Chapter 8 Lösungen zu den Übungsaufgaben
8.1 Kapitel 1: Grundlagen
8.1.1 Übung 1: Deinen ersten Vektor erstellen
Erstelle einen Vektor namens my_vector mit den Werten 1, 2, 3 und überprüfe seine Klasse.
8.1.2 Übung 2: Deine erste Matrix erstellen
Erstelle eine Matrix namens student. Diese soll Informationen über name, age und major enthalten. Erstelle drei Vektoren mit je drei Einträgen und verbinde sie zur Matrix student. Gib die Matrix aus. Die Namen, das Alter und das Studienfach kannst du frei wählen:
8.1.3 Übung 3: ifelse-Funktion
Schreibe eine ifelse-Anweisung, die prüft, ob eine gegebene Zahl positiv oder negativ ist. Wenn die Zahl positiv oder 0 ist, gib „Zahl ist positiv” aus, andernfalls „Zahl ist negativ”. Du kannst selbst entscheiden, ob du die ifelse()-Funktion oder die ifelse-Bedingung verwenden möchtest.
8.1.4 Übung 4: ifelse-Leitern
Schreibe eine if-else-Leiter, die die Note eines Studierenden anhand ihres Punktestands kategorisiert. Die Bewertungskriterien lauten:
Punktzahl >= 90: „A”; Punktzahl >= 80 und < 90: „B”; Punktzahl >= 70 und < 80: „C”; Punktzahl >= 60 und < 70: „D”; Punktzahl < 60: „F”.
# Vektor Score definieren
Score <- 90
# ifelse-Leiter mit der ifelse()-Funktion
ifelse(Score >= 90, "A",
ifelse(Score >= 80 & Score < 90, "B",
ifelse(Score >= 70 & Score < 80, "C",
ifelse(Score >= 60 & Score < 70, "D",
ifelse(Score < 60, "F")))))
# ifelse-Leiter mit einer ifelse-Bedingung
if (score >= 90) {
print("A")
} else if (score >= 80 & score < 90) {
print("B")
} else if (score >= 70 & score < 80) {
print("C")
} else if (score >= 60 & score < 70) {
print("D")
} else if (score < 60) {
print("F")
}8.2 Kapitel 2: Datenmanipulation
8.2.1 Übung 1: Ran an die Daten!
Du interessierst dich für Diskriminierung und die Wahrnehmung der Justiz. Genauer gesagt möchtest du wissen, ob Menschen, die sich diskriminiert fühlen, Gerichte anders bewerten. In der folgenden Tabelle siehst du alle Variablen, die du in deine Analyse einbeziehen möchtest:
|
Beschreibung | Skalen |
| idnt | I dentifikations-nummer der befragten Person | eindeutige Nummer von 1–9000 |
| year | Jahr der Durchführung der Befragung | nur 2020 |
| cntry | Land | BE, BG, CH, CZ, EE, FI, FR, GB, GR, HR, HU, IE, IS, IT, LT, NL, NO, PT, SI, SK | |
| agea | Alter der befragten Person, berechnet | Alter in Jahren = 15–90 999 = Nicht verfügbar |
| gndr | Geschlecht | 1 = Männlich; 2 = Weiblich; 9 = Keine Antwort |
