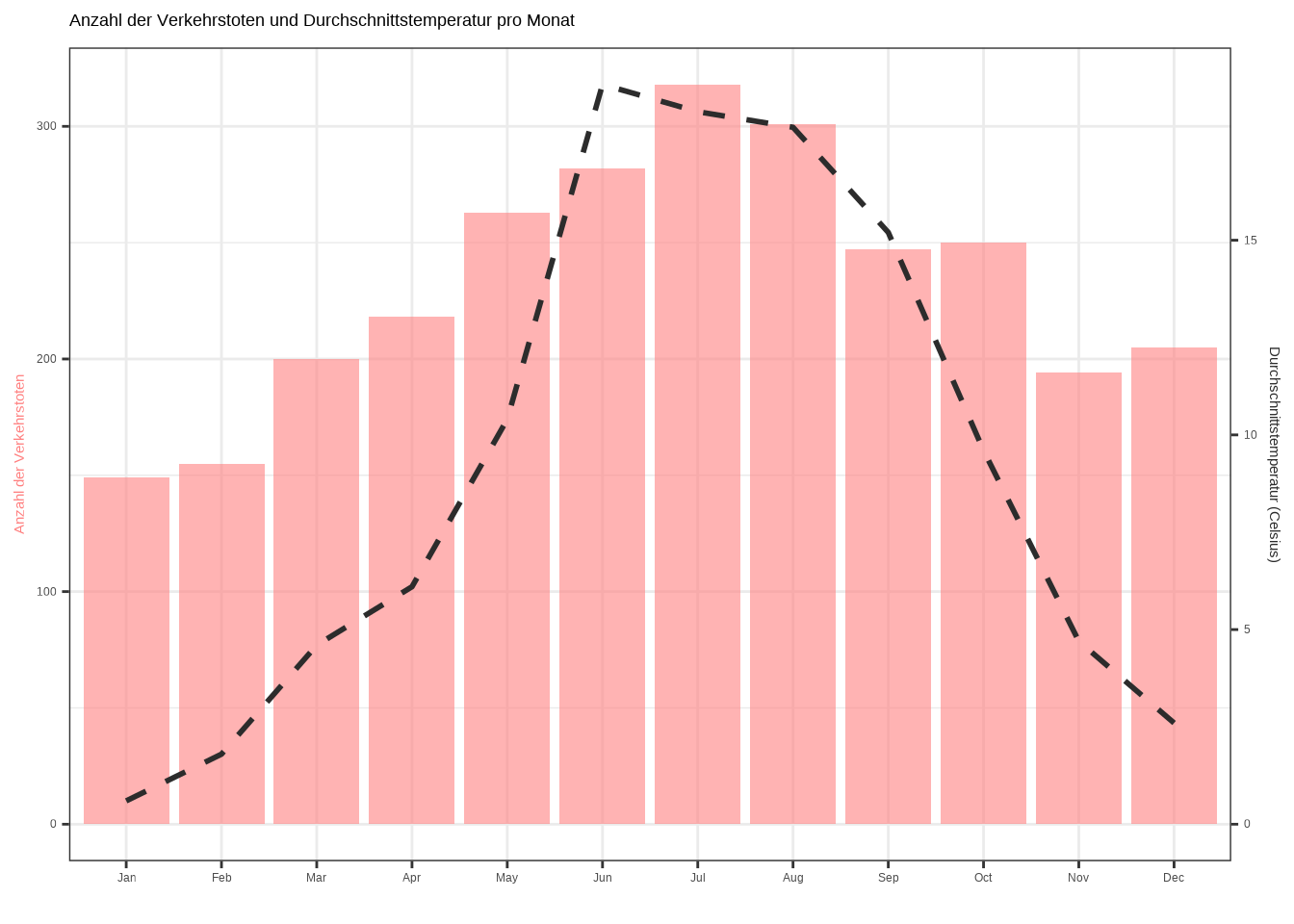
Man kann auch verschiedene Graphentypen miteinander kombinieren. Aber Vorsicht! Zu viele Elemente in einem Graphen können ablenkend wirken. Im Folgenden präsentiere ich einen Graphen mit zwei y-Achsen – eine für ein Liniendiagramm mit Punkten und eine für einen Barplot. Die x-Achse zeigt die Monate des Jahres:
# Beispieldaten simulieren
data10 <- data.frame(
monate = factor(1:12, levels = 1:12, labels = month.abb),
durch_temp = c(0.6, 1.8, 4.6, 6.1, 10.4, 19, 18.3,
17.9, 15.2, 9.6, 4.7, 2.6),
n_tote = c(149, 155, 200, 218, 263, 282,
318, 301, 247, 250, 194, 205)
)
# Skalierungsfaktor, um avg_temp an n_deaths anzupassen
scale_factor <- max(data10$n_tote) / max(data10$durch_temp)
# Kombinierten Graphen mit zwei y-Achsen erstellen
ggplot(data10, aes(x = monate)) +
geom_bar(aes(y = n_tote), stat = "identity", fill = "#FF8080",
alpha = 0.6) +
geom_line(aes(y = durch_temp * scale_factor, group = 1),
color = "#2c2c2c", linewidth = 1, linetype = "dashed") +