| happy | Wie glücklich bist du? | 0 (Extrem unglücklich) – 10 (Extrem glücklich); 77 = Verweigerung; 88 = Weiß nicht; 99 = Keine Antwort |
| eisced | Höchster Bildungsabschluss, ES-ISCED | 0 = Nicht in ES-ISCED harmonisierbar; 1 (ES-ISCED I, unter Sekundarstufe I) – 7 (ES-ISCED V2, höhere Tertiärbildung, >= MA-Niveau); 55 = Sonstiges; 77 = Verweigerung; 88 = Weiß nicht; 99 = Keine Antwort |
|
Internetnutzung, wie oft | 1 (Nie) – 5 (Jeden Tag); 7 = Verweigerung; 8 = Weiß nicht; 9 = Keine Antwort |
| trstprl | Den meisten Menschen kann man vertrauen oder man kann nicht vorsichtig genug sein | 0 (Man kann nicht vorsichtig genug sein) – 10 (Den meisten Menschen kann man vertrauen); 77 = Verweigerung; 88 = Weiß nicht; 99 = Keine Antwort |
| lrscale | Li nks-Rechts-Einstufung | 0 (Links) – 10 (Rechts); 77 = Verweigerung; 88 = Weiß nicht; 99 = Keine Antwort |
| dscrgrp | Würden Sie sich selbst als Mitglied einer Gruppe beschreiben, die diskriminiert wird in diesem Land? | 1 = Ja; 2 = Nein; 77 = Verweigerung; 88 = Weiß nicht; 99 = Keine Antwort |
- Bereinige die Daten und weise sie einem Objekt namens ess zu.
- Wähle die benötigten Variablen aus.
- Filtere nach Österreich, Belgien, Dänemark, Georgien, Island und der Russischen Förderation.
- Schau dir das Codebuch an und kodiere alle irrelevanten Werte als fehlend. Bei binären Variablen rekodiere von 1, 2 zu 0 und 1.
- Erstelle eine Extremismus-Variable: Subtrahiere 5 von der Variable und quadriere das Ergebnis. Nenne sie
extremism. - Benenne die Variablen intuitiver um. Vergiss nicht, binäre Variablen nach der Kategorie zu benennen, die mit 1 kodiert ist.
- Entferne alle fehlenden Werte.
- Schau dir deinen neuen Datensatz an.
ess <- d1 %>%
select(cntry, dscrgrp, agea, gndr, eisced, lrscale) %>% # a
filter(cntry %in% c("AT", "BE", "DK", "GE", "IS", "RU")) %>% # b
mutate(dscrgrp = case_when( # c
dscrgrp == 1 ~ 0,
dscrgrp == 2 ~ 1,
dscrgrp %in% c(7, 8, 9) ~ NA_real_,
TRUE ~ dscrgrp),
agea = case_when(
agea == 999 ~ NA_real_,
TRUE ~ agea),
gndr = case_when(
gndr == 1 ~ 0,
gndr == 2 ~ 1,
gndr == 9 ~ NA_real_
),
eisced = case_when(
eisced %in% c(55, 77, 88, 99) ~ NA_real_,
TRUE ~ eisced),
lrscale = case_when(
lrscale %in% c(77, 88, 99) ~ NA_real_,
TRUE ~ lrscale) # d: dieser Schritt kann auch in einer separaten mutate()-Funktion erfolgen
) %>%
mutate(extremism = (lrscale - 5)^2) %>%
rename(discriminated = dscrgrp,
court = cttresa,
age = agea,
female = gndr,
education = eisced,
lrscale = lrscale,
extremism = extremism
) %>%
drop_na()
# Datensatz prüfen
head(ess)8.3 Kapitel 3: Datenvisualisierung
In diesem Übungsabschnitt arbeiten wir mit den Paketen babynames und iris. Das iris-Paket ist ein klassisches eingebautes Paket in R, das Daten aus Ronald Fishers Studie von 1936 „The use of multiple measurements in taxonomic problems” enthält. Es beinhaltet drei Pflanzenarten und vier gemessene Merkmale für jede Art. Verschaffen wir uns einen Überblick:
## Sepal.Length Sepal.Width Petal.Length
## Min. :4.300 Min. :2.000 Min. :1.000
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600
## Median :5.800 Median :3.000 Median :4.350
## Mean :5.843 Mean :3.057 Mean :3.758
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100
## Max. :7.900 Max. :4.400 Max. :6.900
## Petal.Width Species
## Min. :0.100 setosa :50
## 1st Qu.:0.300 versicolor:50
## Median :1.300 virginica :50
## Mean :1.199
## 3rd Qu.:1.800
## Max. :2.5008.3.1 Übung 1: Verteilungen
a. Erstelle einen Graphen, der die Verteilung von Sepal.Length für die Art setosa zeigt. Den Typ des Verteilungsgraphen kannst du selbst wählen. Hinweis: Bereite die Daten zunächst auf und erstelle dann den Plot.
# Filtern nach setosa
d1 <- iris %>%
filter(Species == "setosa")
# Histogramm
ggplot(iris, aes(x = Sepal.Length)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.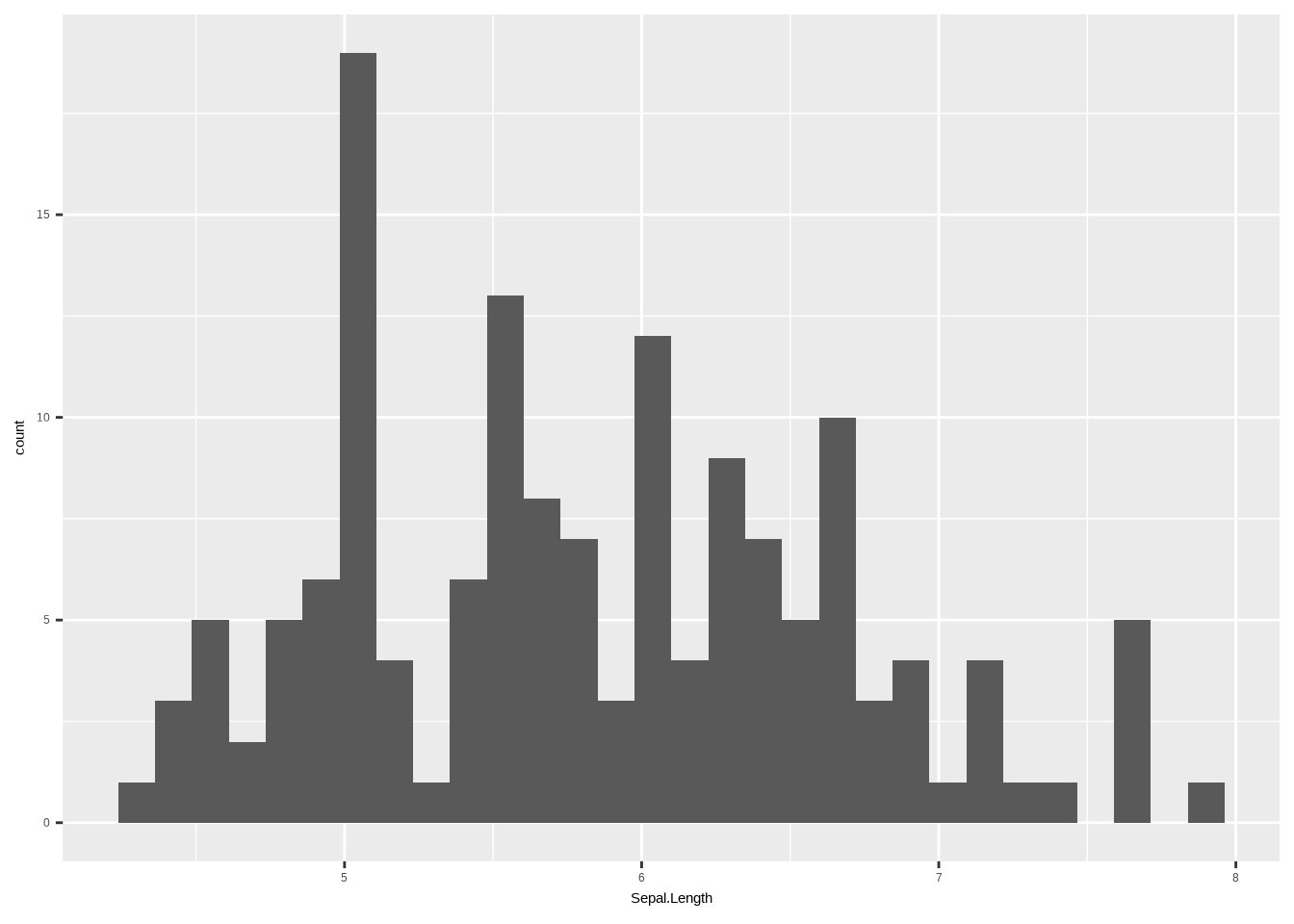
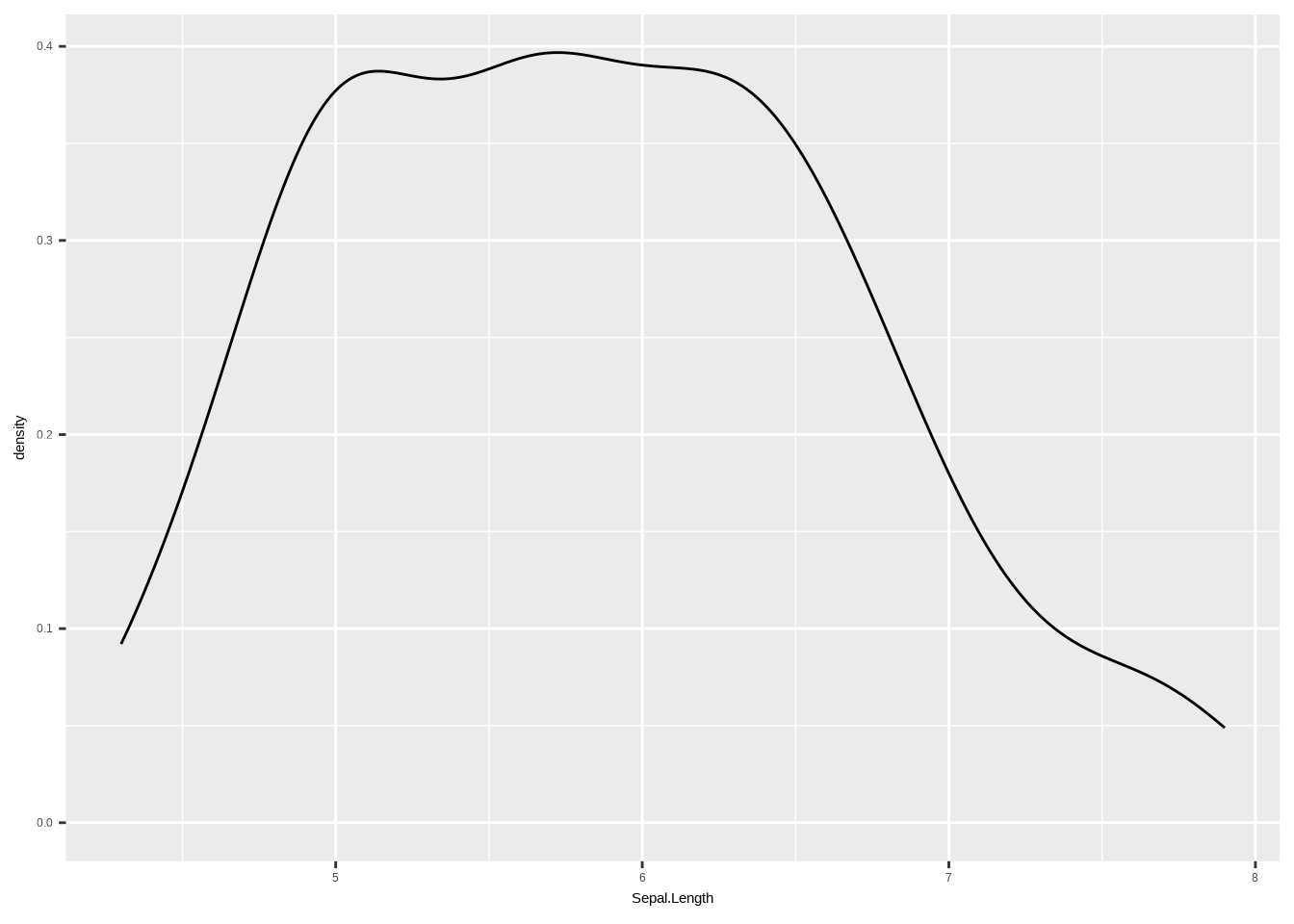
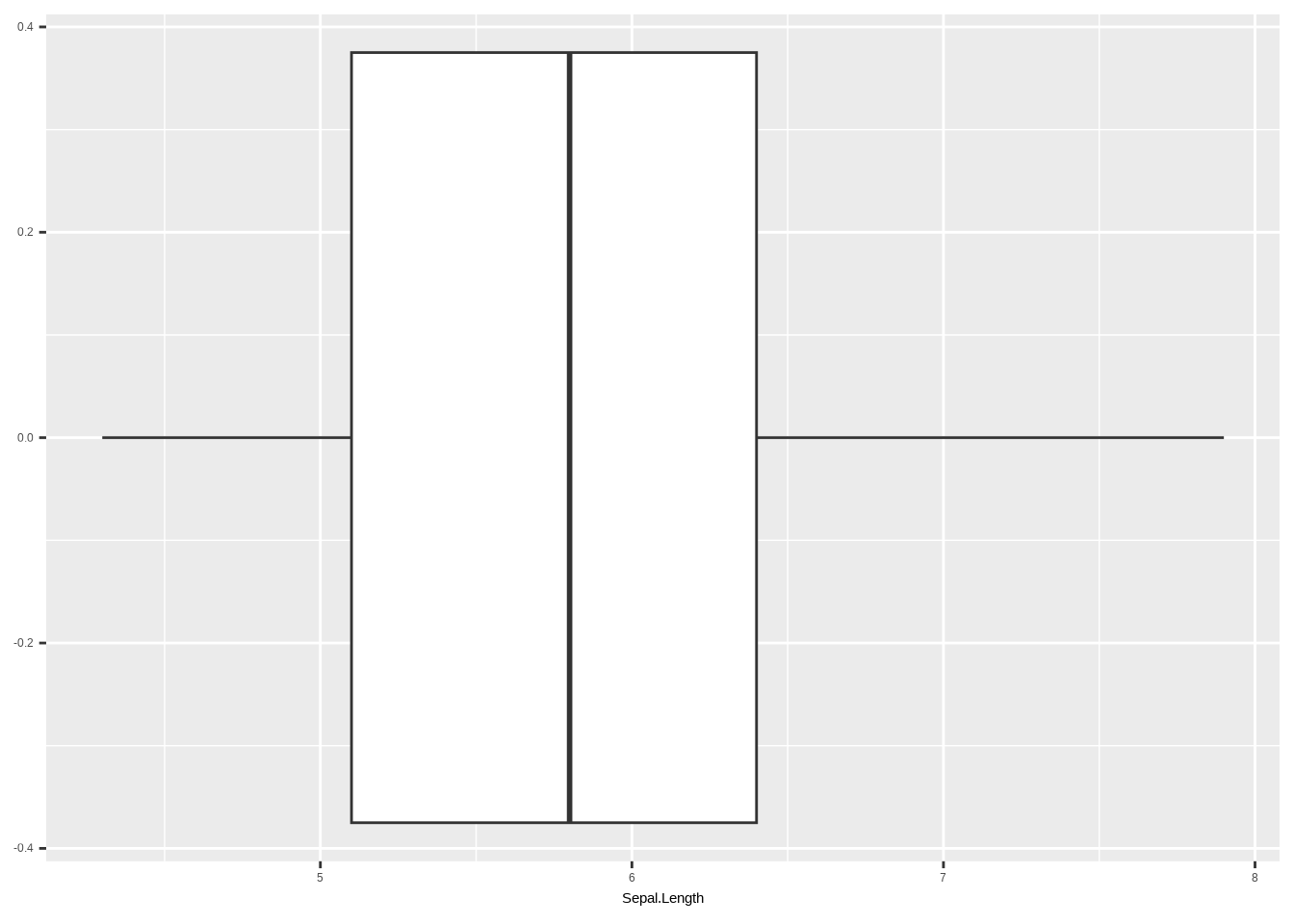
### EDIT: Man kann auch alles in einem Schritt erledigen, wie unten gezeigt
# Histogramm
# iris %>%
# filter(Species == "setosa") %>%
# ggplot(aes(x = Sepal.Length)) +
# geom_histogram()
# Dichtekurve
# iris %>%
# filter(Species == "setosa") %>%
# ggplot(aes(x = Sepal.Length)) +
# geom_density()
# Boxplot
# iris %>%
# filter(Species == "setosa") %>%
# ggplot(aes(x = Sepal.Length)) +
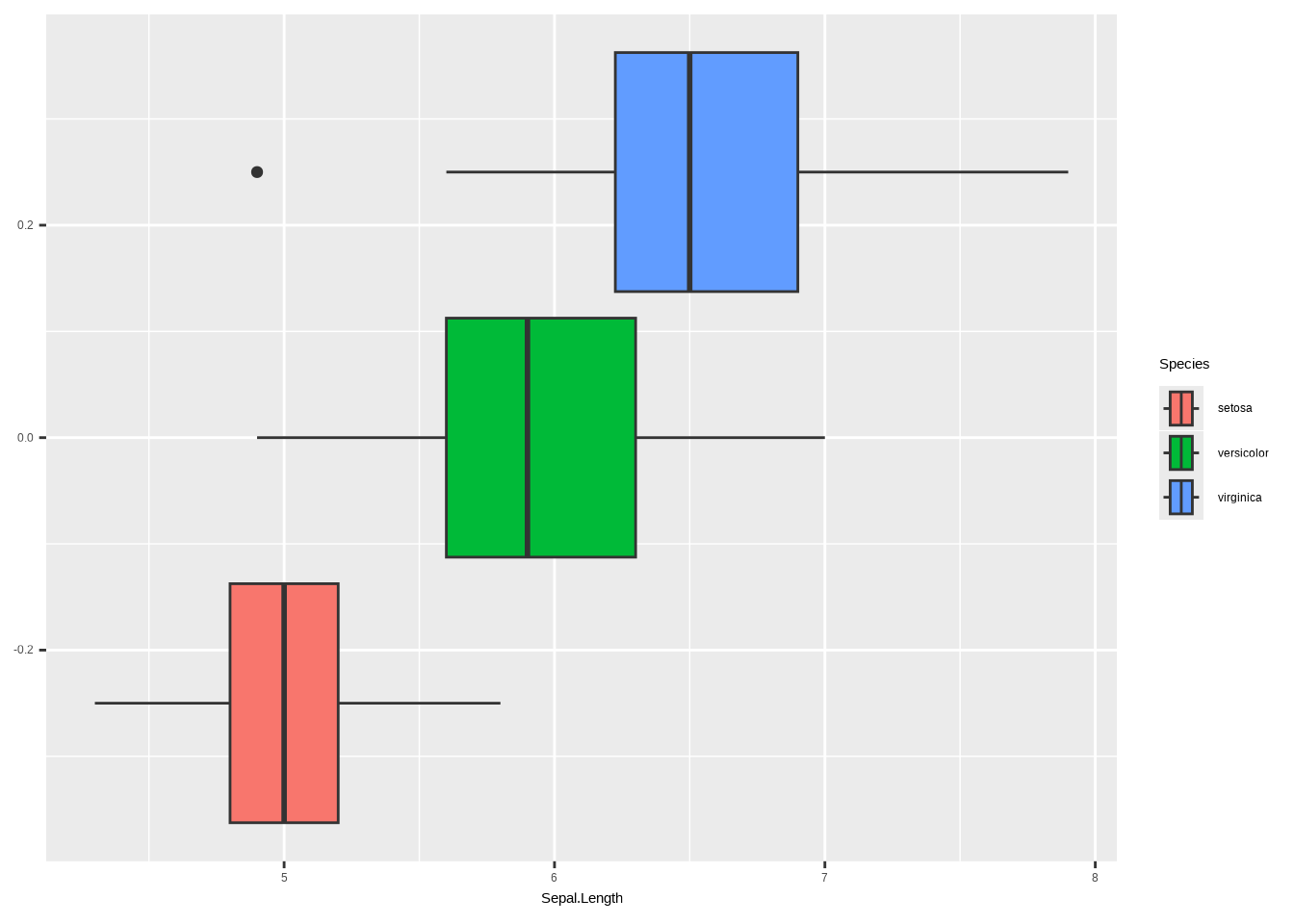
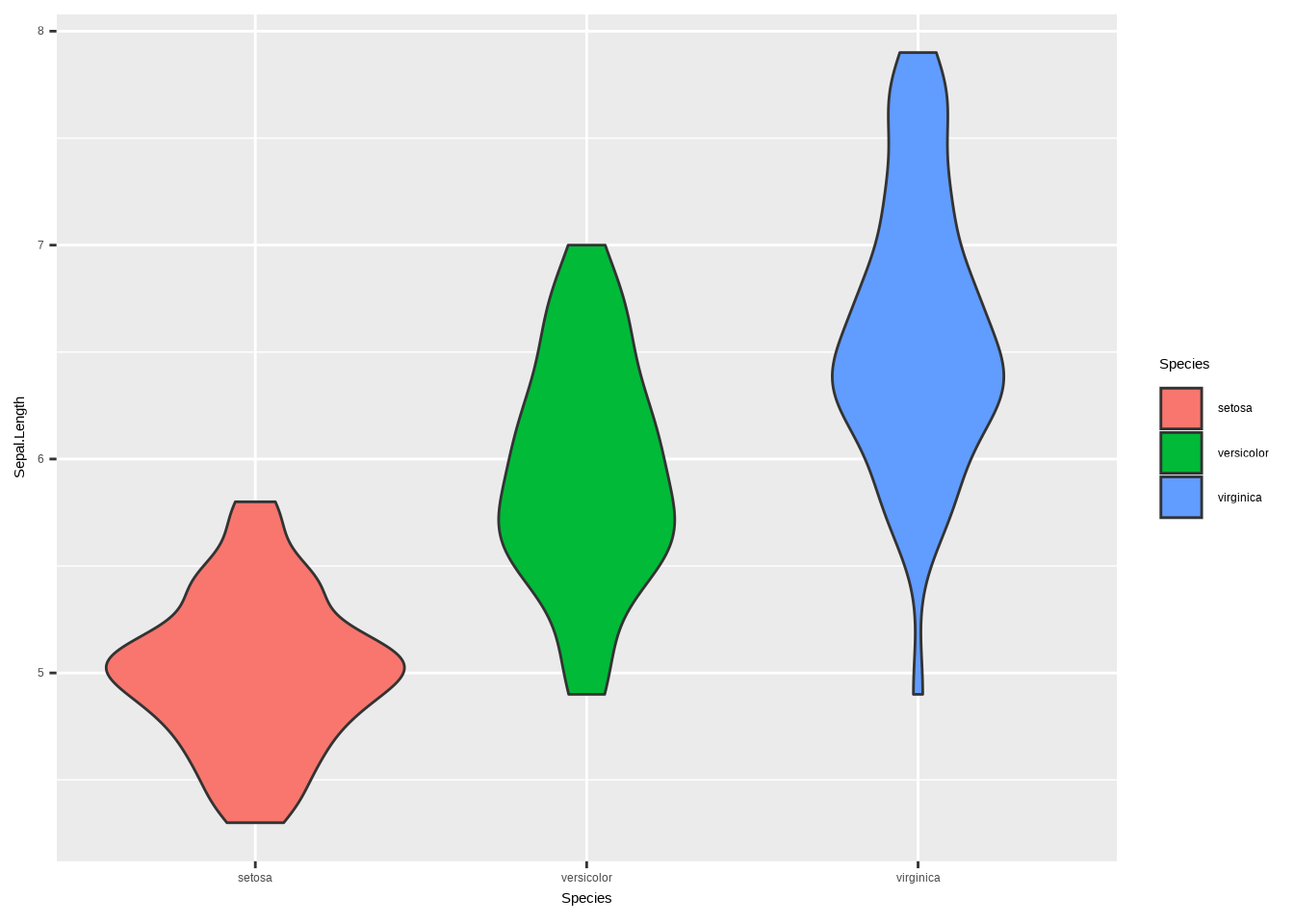
# geom_boxplot()b. Füge nun die beiden anderen Arten zum Plot hinzu. Stelle sicher, dass jede Art eine eindeutige Farbe hat.
## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.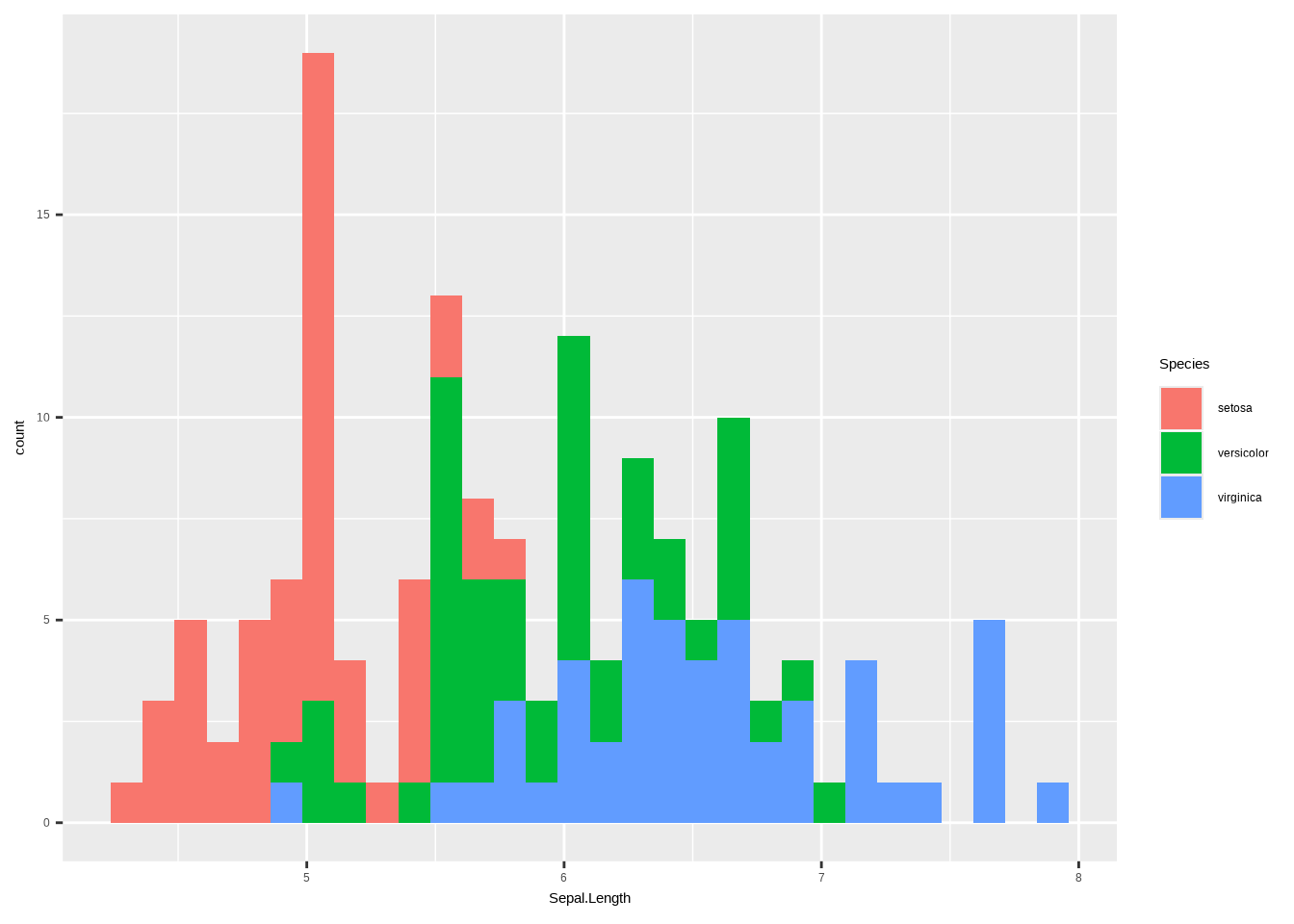
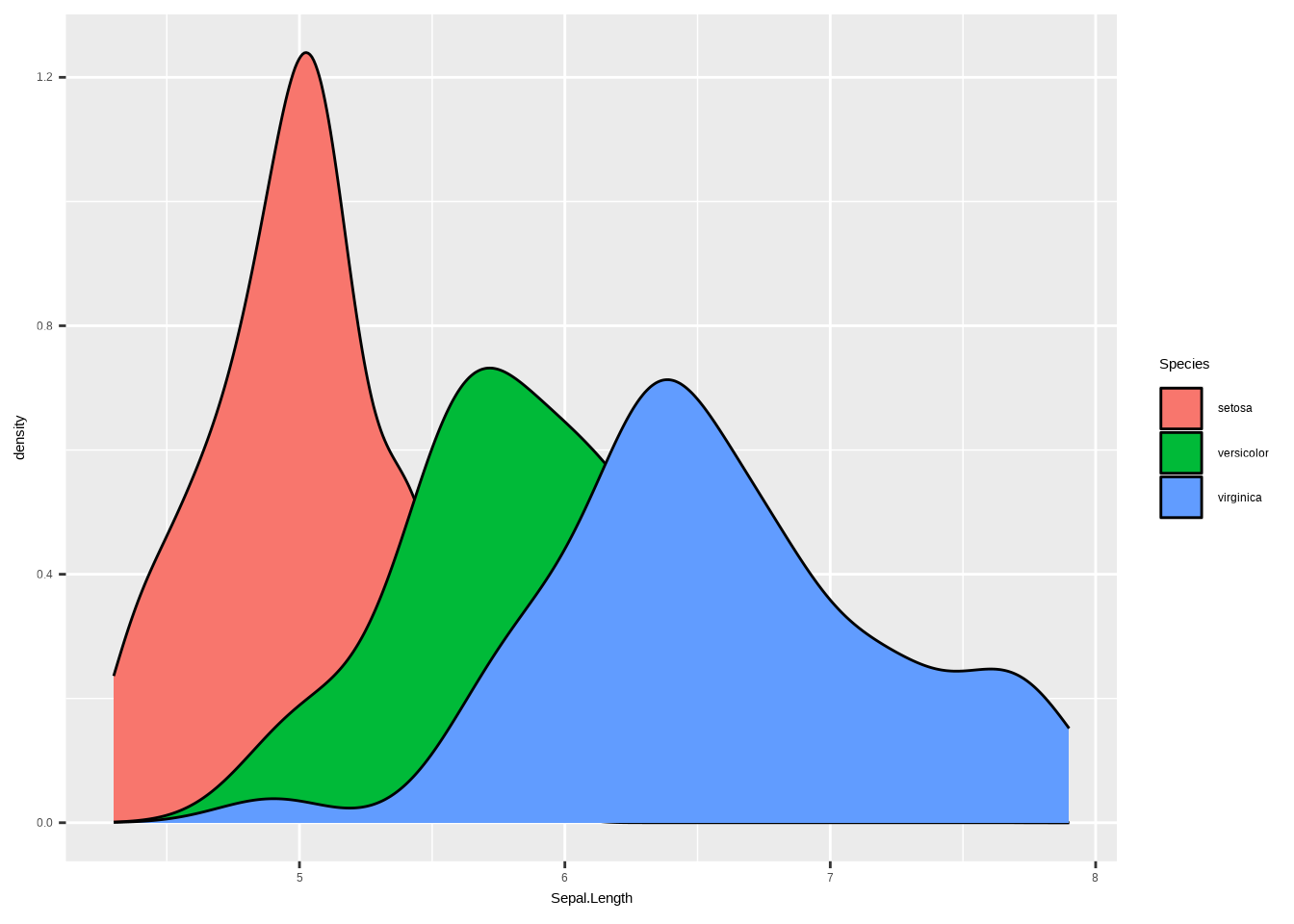
# Ridgeline Plot
ggplot(iris, aes(x = Sepal.Length, y = Species, fill = Species)) +
geom_density_ridges()## Picking joint bandwidth of 0.181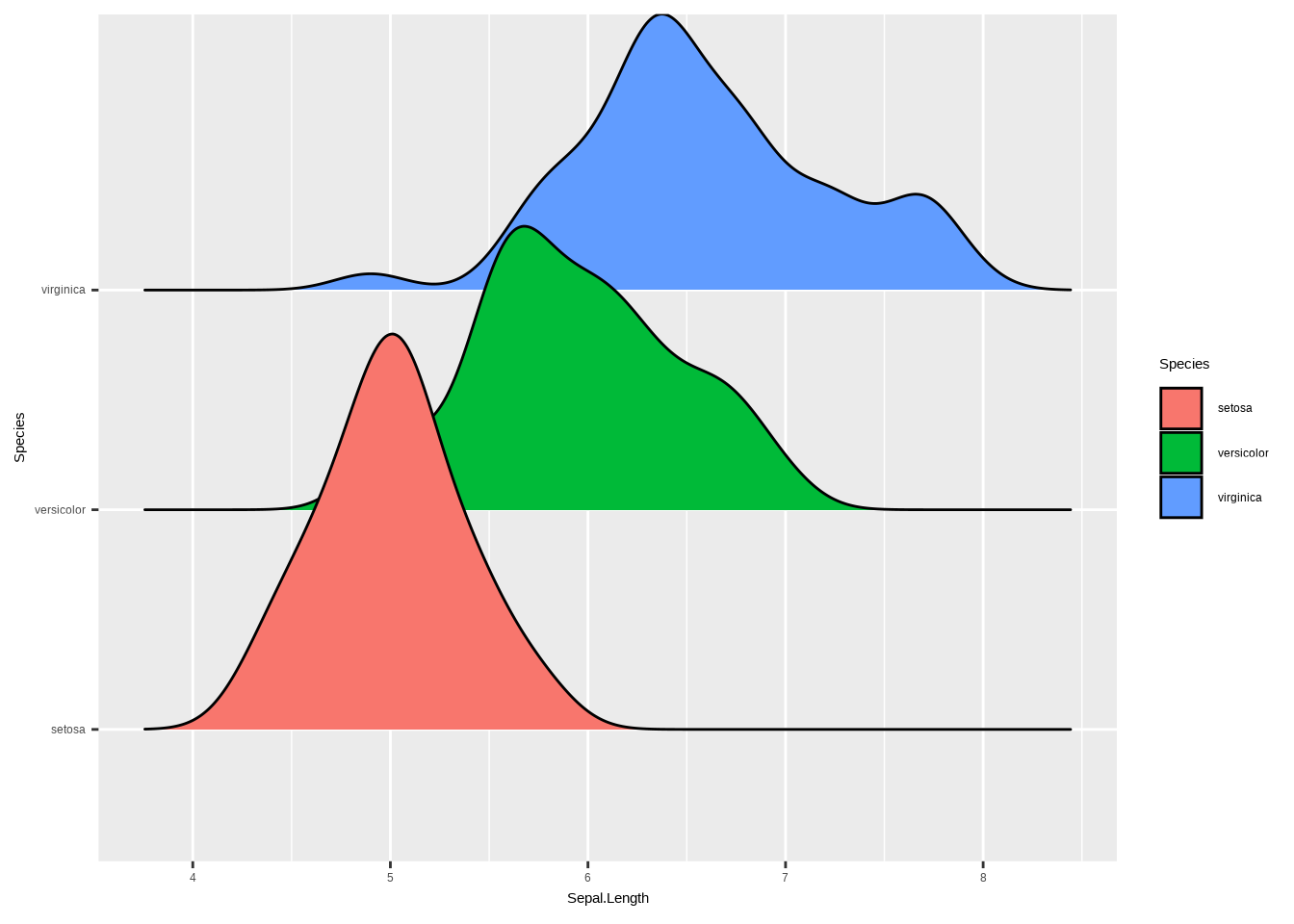
c. Erstelle einen ansprechenden Plot! Gib dem Plot einen aussagekräftigen Titel sowie aussagekräftige Beschriftungen für die x- und y-Achse und experimentiere mit den Farben.