scale_y_continuous(
name = "Anzahl der Verkehrstoten",
sec.axis = sec_axis(~ . / scale_factor, name = "Durchschnittstemperatur (Celsius)")
) +
labs(x = "",
title = "Anzahl der Verkehrstoten und Durchschnittstemperatur pro Monat") +
theme_bw() +
theme(
axis.title.y.left = element_text(color = "#FF8080"),
axis.title.y.right = element_text(color = "#2c2c2c")
)
3.7.2 Verteilungen: Ridgeline Chart und Violin Chart
Zwei Visualisierungen, die immer beliebter werden: der Ridgeline Chart und der Violin Chart.
Der Violin Chart stellt einen Dichtegraphen horizontal dar und spiegelt ihn zusätzlich, sodass eine symmetrische Form entsteht:
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Beispiel-Sportdaten simulieren
sport_data <- data.frame(
sport = factor(rep(c("Basketball", "Fußball", "Schwimmen", "Turnen", "Tennis"), each = 100)),
größe = c(
rnorm(100, mean = 200, sd = 10), # Basketballspieler sind typischerweise groß
rnorm(100, mean = 175, sd = 7), # Fußballspieler haben eine durchschnittliche Größe
rnorm(100, mean = 180, sd = 8), # Schwimmer
rnorm(100, mean = 160, sd = 6), # Turner sind typischerweise kleiner
rnorm(100, mean = 170, sd = 9) # Tennisspieler
)
)
# Violin Chart erstellen
ggplot(sport_data, aes(x = sport, y = größe, fill = sport)) +
geom_violin(trim = FALSE) +
labs(
title = "Verteilung der Körpergröße von Athleten nach Sportart",
x = "Sportart",
y = "Größe (cm)"
) +
theme_bw() +
theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
axis.title.x = element_text(size = 14),
axis.title.y = element_text(size = 14)
) +
scale_fill_brewer(palette = "RdBu")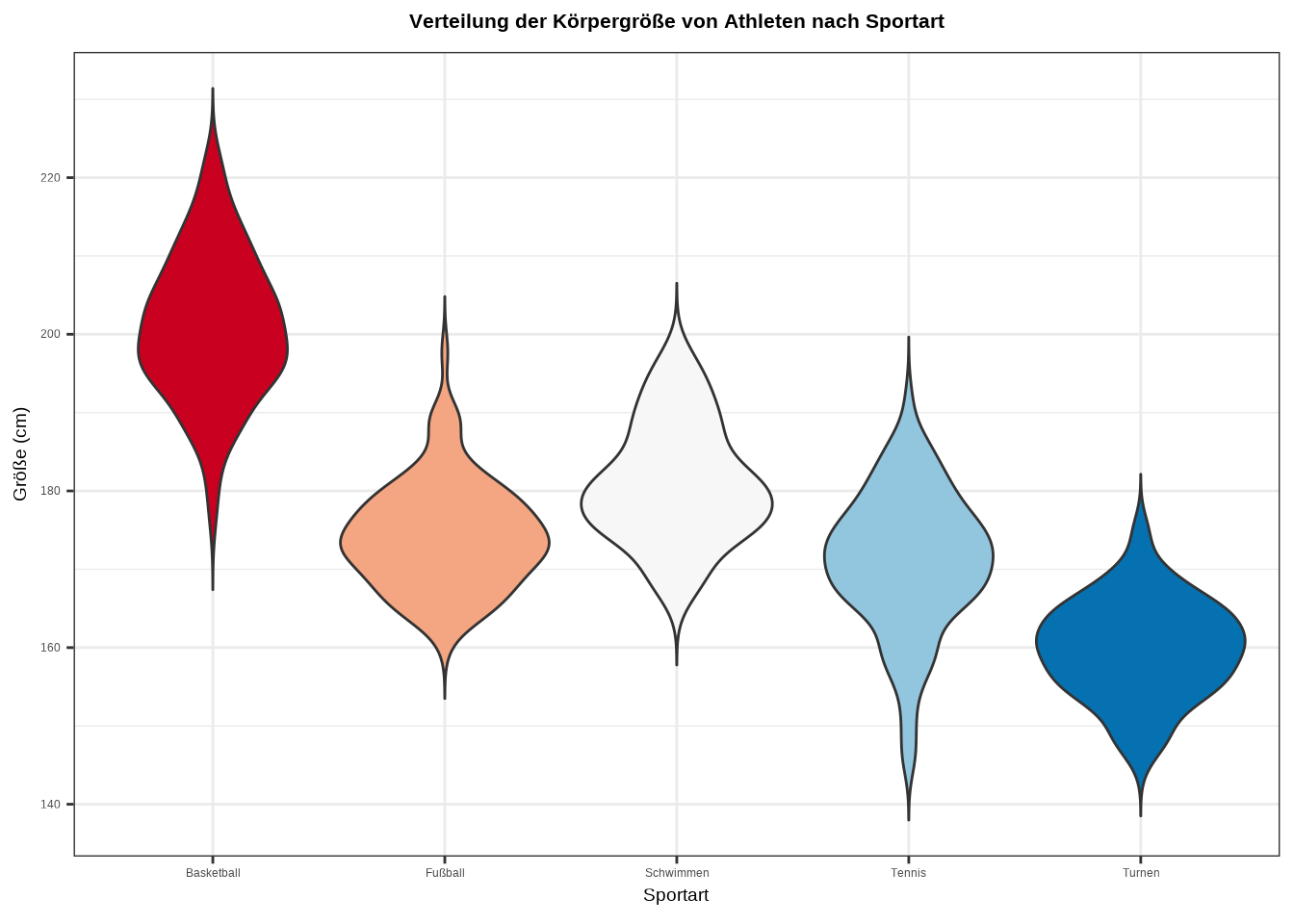
Der Ridgeline Chart ist eine elegante Möglichkeit, mehr als zwei Verteilungen miteinander zu vergleichen. Die Idee dabei ist, die Skala auf der x-Achse darzustellen und auf der y-Achse die zu vergleichenden Gruppen abzutragen:
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Normalverteilung
normal_data <- rnorm(1000, mean = 50, sd = 10)