# Histogramm
ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_histogram() +
labs(
x = "Art",
y = "Kelchblattlänge",
title = "Verteilung der Kelchblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Dark2")## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.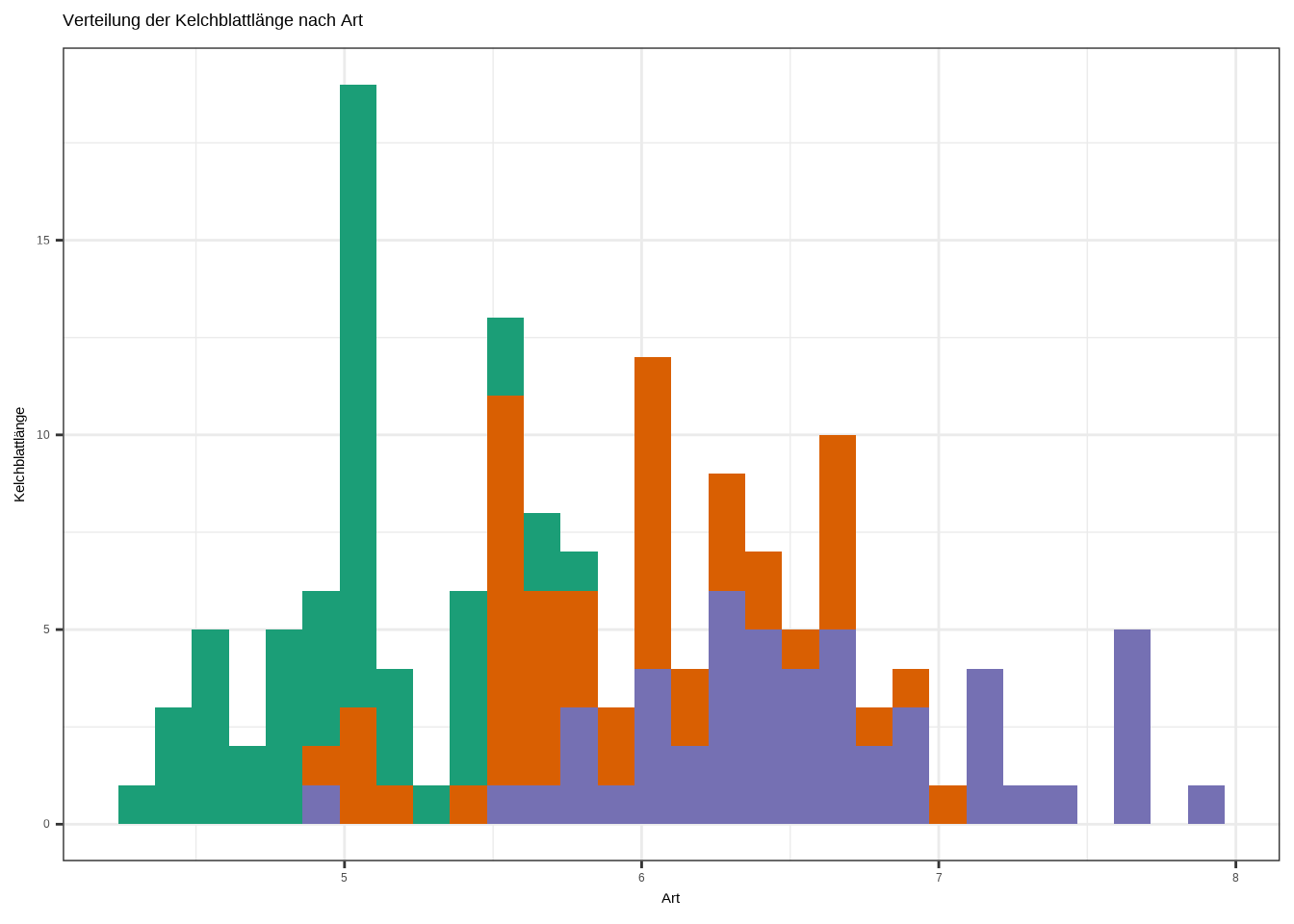
# Dichtekurve
ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_density() +
labs(
x = "Art",
y = "Kelchblattlänge",
title = "Verteilung der Kelchblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Dark2")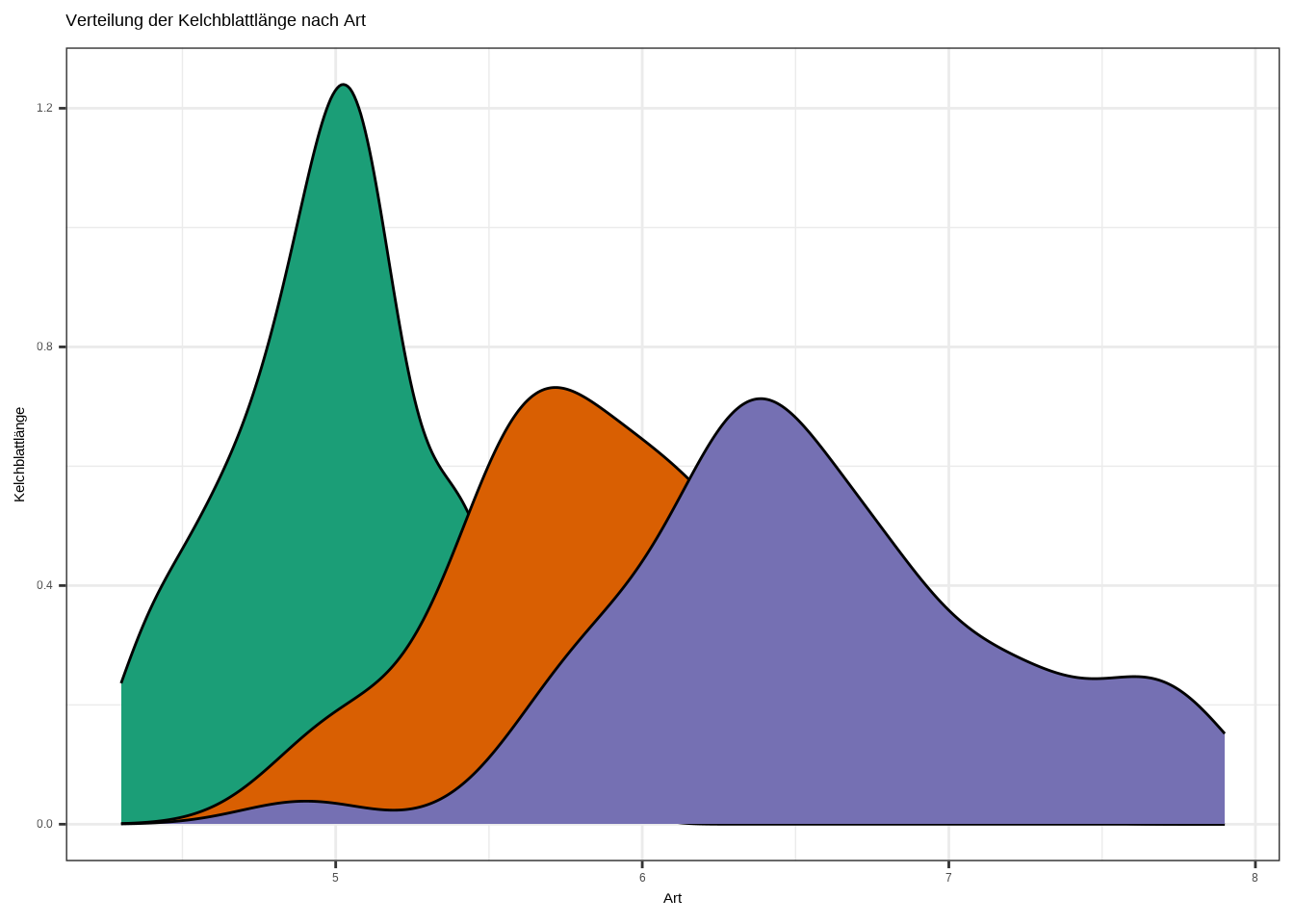
# Boxplot
ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_boxplot() +
labs(
x = "Art",
y = "Kelchblattlänge",
title = "Verteilung der Kelchblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Dark2")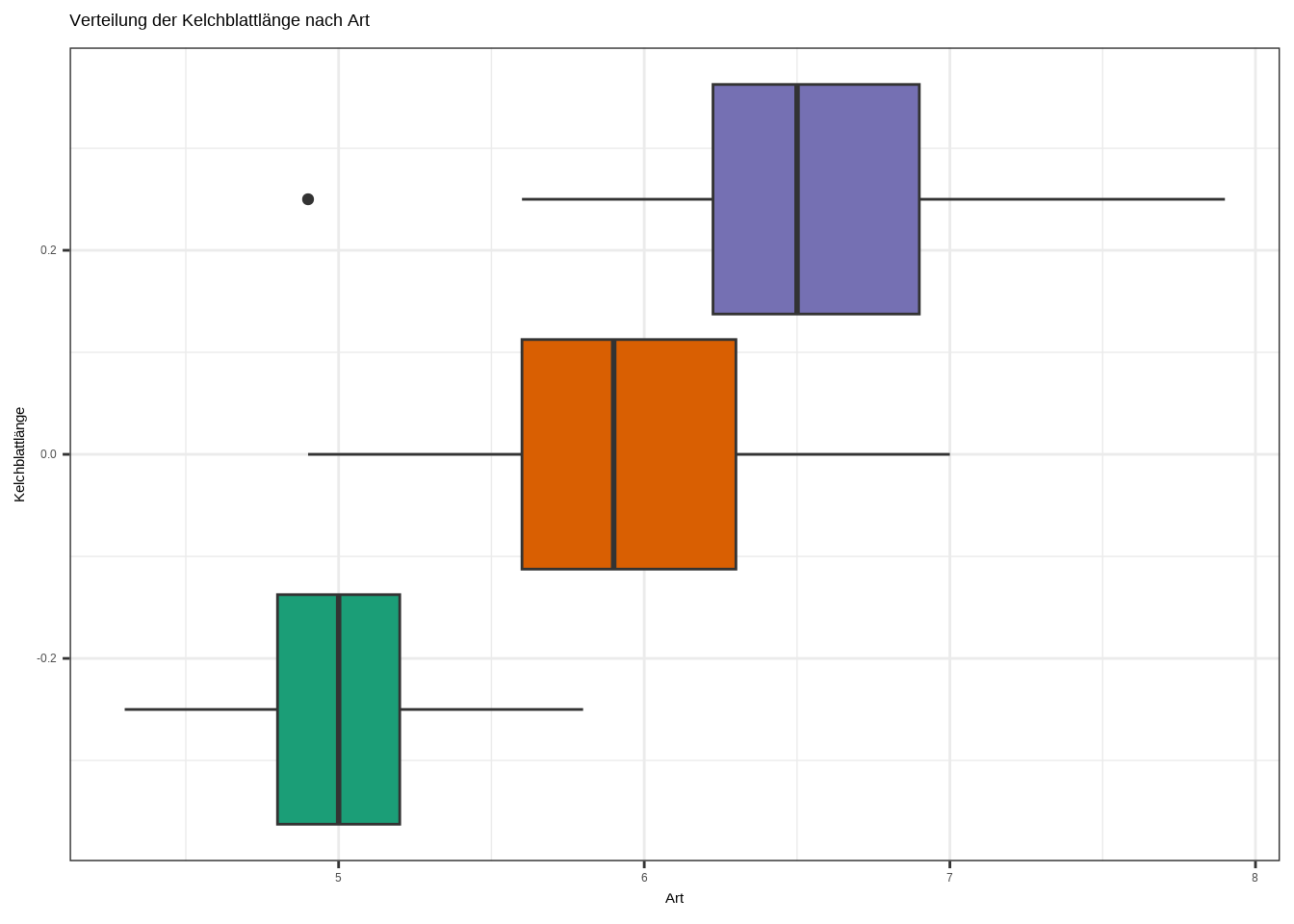
# Violin Plot
ggplot(iris, aes(x = Species, y = Sepal.Length, fill = Species)) +
geom_violin() +
labs(
x = "Art",
y = "Kelchblattlänge",
title = "Verteilung der Kelchblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Dark2")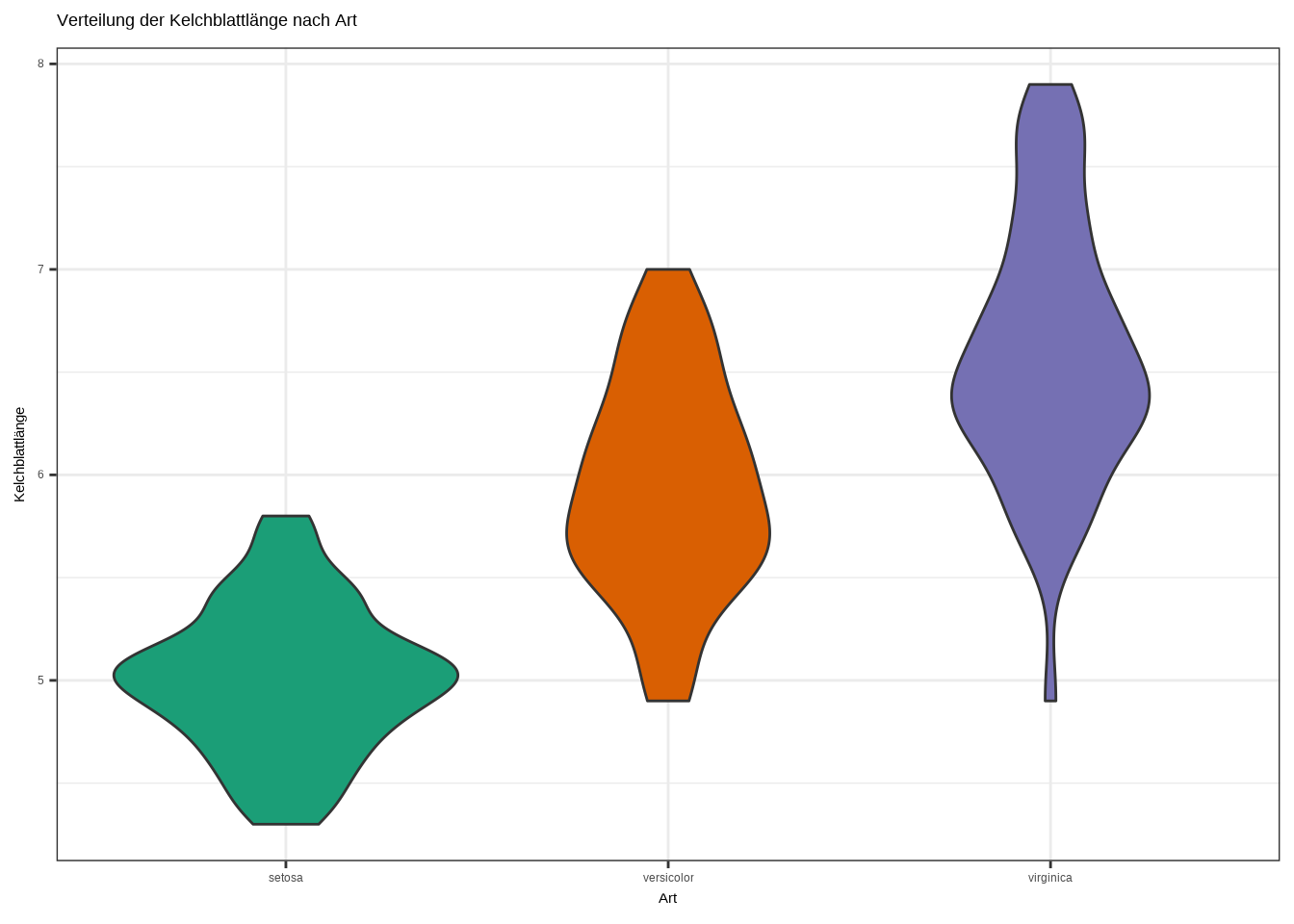
# Ridgeline Plot
ggplot(iris, aes(x = Sepal.Length, y = Species, fill = Species)) +
geom_density_ridges() +
labs(
x = "Kelchblattlänge",
y = "Art",
title = "Verteilung der Kelchblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Dark2")## Picking joint bandwidth of 0.181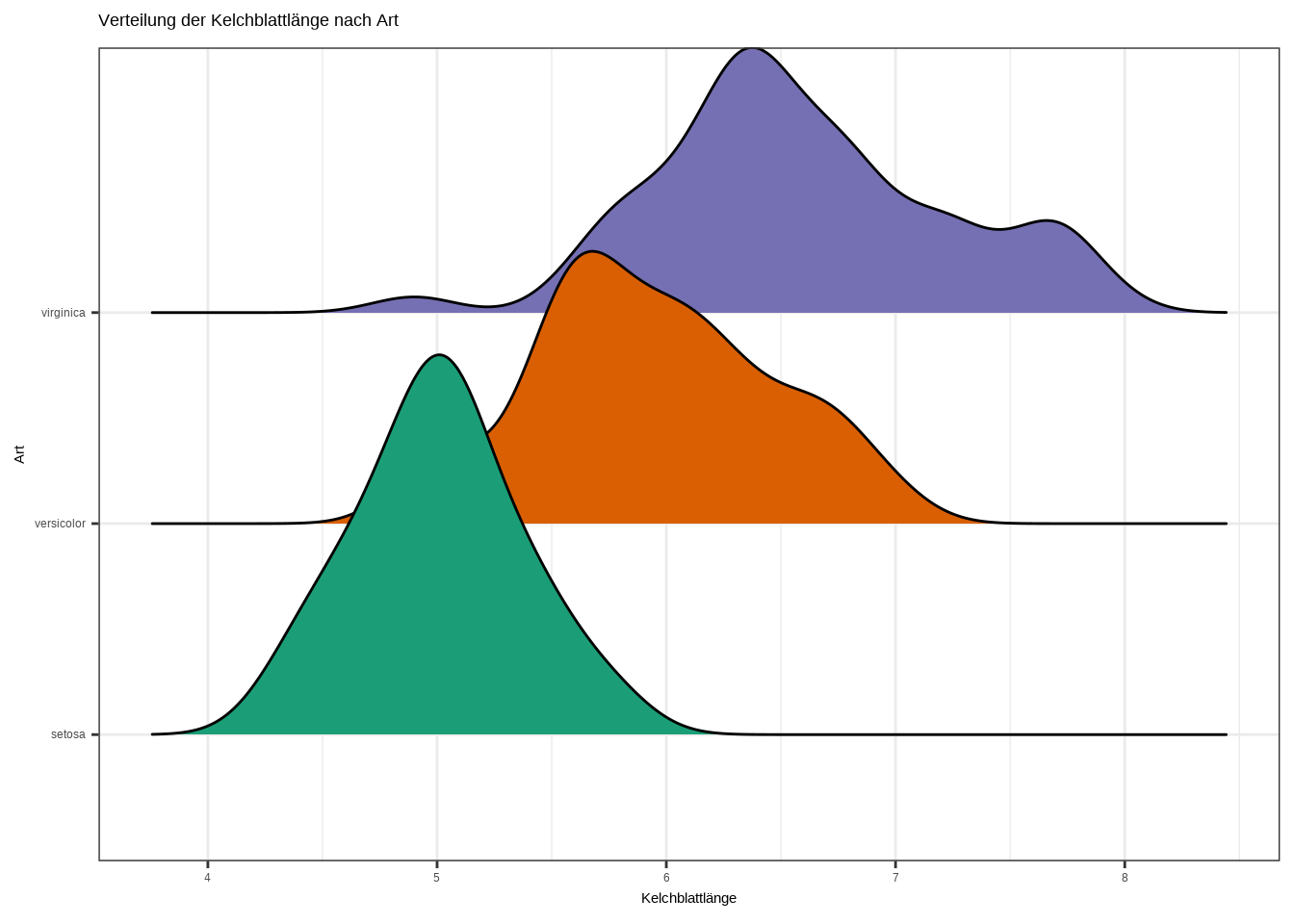
d. Interpretiere den Plot!
8.3.2 Übung 2: Rangfolgen
a. Berechne die durchschnittliche Petal.Length und stelle sie für jede Art in einem ansprechenden Barplot dar. Hinweis: Die Daten müssen wieder zuerst aufbereitet werden. Entscheide selbst, ob du den Plot vertikal oder horizontal gestalten möchtest.
# Daten aufbereiten
d1 <- iris %>%
group_by(Species) %>%
dplyr::summarize(PL_average = mean(Petal.Length))
# Überprüfen
head(d1) ## # A tibble: 3 × 2
## Species PL_average
## <fct> <dbl>
## 1 setosa 1.46
## 2 versicolor 4.26
## 3 virginica 5.55# Horizontaler Barplot
ggplot(d1, aes(x = Species, y = PL_average, fill = Species)) +
geom_bar(stat = "identity")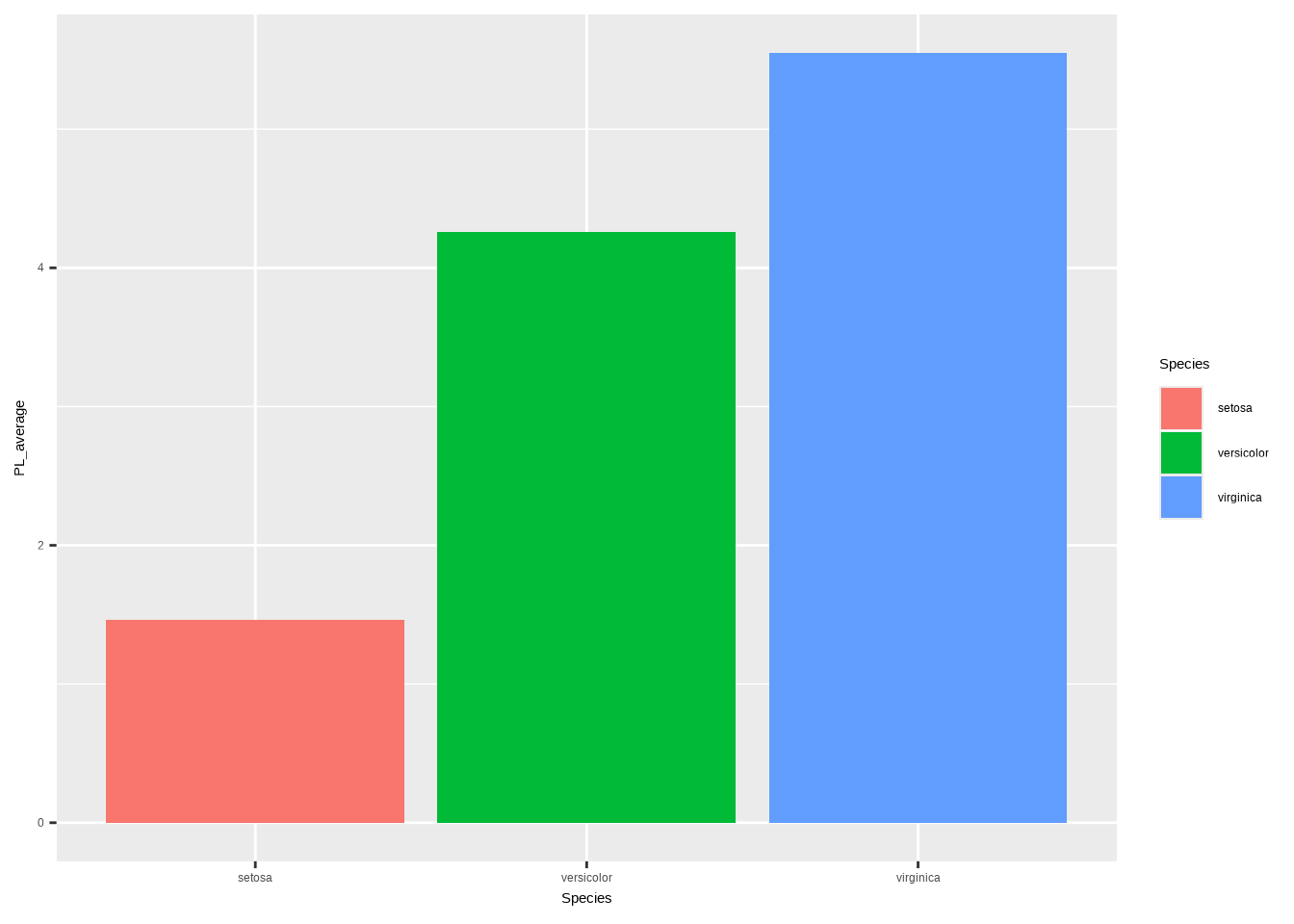
# Vertikaler Barplot
ggplot(d1, aes(x = PL_average, y = Species, fill = Species)) +
geom_bar(stat = "identity") 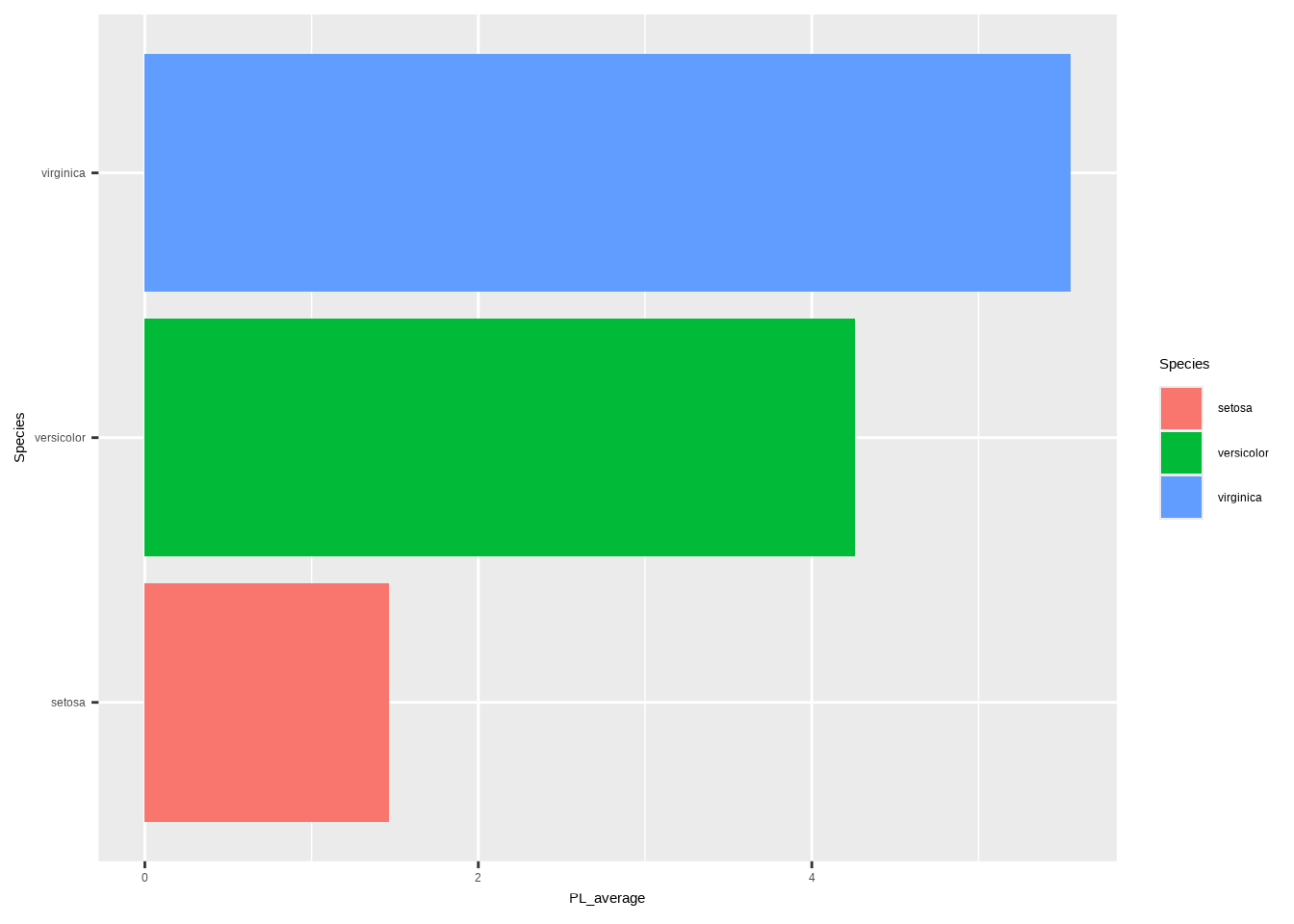
b. Erstelle einen ansprechenden Plot! Gib dem Plot einen aussagekräftigen Titel sowie aussagekräftige Beschriftungen für die x- und y-Achse und experimentiere mit den Farben.