# Linkschiefe Verteilung (mit Exponentialverteilung)
linksschief_data <- rexp(1000, rate = 0.1)
# Rechtschiefe Verteilung (mit Log-Normalverteilung)
rechtsschief_data <- rlnorm(1000, meanlog = 3, sdlog = 0.5)
# Bimodale Verteilung (Kombination zweier Normalverteilungen)
bimodal_data <- c(rnorm(500, mean = 35, sd = 5), rnorm(500, mean = 60, sd = 5))
# Daten zu einem Dataframe zusammenfügen
beispiel_data <- data.frame(
wert = c(normal_data, linksschief_data, rechtsschief_data, bimodal_data),
verteilung = factor(rep(c("Normal", "Linksschief", "Rechtsschief", "Bimodal"), each = 1000))
)
# Ridgeline Chart erstellen
ggplot(beispiel_data, aes(x = wert, y = verteilung, fill = verteilung)) +
geom_density_ridges() +
scale_fill_brewer(palette = "Dark2") +
labs(
x = "Werte",
y = "Verteilung",
title = "Ein Ridgeline Chart"
) +
theme_ridges() +
theme(legend.position = "none")## Picking joint bandwidth of 2.34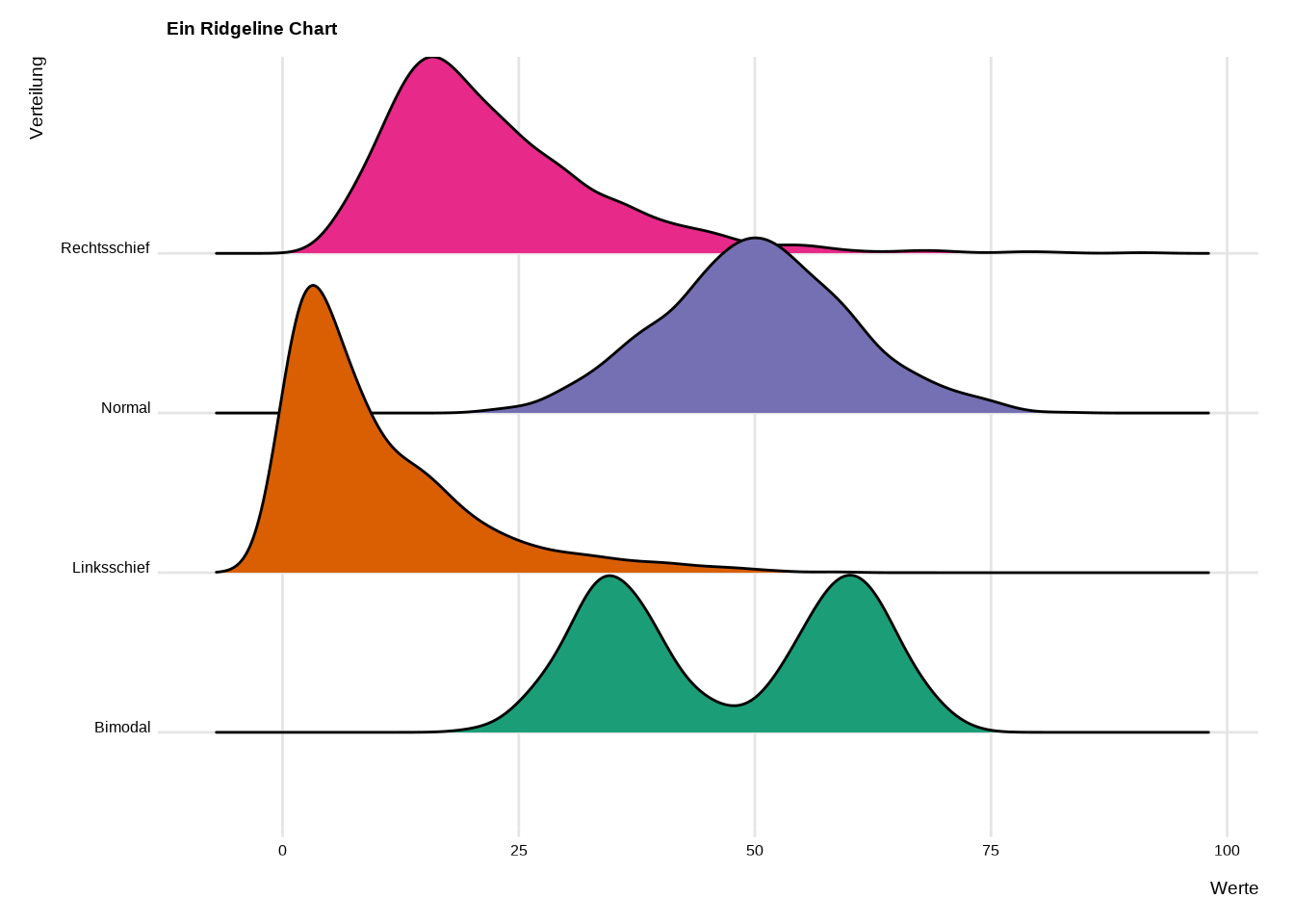
3.7.3 Rangfolge: Lollipop Charts und Radar Charts