# Horizontaler Barplot
ggplot(d1, aes(x = Species, y = PL_average, fill = Species)) +
geom_bar(stat = "identity") +
labs(
x = "Art",
y = "Durchschnittliche Blütenblattlänge",
title = "Durchschnittliche Blütenblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Set1")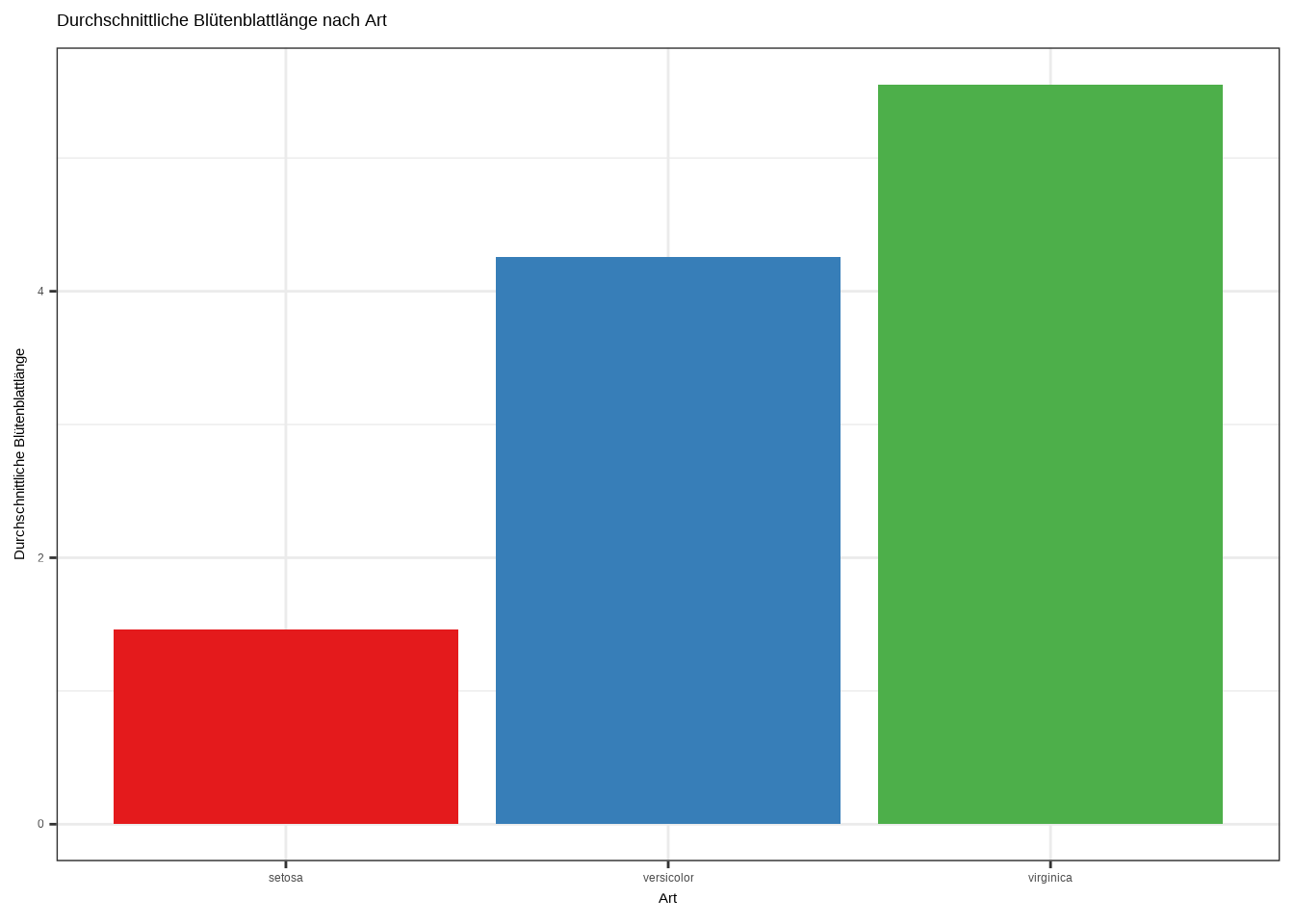
# Vertikaler Barplot
ggplot(d1, aes(x = PL_average, y = Species, fill = Species)) +
geom_bar(stat = "identity") +
labs(
x = "Durchschnittliche Blütenblattlänge",
y = "Art",
title = "Durchschnittliche Blütenblattlänge nach Art"
) +
theme_bw() +
theme(legend.position = "none") +
scale_fill_brewer(palette = "Accent")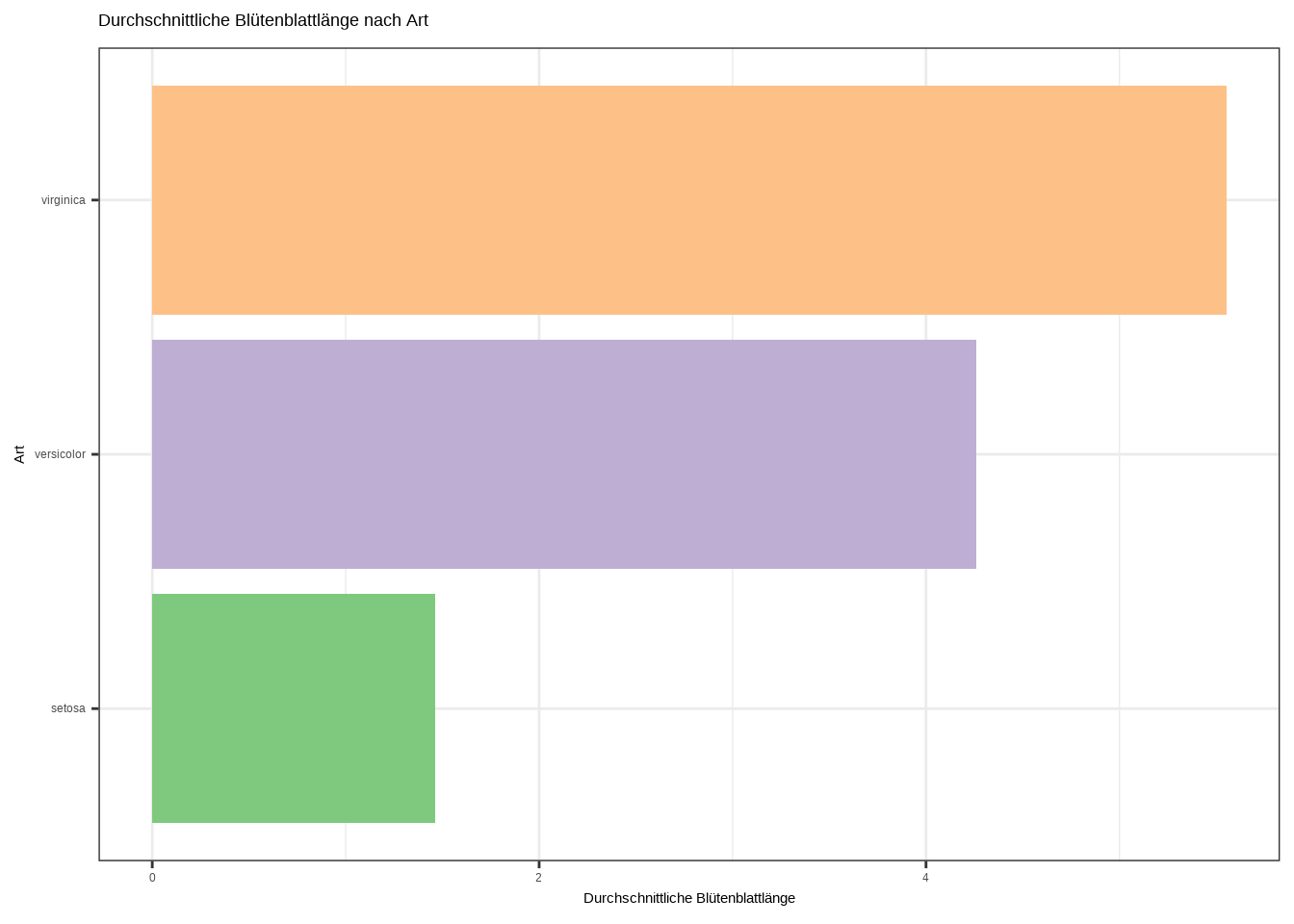
8.3.3 Übung 3: Korrelation
a. Erstelle ein Streudiagramm mit Sepal.Length auf der x-Achse und Sepal.Width auf der y-Achse – für die Art virginica.
# Daten aufbereiten
d1 <- iris %>%
filter(Species == "virginica")
# Plot erstellen
ggplot(d1, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point()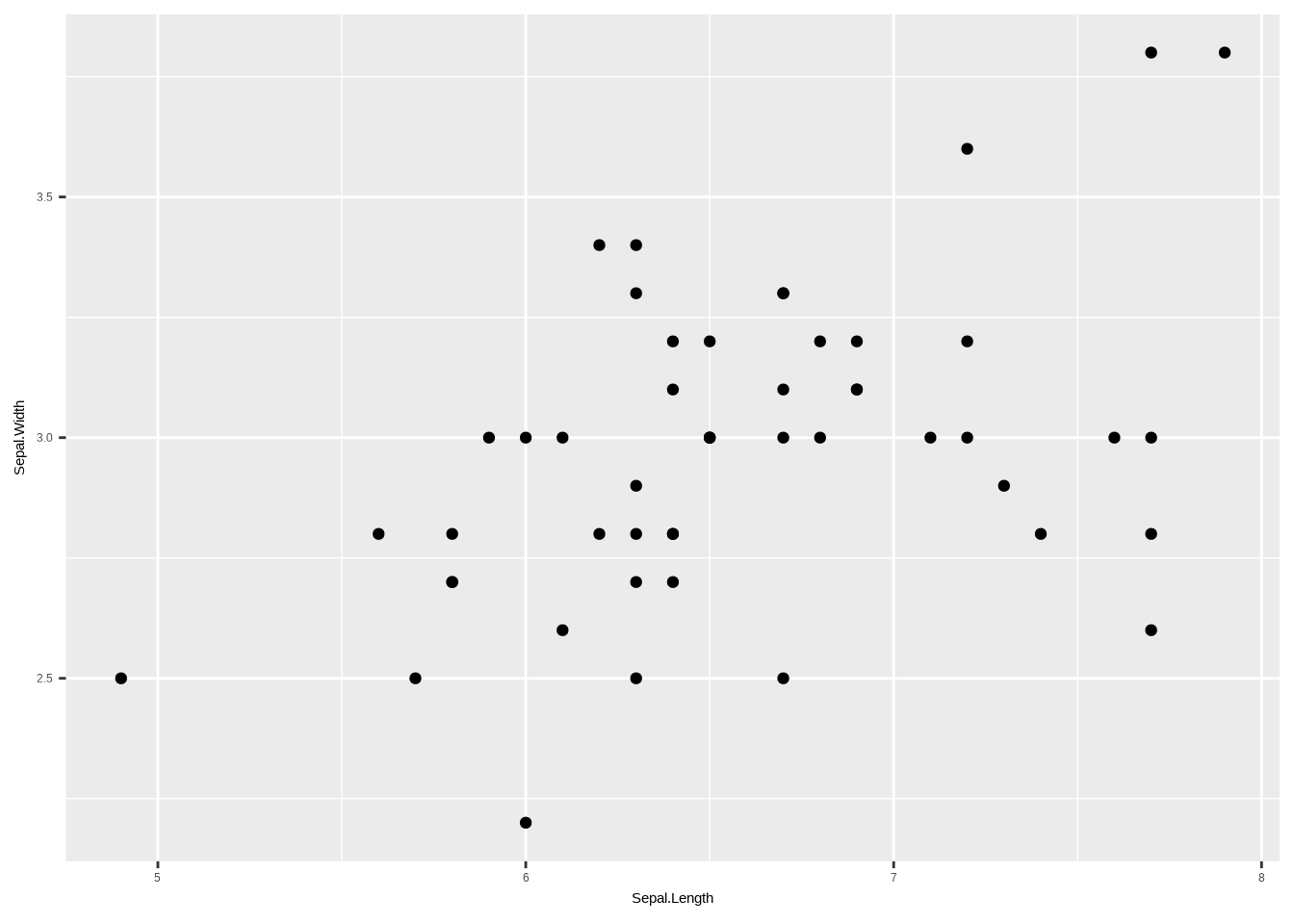
b. Füge nun die Art versicolor zum Plot hinzu. Die Punkte dieser Art sollen eine andere Farbe UND eine andere Form haben.