3.7.3.1 Lollipop Charts
Lollipop Charts werden immer beliebter, daher möchte ich sie euch vorstellen. Die Idee ist denkbar einfach: Es handelt sich um einen Barplot, bei dem anstelle eines Balkens eine Linie mit einem Punkt verwendet wird:
- Zur Umsetzung benötigen wir eine
geom_point()-Ebene in Kombination mit einergeom_segment()-Ebene. - Die Achsen werden innerhalb der
ggplot()-Ebene definiert. - Abschließend müssen wir die Ästhetik im
geom_segment()-Plot festlegen.
ggplot(data4, aes(x=name, y=stärke)) +
geom_point() +
geom_segment(aes(x=name, xend=name, y=0, yend=stärke))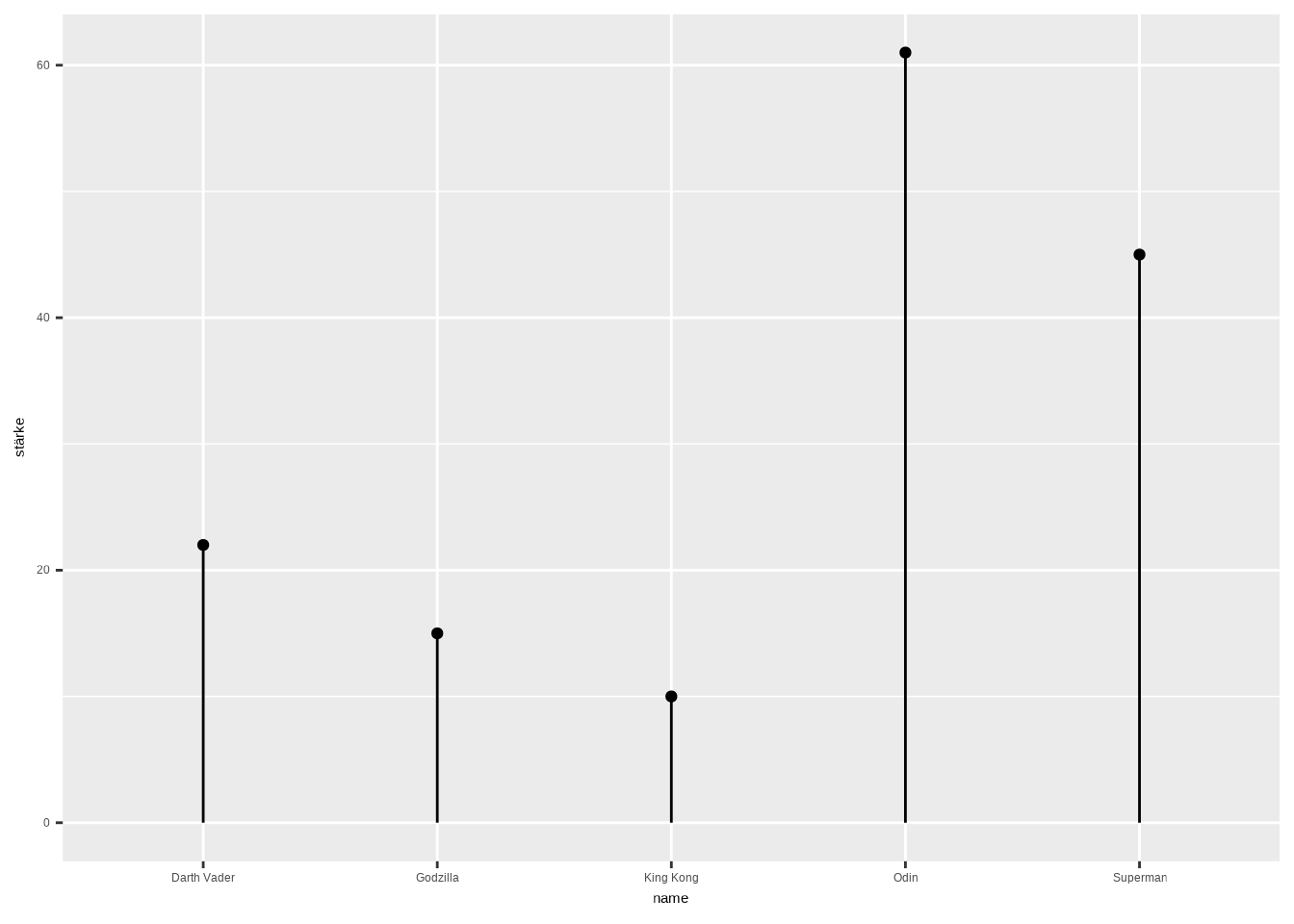
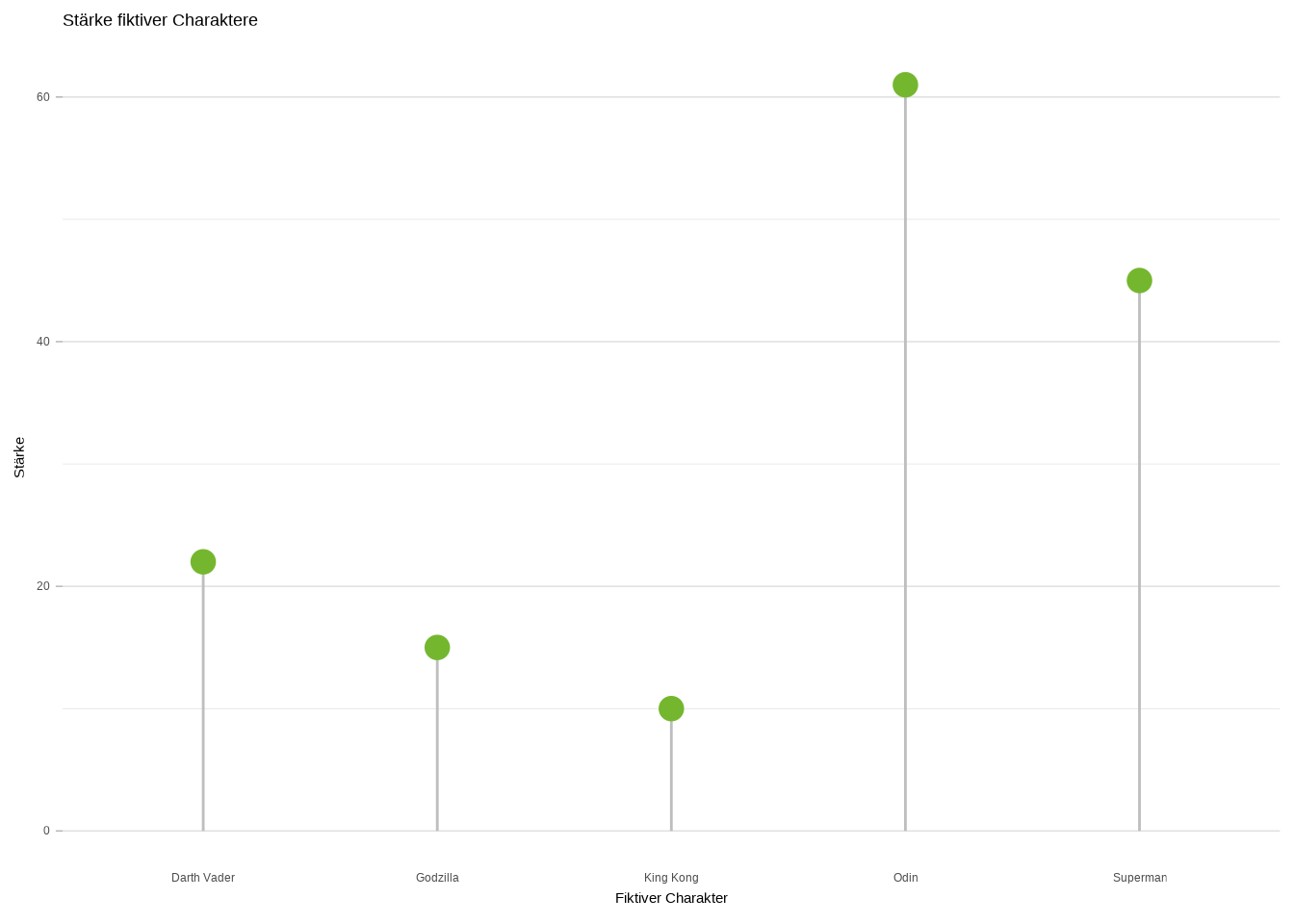
Nun gestalten wir den Chart ansprechender. Wir können der Linie verschiedene Farben geben und sie mit denselben Methoden wie beim Liniendiagramm anpassen. Das Gleiche gilt für die Punkte – auch sie lassen sich beliebig anpassen:
ggplot(data4, aes(x=name, y=stärke)) +
geom_segment(aes(x=name, xend=name, y=0, yend=stärke),