# Daten aufbereiten
d1 <- iris %>%
filter(Species %in% c("virginica", "versicolor"))
# Plot erstellen
ggplot(d1, aes(x = Sepal.Length, y = Sepal.Width,
shape = Species, color = Species)) +
geom_point() 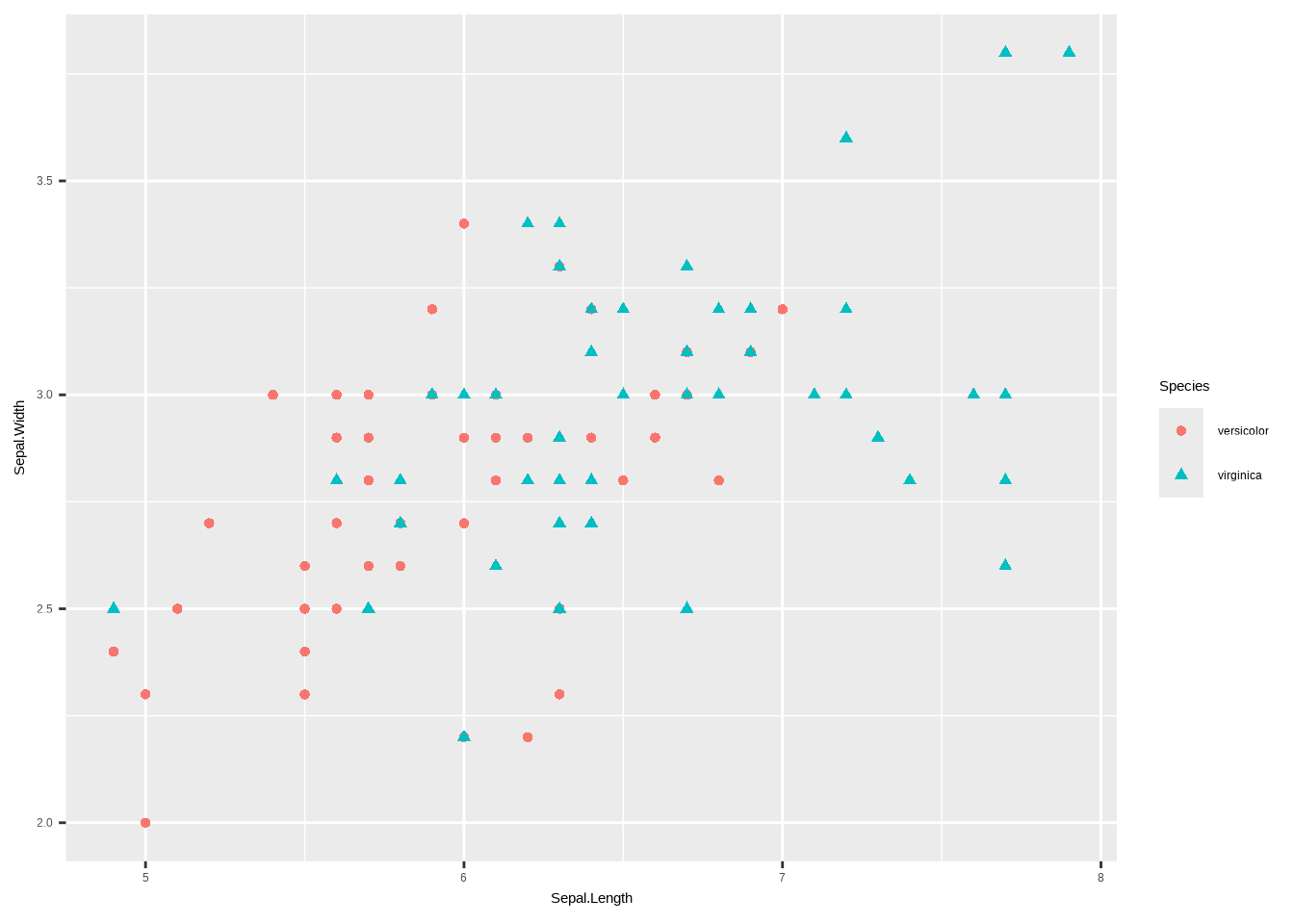
c. Erstelle einen ansprechenden Plot! Füge ein Theme, Beschriftungen und einen Titel hinzu, erhöhe die Größe der Formen und experimentiere mit den Farben.
# Plot erstellen
ggplot(d1, aes(x = Sepal.Length, y = Sepal.Width,
shape = Species, color = Species)) +
geom_point() +
labs(
title = "Zusammenhang zwischen Kelchblattlänge und Kelchblattbreite",
x = "Kelchblattlänge",
y = "Kelchblattbreite"
) +
scale_color_brewer(palette = "Set1") +
theme_classic()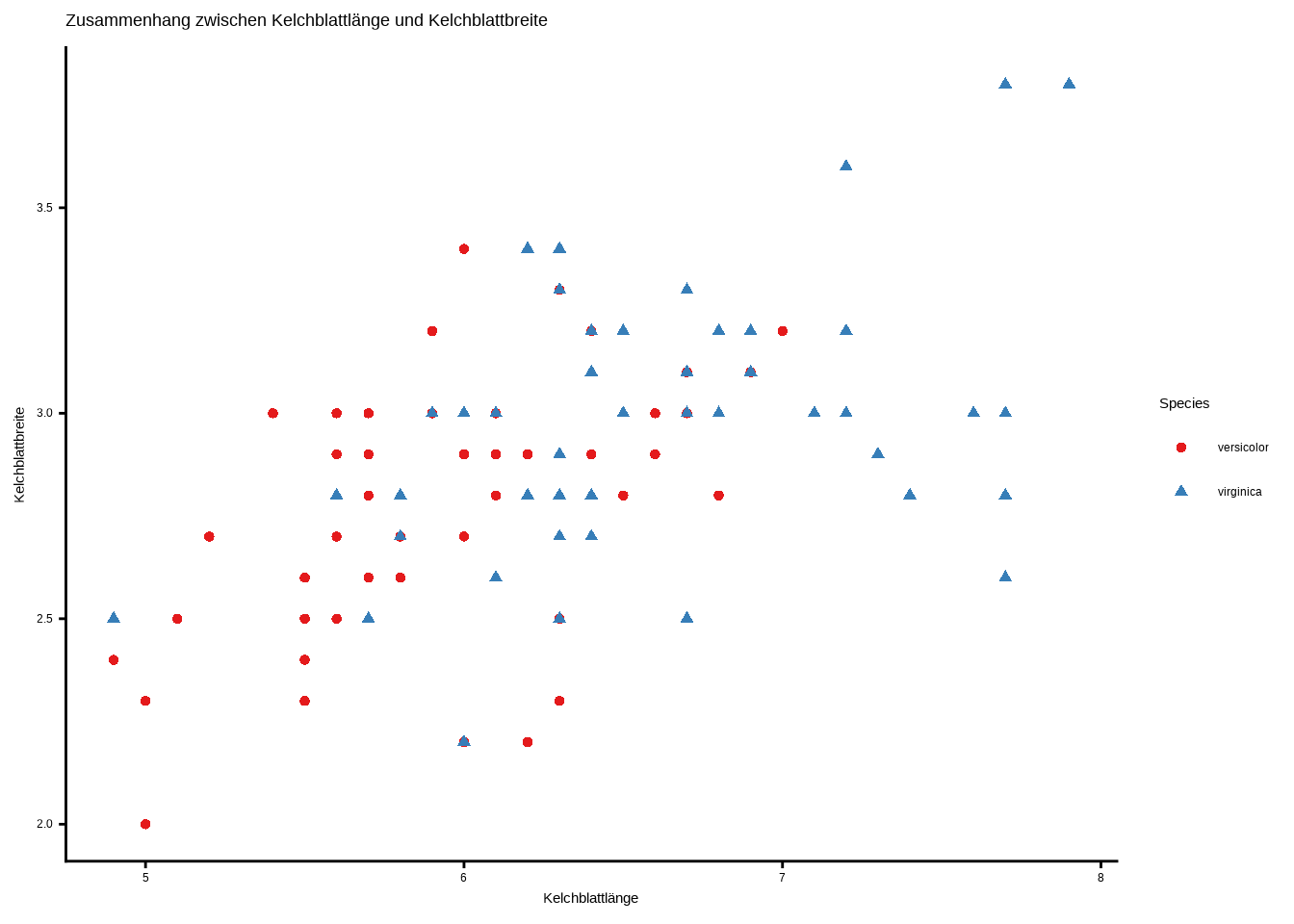
8.4 Kapitel 4: Explorative Datenanalyse
8.4.1 Übung 1: Deskriptivstatistik
In dieser Übung arbeiten wir mit dem eingebauten iris-Datensatz in R:
a. Berechne den Modus, den Mittelwert und den Median für die Variable iris$Sepal.Length.
## [1] 5.843333## [1] 5.8# Modus berechnen
uniq_vals <- unique(iris$Sepal.Length)
freqs <- tabulate(iris$Sepal.Length)
uniq_vals[which.max(freqs)]## [1] 5# Man könnte auch eine Funktion für den Modus definieren:
# mode <- function(x) {
# uniq_vals <- unique(x, na.rm = TRUE)
# freqs <- tabulate(match(x, uniq_vals))
# uniq_vals[which.max(freqs)]
# }
# mode(iris$Sepal.Length)b. Berechne den Interquartilsabstand, die Varianz und die Standardabweichung für iris$Sepal.Length.
## [1] 1.3## [1] 0.6856935## [1] 0.8280661c. Berechne alle fünf Maße auf einmal mit einer geeigneten Funktion (wähle selbst, welche du verwenden möchtest).
## vars n mean sd median trimmed mad min max range skew
## X1 1 150 5.84 0.83 5.8 5.81 1.04 4.3 7.9 3.6 0.31
## kurtosis se
## X1 -0.61 0.07| Name | iris$Sepal.Length |
| Number of rows | 150 |
| Number of columns | 1 |
| _______________________ | |
| Column type frequency: | |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| data | 0 | 1 | 5.84 | 0.83 | 4.3 | 5.1 | 5.8 | 6.4 | 7.9 | ▆▇▇▅▂ |
## Descriptive Statistics
## iris$Sepal.Length
## N: 150
##
## Sepal.Length
## ----------------- --------------
## Mean 5.84
## Std.Dev 0.83
## Min 4.30
## Q1 5.10
## Median 5.80
## Q3 6.40
## Max 7.90
## MAD 1.04
## IQR 1.30
## CV 0.14
## Skewness 0.31
## SE.Skewness 0.20
## Kurtosis -0.61
## N.Valid 150.00
## N 150.00
## Pct.Valid 100.008.4.2 Übung 2: Kreuztabellen und Korrelationen
a. Erstelle eine Kreuztabelle für esoph$agegp und esoph$alcgp.
##
## 0-39g/day 40-79 80-119 120+
## 25-34 4 4 3 4
## 35-44 4 4 4 3
## 45-54 4 4 4 4
## 55-64 4 4 4 4
## 65-74 4 3 4 4
## 75+ 3 4 2 2## Cross-Tabulation, Row Proportions
## agegp * alcgp
## Data Frame: esoph
##
## ------- ------- ------------ ------------ ------------ ------------ -------------
## alcgp 0-39g/day 40-79 80-119 120+ Total
## agegp
## 25-34 4 (26.7%) 4 (26.7%) 3 (20.0%) 4 (26.7%) 15 (100.0%)
## 35-44 4 (26.7%) 4 (26.7%) 4 (26.7%) 3 (20.0%) 15 (100.0%)
## 45-54 4 (25.0%) 4 (25.0%) 4 (25.0%) 4 (25.0%) 16 (100.0%)
## 55-64 4 (25.0%) 4 (25.0%) 4 (25.0%) 4 (25.0%) 16 (100.0%)
## 65-74 4 (26.7%) 3 (20.0%) 4 (26.7%) 4 (26.7%) 15 (100.0%)
## 75+ 3 (27.3%) 4 (36.4%) 2 (18.2%) 2 (18.2%) 11 (100.0%)
## Total 23 (26.1%) 23 (26.1%) 21 (23.9%) 21 (23.9%) 88 (100.0%)
## ------- ------- ------------ ------------ ------------ ------------ -------------|
alcgp
|
Total | ||||
|---|---|---|---|---|---|
| 0-39g/day | 40-79 | 80-119 | 120+ | ||
| agegp | |||||
| 25-34 | 4 | 4 | 3 | 4 | 15 |
| 35-44 | 4 | 4 | 4 | 3 | 15 |
| 45-54 | 4 | 4 | 4 | 4 | 16 |
| 55-64 | 4 | 4 | 4 | 4 | 16 |
| 65-74 | 4 | 3 | 4 | 4 | 15 |
| 75+ | 3 | 4 | 2 | 2 | 11 |
| Total | 23 | 23 | 21 | 21 | 88 |
b. Reduziere den iris-Datensatz auf Sepal.Length, Sepal.Width, Petal.Length und Petal.Width und speichere ihn in einem Objekt namens iris_numeric.
c. Erstelle eine Korrelationsmatrix mit iris_numeric.
# Mit dem corrplot-Paket
cor_iris <- cor(iris_numeric)
corrplot::corrplot(cor_iris, method = "color")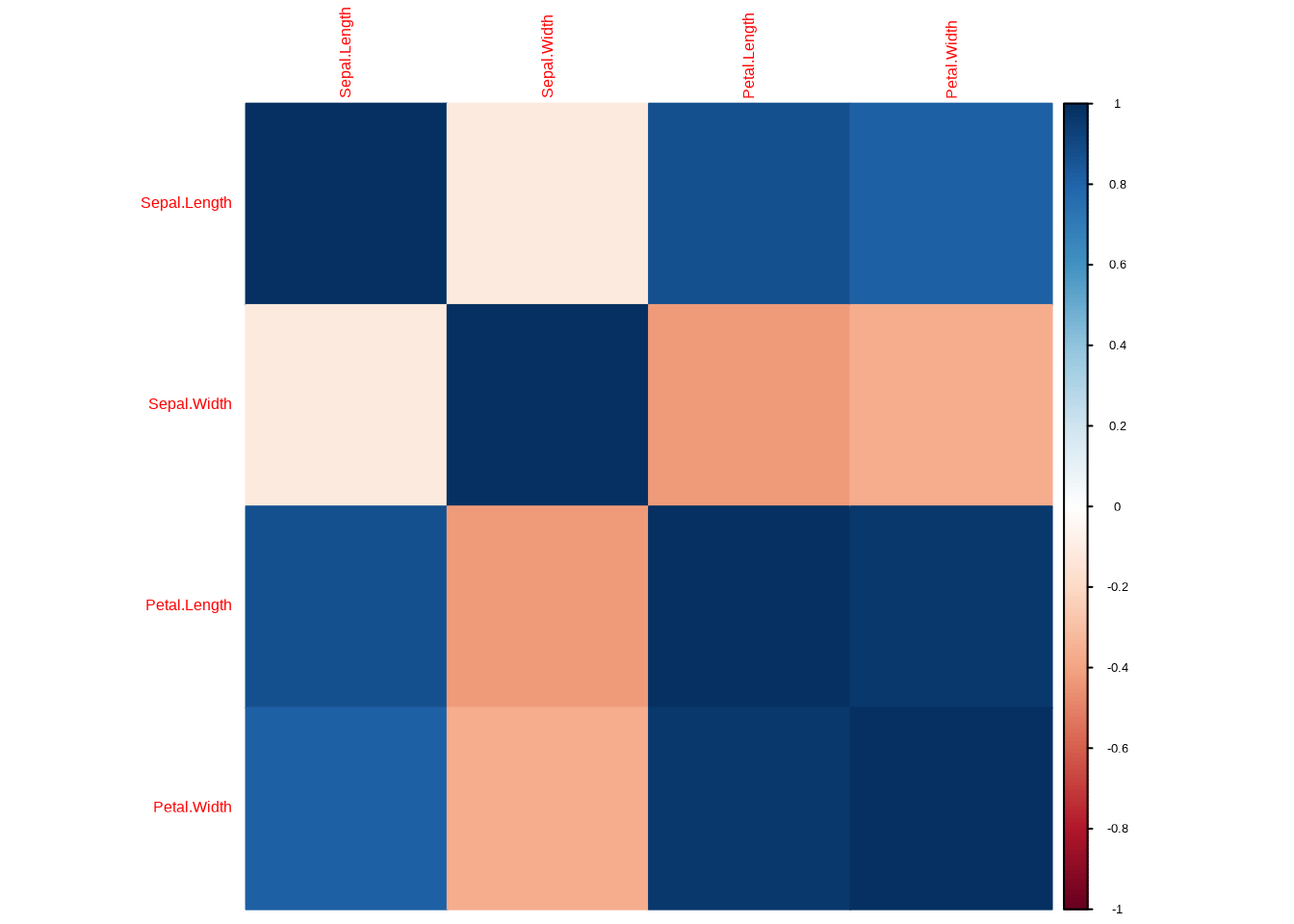
d. Verschönere die Korrelationsmatrix.
# Mit corrplot
corrplot::corrplot(cor_iris, method = "circle", type = "upper",
tl.col = "black", tl.srt = 45)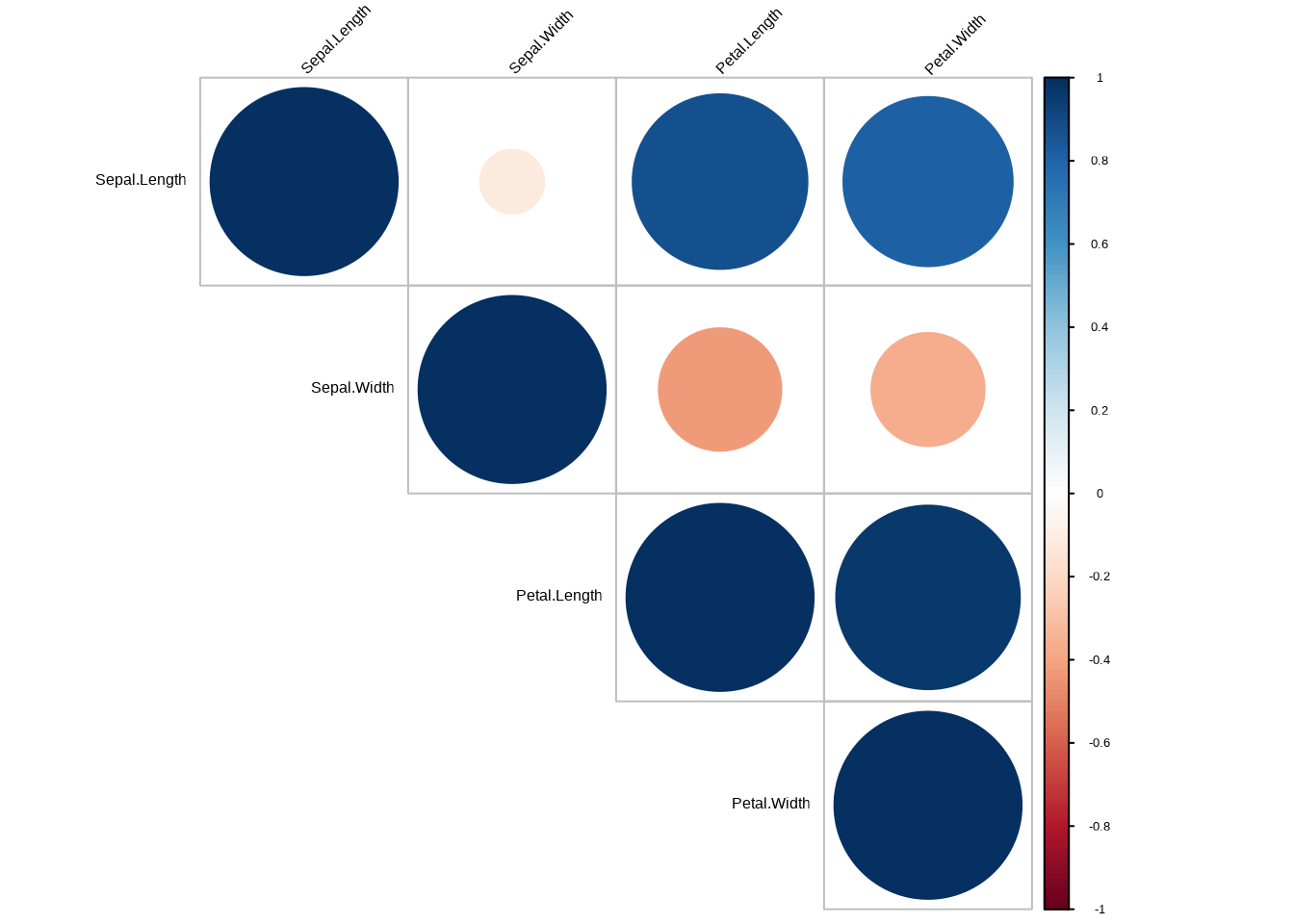
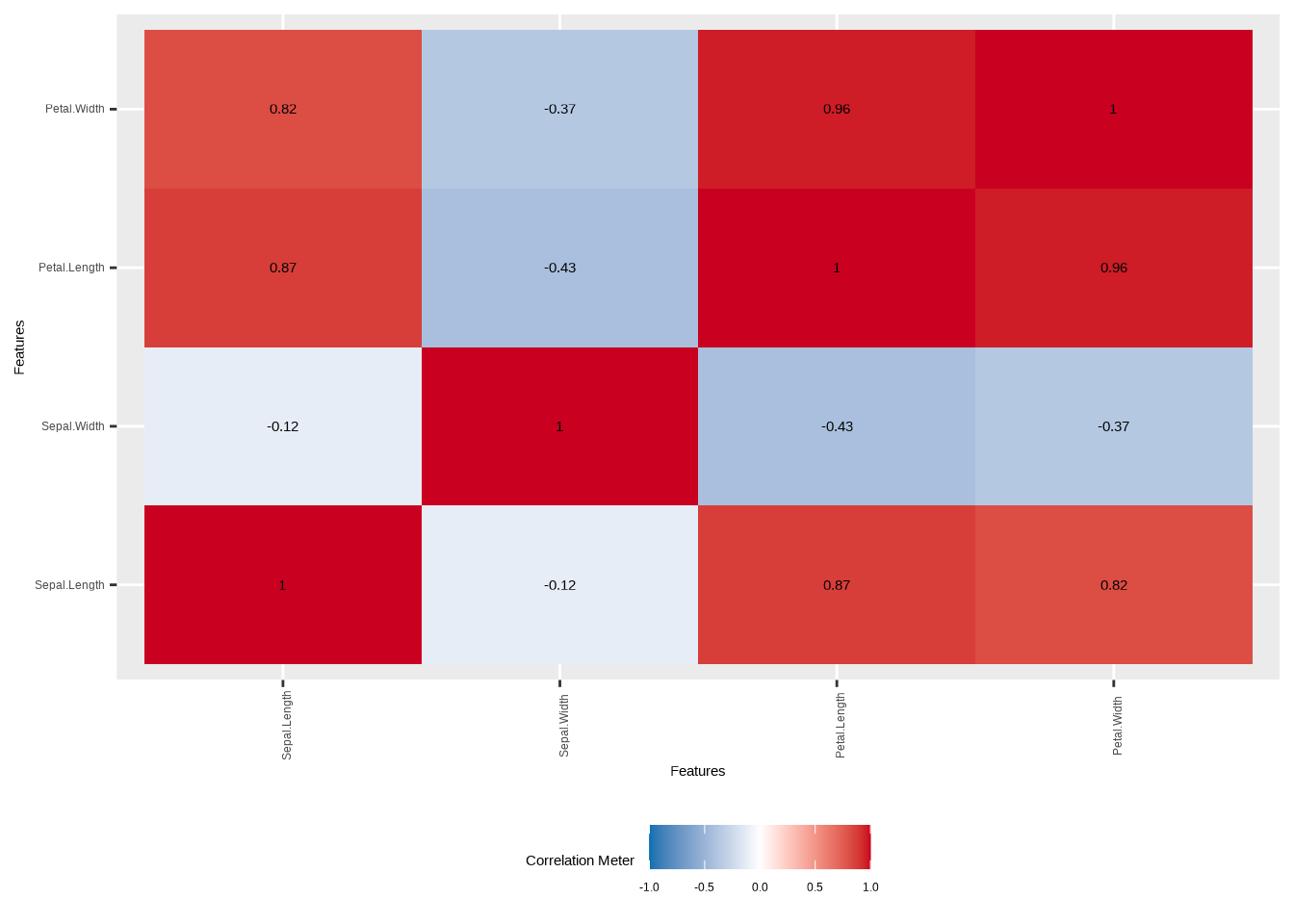
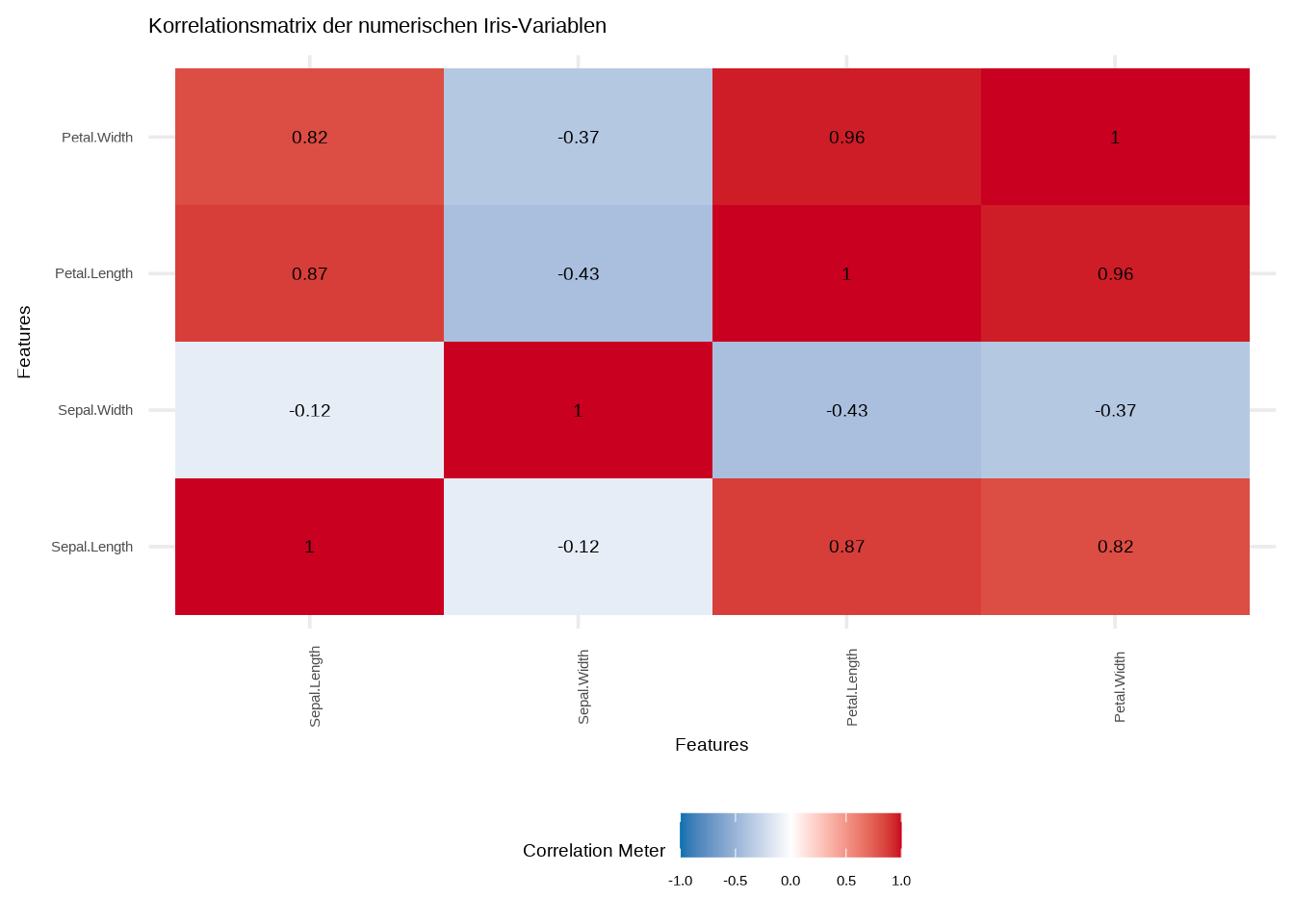
# Mit DataExplorer
DataExplorer::plot_correlation(
iris_numeric,
ggtheme = theme_minimal(base_size = 14),
title = "Korrelationsmatrix der numerischen Iris-Variablen"
)
8.4.3 Übung 3: Arbeiten mit Paketen
a. Verwende eine Funktion, um einen Überblick über den Datensatz mtcars zu erhalten.
| Name | mtcars |
| Number of rows | 32 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| mpg | 0 | 1 | 20.09 | 6.03 | 10.40 | 15.43 | 19.20 | 22.80 | 33.90 | ▃▇▅▁▂ |
| cyl | 0 | 1 | 6.19 | 1.79 | 4.00 | 4.00 | 6.00 | 8.00 | 8.00 | ▆▁▃▁▇ |
| disp | 0 | 1 | 230.72 | 123.94 | 71.10 | 120.83 | 196.30 | 326.00 | 472.00 | ▇▃▃▃▂ |
| hp | 0 | 1 | 146.69 | 68.56 | 52.00 | 96.50 | 123.00 | 180.00 | 335.00 | ▇▇▆▃▁ |
| drat | 0 | 1 | 3.60 | 0.53 | 2.76 | 3.08 | 3.70 | 3.92 | 4.93 | ▇▃▇▅▁ |
| wt | 0 | 1 | 3.22 | 0.98 | 1.51 | 2.58 | 3.33 | 3.61 | 5.42 | ▃▃▇▁▂ |
| qsec | 0 | 1 | 17.85 | 1.79 | 14.50 | 16.89 | 17.71 | 18.90 | 22.90 | ▃▇▇▂▁ |
| vs | 0 | 1 | 0.44 | 0.50 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | ▇▁▁▁▆ |
| am | 0 | 1 | 0.41 | 0.50 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | ▇▁▁▁▆ |
| gear | 0 | 1 | 3.69 | 0.74 | 3.00 | 3.00 | 4.00 | 4.00 | 5.00 | ▇▁▆▁▂ |
| carb | 0 | 1 | 2.81 | 1.62 | 1.00 | 2.00 | 2.00 | 4.00 | 8.00 | ▇▂▅▁▁ |
## Data Frame Summary
## mtcars
## Dimensions: 32 x 11
## Duplicates: 0
##
## ----------------------------------------------------------------------------------------------------------
## No Variable Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- ----------- --------------------------- -------------------- ------------------- ---------- ---------
## 1 mpg Mean (sd) : 20.1 (6) 25 distinct values : 32 0
## [numeric] min < med < max: : . (100.0%) (0.0%)
## 10.4 < 19.2 < 33.9 . : :
## IQR (CV) : 7.4 (0.3) : : : .
## : : : : :
##
## 2 cyl Mean (sd) : 6.2 (1.8) 4 : 11 (34.4%) IIIIII 32 0
## [numeric] min < med < max: 6 : 7 (21.9%) IIII (100.0%) (0.0%)
## 4 < 6 < 8 8 : 14 (43.8%) IIIIIIII
## IQR (CV) : 4 (0.3)
##
## 3 disp Mean (sd) : 230.7 (123.9) 27 distinct values : 32 0
## [numeric] min < med < max: . : (100.0%) (0.0%)
## 71.1 < 196.3 < 472 : : : : : :
## IQR (CV) : 205.2 (0.5) : : : : : : .
## : : : . : : : . :
##
## 4 hp Mean (sd) : 146.7 (68.6) 22 distinct values . : 32 0
## [numeric] min < med < max: : : (100.0%) (0.0%)
## 52 < 123 < 335 : : : .
## IQR (CV) : 83.5 (0.5) : : : :
## : : : : . .
##
## 5 drat Mean (sd) : 3.6 (0.5) 22 distinct values : 32 0
## [numeric] min < med < max: : : (100.0%) (0.0%)
## 2.8 < 3.7 < 4.9 : : .
## IQR (CV) : 0.8 (0.1) . : : :
## : : : : .
##
## 6 wt Mean (sd) : 3.2 (1) 29 distinct values : 32 0
## [numeric] min < med < max: : : (100.0%) (0.0%)
## 1.5 < 3.3 < 5.4 : :
## IQR (CV) : 1 (0.3) : : : : : .
## : : : : : . :
##
## 7 qsec Mean (sd) : 17.8 (1.8) 30 distinct values : 32 0
## [numeric] min < med < max: : (100.0%) (0.0%)
## 14.5 < 17.7 < 22.9 : :
## IQR (CV) : 2 (0.1) . : : : :
## : : : : : : : .
##
## 8 vs Min : 0 0 : 18 (56.2%) IIIIIIIIIII 32 0
## [numeric] Mean : 0.4 1 : 14 (43.8%) IIIIIIII (100.0%) (0.0%)
## Max : 1
##
## 9 am Min : 0 0 : 19 (59.4%) IIIIIIIIIII 32 0
## [numeric] Mean : 0.4 1 : 13 (40.6%) IIIIIIII (100.0%) (0.0%)
## Max : 1
##
## 10 gear Mean (sd) : 3.7 (0.7) 3 : 15 (46.9%) IIIIIIIII 32 0
## [numeric] min < med < max: 4 : 12 (37.5%) IIIIIII (100.0%) (0.0%)
## 3 < 4 < 5 5 : 5 (15.6%) III
## IQR (CV) : 1 (0.2)
##
## 11 carb Mean (sd) : 2.8 (1.6) 1 : 7 (21.9%) IIII 32 0
## [numeric] min < med < max: 2 : 10 (31.2%) IIIIII (100.0%) (0.0%)
## 1 < 2 < 8 3 : 3 ( 9.4%) I
## IQR (CV) : 2 (0.6) 4 : 10 (31.2%) IIIIII
## 6 : 1 ( 3.1%)
## 8 : 1 ( 3.1%)
## ----------------------------------------------------------------------------------------------------------| Characteristic | N = 321 |
|---|---|
| mpg | 19.2 (15.4, 22.8) |
| cyl | |
| 4 | 11 (34%) |
| 6 | 7 (22%) |
| 8 | 14 (44%) |
| disp | 196 (121, 334) |
| hp | 123 (96, 180) |
| drat | 3.70 (3.08, 3.92) |
| wt | 3.33 (2.54, 3.65) |
| qsec | 17.71 (16.89, 18.90) |
| vs | 14 (44%) |
| am | 13 (41%) |
| gear | |
| 3 | 15 (47%) |
| 4 | 12 (38%) |
| 5 | 5 (16%) |
| carb | |
| 1 | 7 (22%) |
| 2 | 10 (31%) |
| 3 | 3 (9.4%) |
| 4 | 10 (31%) |
| 6 | 1 (3.1%) |
| 8 | 1 (3.1%) |
| 1 Median (Q1, Q3); n (%) | |
b. Untersuche die Struktur der fehlenden Werte in mtcars.