color = "grey") +
geom_point(size = 4, color = "#74B72E") +
labs(x = "Fiktiver Charakter",
y = "Stärke",
title = "Stärke fiktiver Charaktere") +
theme_light() +
theme(
panel.grid.major.x = element_blank(),
panel.border = element_blank(),
axis.ticks.x = element_blank()
) 
3.7.4 Karten
R bietet auch eine Vielzahl von Möglichkeiten, mit räumlichen Daten zu arbeiten. Die Visualisierung von Karten ist natürlich ein wesentlicher Bestandteil, wenn man mit räumlichen Daten arbeitet. Mit R lassen sich alle Arten von Karten erstellen: interaktive Karten mit leaflet, Shapefiles von Ländern und mehrere Ebenen mit dem sf-Paket sowie Standardvisualisierungen wie Verbindungskarten oder Kartogramme.
Hier ist ein Beispiel einer interaktiven, mit Daten befüllten Karte. Um den Code so einfach wie möglich zu halten, habe ich das tmap-Paket verwendet. Es handelt sich um eine Weltkarte, die über ihre Farbe anzeigt, ob ein Land ein Hocheinkommens-, oberes Mitteleinkommens-, unteres Mitteleinkommens- oder Niedrigeinkommensland ist:
# Shapefiles auf Länderebene laden
world <- ne_countries(scale = "medium", returnclass = "sf")
world <- world %>%
filter(gdp_year == 2019) %>%
mutate(`Einkommensgruppe` = case_when(
income_grp %in% c("1. High income: OECD",
"2. High income: nonOECD") ~ "1. Hohe Einkommen",
income_grp == "3. Upper middle income" ~ "2. Obere Mitteleinkommen",
income_grp == "4. Lower middle income" ~ "3. Untere Mitteleinkommen",
income_grp == "5. Low income" ~ "4. Niedrige Einkommen")
)
# Mit tmap darstellen
tmap_mode("view")## tmap mode set to interactive viewing3.8 Ausblick
Dieses Kapitel war eine Einführung in einen der schönsten Teile von R – das Erstellen von Plots. Ich habe euch die Standardformen der Visualisierung vorgestellt und einen kleinen Ausblick auf weiterführende Visualisierungen und die Möglichkeiten in R gegeben. Das Paket ggplot2 ist eines der intuitivsten (wenn auch nicht für Anfänger) für die Datenvisualisierung.
- Es gibt nur ein Buch, das ich zur Datenvisualisierung unbedingt empfehlen möchte: das „R Gallery Book” von Kyle W. Brown. Schaut euch auch die Website zu diesem Buch an – sie ist die Standardreferenz, auf der ich nach Code-Snippets für Graphen suche, und ich kann sie nur wärmstens empfehlen.
3.9 Übungsaufgaben
In diesem Übungsabschnitt arbeiten wir mit dem iris-Datensatz. Dabei handelt es sich um einen klassischen eingebauten Datensatz in R, der Daten aus Ronald Fishers Studie von 1936 „The use of multiple measurements in taxonomic problems” enthält. Er umfasst drei Pflanzenarten sowie vier gemessene Merkmale für jede Art. Verschaffen wir uns zunächst einen Überblick:
## Sepal.Length Sepal.Width Petal.Length
## Min. :4.300 Min. :2.000 Min. :1.000
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600
## Median :5.800 Median :3.000 Median :4.350
## Mean :5.843 Mean :3.057 Mean :3.758
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100
## Max. :7.900 Max. :4.400 Max. :6.900
## Petal.Width Species
## Min. :0.100 setosa :50
## 1st Qu.:0.300 versicolor:50
## Median :1.300 virginica :50
## Mean :1.199
## 3rd Qu.:1.800
## Max. :2.5003.9.1 Übung 1: Verteilungen
a. Erstelle einen Graphen, der die Verteilung von Sepal.Length für die Art setosa zeigt. Wähle den Verteilungsplottyp selbst. Hinweis: Bereite die Daten zunächst auf, bevor du sie plottest.
b. Füge nun die beiden anderen Arten zum Plot hinzu. Stelle sicher, dass jede Art eine eindeutige Farbe hat.
c. Gestalte den Plot ansprechend! Gib dem Plot einen aussagekräftigen Titel sowie aussagekräftige Beschriftungen für die x- und y-Achse, und experimentiere mit den Farben.
d. Interpretiere den Plot!
3.9.2 Übung 2: Rangfolgen
a. Berechne die durchschnittliche Petal.Length für jede Art und stelle sie in einem Barplot dar. Hinweis: Du musst die Daten erneut aufbereiten, bevor du sie plottest.
b. Füge die Mittelwerte der Variable Petal.Width zum Plot hinzu, sodass ein gruppierter Barplot entsteht.
c. Gestalte den Plot ansprechend! Gib dem Plot einen aussagekräftigen Titel sowie aussagekräftige Beschriftungen für die x- und y-Achse, und experimentiere mit den Farben.
d. Interpretiere den Plot!
3.9.3 Übung 3: Korrelation
a. Erstelle ein Streudiagramm, bei dem Sepal.Length auf der x-Achse und Sepal.Width auf der y-Achse dargestellt wird. Erstelle den Plot für die Art virginica.
b. Füge nun die Art versicolor zum Plot hinzu. Die Punkte dieser Art sollen eine andere Farbe UND eine andere Form haben.
c. Gestalte den Plot ansprechend! Füge ein Theme, Achsenbeschriftungen und einen aussagekräftigen Titel hinzu.