## # A tibble: 11 × 3
## variable n_miss pct_miss
## <chr> <int> <num>
## 1 mpg 0 0
## 2 cyl 0 0
## 3 disp 0 0
## 4 hp 0 0
## 5 drat 0 0
## 6 wt 0 0
## 7 qsec 0 0
## 8 vs 0 0
## 9 am 0 0
## 10 gear 0 0
## 11 carb 0 0## rows columns discrete_columns continuous_columns
## 1 32 11 0 11
## all_missing_columns total_missing_values complete_rows
## 1 0 0 32
## total_observations memory_usage
## 1 352 5928## Descriptions
## 1 Sample size (nrow)
## 2 No. of variables (ncol)
## 3 No. of numeric/interger variables
## 4 No. of factor variables
## 5 No. of text variables
## 6 No. of logical variables
## 7 No. of identifier variables
## 8 No. of date variables
## 9 No. of zero variance variables (uniform)
## 10 %. of variables having complete cases
## 11 %. of variables having >0% and <50% missing cases
## 12 %. of variables having >=50% and <90% missing cases
## 13 %. of variables having >=90% missing cases
## Value
## 1 32
## 2 11
## 3 11
## 4 0
## 5 0
## 6 0
## 7 0
## 8 0
## 9 0
## 10 100% (11)
## 11 0% (0)
## 12 0% (0)
## 13 0% (0)
c. Erstelle einen automatisierten EDA-Report für mtcars!
dlookr::describe(mtcars)
DataExplorer::create_report(mtcars)
8.5 Kapitel 5: Datenanalyse
Um die lineare Regression zu verstehen, müssen wir keine komplizierten Daten laden. Nehmen wir an, du bist Marktanalyst und dein Kunde ist die Produktionsfirma einer Serie namens „Breaking Thrones”. Die Produktionsfirma möchte wissen, wie die Zuschauer der Serie die letzte Folge beurteilen. Du führst eine Umfrage durch und fragst die Teilnehmenden, wie zufrieden sie mit dem Staffelfinale waren, sowie nach einigen soziodemografischen Merkmalen. Hier ist dein Codebuch:
| Variable | Beschreibung |
|---|---|
| id | Die ID der befragten Person |
| satisfaction | Die Antwort auf die Frage „Wie zufrieden waren Sie mit der letzten Folge von Breaking Thrones?“, wobei 0 = vollständig unzufrieden und 10 = vollständig zufrieden |
| age | Das Alter der befragten Person |
| female | Das Geschlecht der befragten Person, wobei 0 = Männlich, 1 = Weiblich |
Generieren wir die Daten:
# Seed für Reproduzierbarkeit setzen
set.seed(123)
# Daten generieren
final_BT <- data.frame(
id = c(1:10),
satisfaction = round(rnorm(10, mean = 6, sd = 2.5)),
age = round(rnorm(10, mean = 25, sd = 5)),
female = rbinom(10, 1, 0.5)
)
# Dataframe ausgeben
print(final_BT)## id satisfaction age female
## 1 1 5 31 0
## 2 2 5 27 0
## 3 3 10 27 0
## 4 4 6 26 0
## 5 5 6 22 0
## 6 6 10 34 0
## 7 7 7 27 0
## 8 8 3 15 0
## 9 9 4 29 0
## 10 10 5 23 18.5.1 Übung 1: Lineare Regression mit zwei Variablen
Du möchtest wissen, ob das Alter einen Einfluss auf die Zufriedenheit mit der letzten Folge hat. Du führst eine lineare Regression durch.
a. Berechne \(\beta_0\) und \(\beta_1\) von Hand.
# Kovarianz berechnen
cov <- sum((final_BT$age - mean(final_BT$age)) *
(final_BT$satisfaction - mean(final_BT$satisfaction)))
# Varianz berechnen
var <- sum((final_BT$age - mean(final_BT$age))^2)
# beta_1 berechnen
beta_1 <- cov/var
# beta_1 ausgeben
print(beta_1)## [1] 0.2466586# beta_0 berechnen
beta_0 <- mean(final_BT$satisfaction) - (beta_1 * mean(final_BT$age))
# Beide ausgeben
print(beta_0)## [1] -0.3377886## [1] 0.2466586b. Berechne \(\beta_0\) und \(\beta_1\) automatisch mit R.
##
## Call:
## lm(formula = satisfaction ~ age, data = final_BT)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8153 -1.0820 -0.2053 0.8530 3.6780
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.3378 3.4796 -0.097 0.9251
## age 0.2467 0.1310 1.883 0.0964 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.058 on 8 degrees of freedom
## Multiple R-squared: 0.3072, Adjusted R-squared: 0.2206
## F-statistic: 3.547 on 1 and 8 DF, p-value: 0.0964c. Interpretiere alle Größen deines Ergebnisses: Standardfehler, t-Statistik, p-Wert, Konfidenzintervalle und das \(R^2\).
d. Prüfe auf einflussreiche Ausreißer.
# Cook's Distance mit einer eingebauten Funktion berechnen
final_BT$cooks_distance <- cooks.distance(m1)
# Plotten
ggplot(final_BT, aes(x = age, y = cooks_distance)) +
geom_point(colour = "darkgreen", size = 3, alpha = 0.5) +
labs(y = "Cook's Distance", x = "Unabhängige Variable") +
geom_hline(yintercept = 1, linetype = "dashed") +
theme_bw()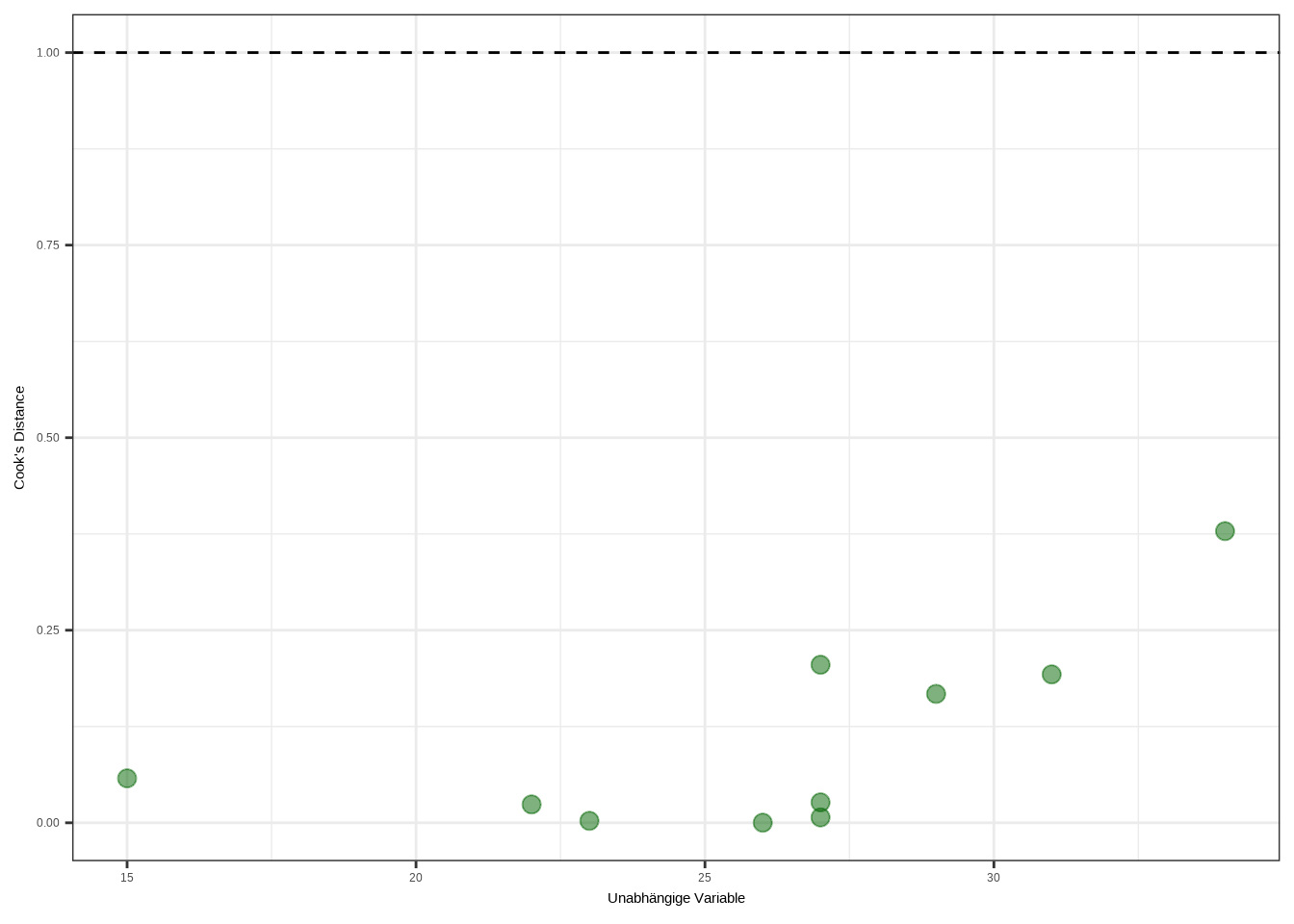
8.5.2 Übung 2: Multivariate Regression
a. Füge die Variable female zu deiner Regression hinzu.
##
## Call:
## lm(formula = satisfaction ~ age + female, data = final_BT)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8401 -1.1312 -0.0574 0.8001 3.6435
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.1712 3.8481 -0.044 0.966
## age 0.2418 0.1429 1.692 0.134
## female -0.3895 2.3662 -0.165 0.874
##
## Residual standard error: 2.196 on 7 degrees of freedom
## Multiple R-squared: 0.3099, Adjusted R-squared: 0.1127
## F-statistic: 1.571 on 2 and 7 DF, p-value: 0.2731b. Interpretiere die Ausgabe. Was hat sich verändert? Was ist gleich geblieben?
c. Erstelle einen Interaktionseffekt zwischen age und female und interpretiere ihn!
##
## Call:
## lm(formula = satisfaction ~ age + female + age:female, data = final_BT)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8401 -1.1312 -0.0574 0.8001 3.6435
##
## Coefficients: (1 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.1712 3.8481 -0.044 0.966
## age 0.2418 0.1429 1.692 0.134
## female -0.3895 2.3662 -0.165 0.874
## age:female NA NA NA NA
##
## Residual standard error: 2.196 on 7 degrees of freedom
## Multiple R-squared: 0.3099, Adjusted R-squared: 0.1127
## F-statistic: 1.571 on 2 and 7 DF, p-value: 0.2731d. Plotte die Interaktion und gestalte den Plot ansprechend.
plot_model(m2, type = "int") +
scale_x_continuous(breaks = seq(0, 60, 1)) +
labs(title = "Zusammenhang von Alter und Geschlecht auf die Zufriedenheit mit BT.",
x = "Alter",
y = "Zufriedenheit") +
scale_color_manual(
values = c("red", "blue"),
labels = c("Weiblich", "Männlich")
) +
theme_sjplot() +
theme(legend.position = "bottom",
legend.title = element_blank())## Warning in predict.lm(model, newdata = data_grid, type =
## "response", se.fit = se, : prediction from rank-deficient
## fit; attr(*, "non-estim") has doubtful cases## Scale for colour is already present.
## Adding another scale for colour, which will replace the
## existing scale.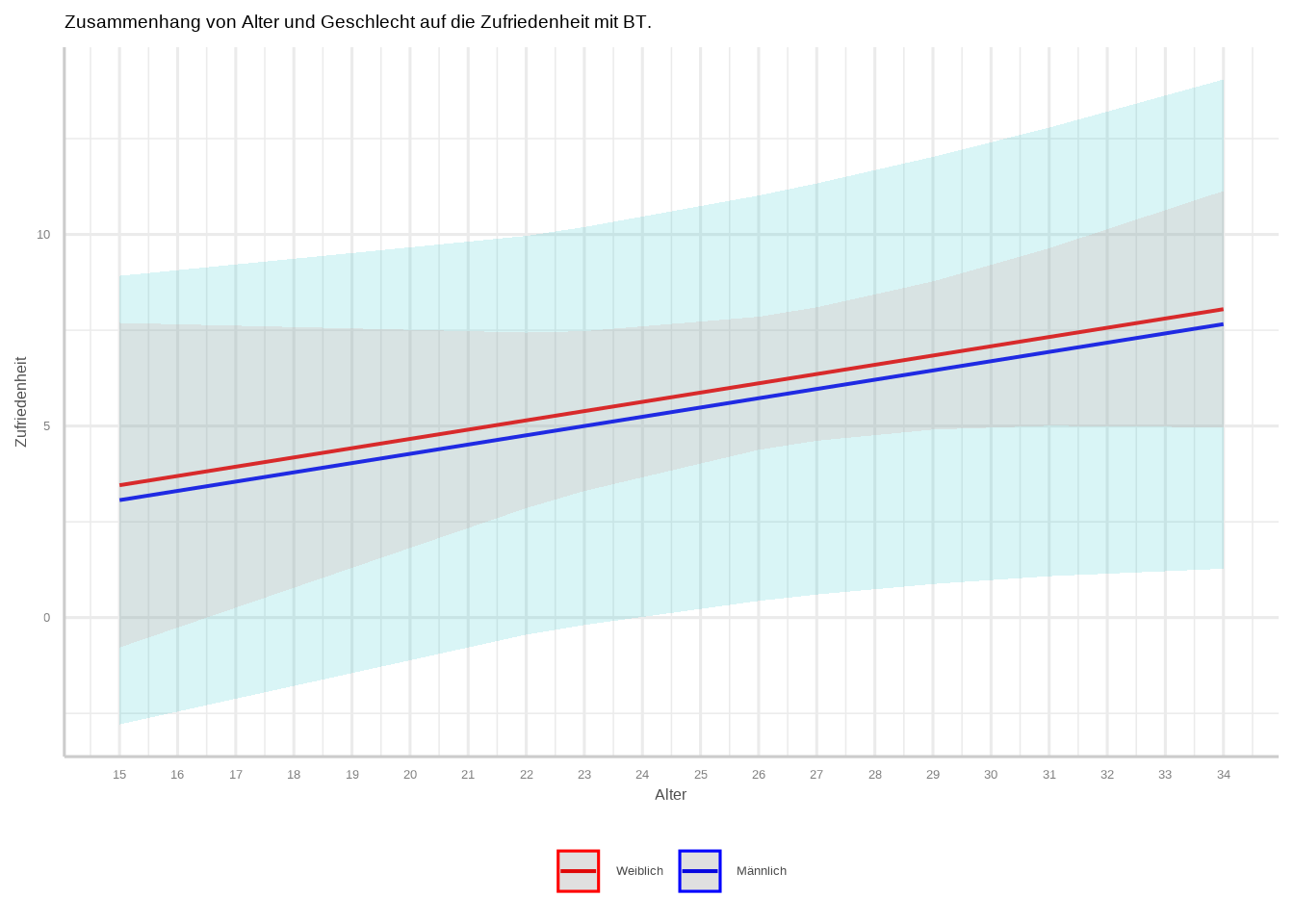
8.6 Kapitel 6: Schleifen und Funktionen
8.6.1 Übung 1: Eine Schleife schreiben
Schreibe eine for-Schleife, die das Quadrat jeder Zahl von 1 bis 10 ausgibt.
# Objekt für einen besseren Arbeitsablauf zuweisen
number <- 10
# Die Schleife
for (i in 1:number) {
print(i^2)
}## [1] 1
## [1] 4
## [1] 9
## [1] 16
## [1] 25
## [1] 36
## [1] 49
## [1] 64
## [1] 81
## [1] 1008.6.2 Übung 2: Eine Funktion schreiben
Schreibe eine Funktion, die den Input x nimmt und ihn quadriert:
8.6.3 Übung 3: Die Mitternachtsformel
Das ist die Mitternachtsformel, aufgeteilt in zwei Gleichungen:
\(x_{1,2} = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}\)
Schreibe eine Funktion für die Mitternachtsformel, sodass die Ausgabe \(x_1\) und \(x_2\) sind. Teste sie mit a = 2, b = -6, c = -8.
Hinweis: Du musst die Formel in zwei Gleichungen mit zwei Ausgaben aufteilen.